阅读:0
听报道
文 | 张江
1.层级
Hierarchy这个词来源于希腊语的hierarchia, 意思是“大祭司的规则”,表达了一种分明的等级性。它是对事物进行分门别类的一种方法,即用高低、同级别这样的关系来对事物做出划分。用数学的语言来讲,所谓的层级,就是指在我们所讨论的事物集合上定义了一种偏序关系。这种偏序关系总是可以用一种树结构来进行表示,例如:
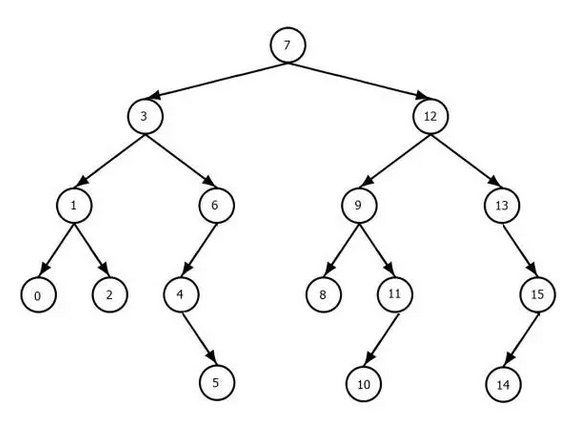
自然界存在着大量的层级关系。比如,高低就能构成一种层次。住在楼上的人就比楼下的人位于更高的层级。再比如,尺度也构成了层级。比如,我们说人体是由不同的小尺度器官组成的,而器官又是由小尺度大量的细胞组成的,而细胞是由更小尺度的分子构成的……。泛化和抽象是人类语言中的层次,比如:“动物”就是一个高高在上的抽象的层级,“鸟类”则是一个更具体的层次,“麻雀”则是更具体的概念。
2.深度与层级
下面,我们来说一说深度学习。大自然和人工系统中这些形形色色的层级性会反映到我们的数据中,这就迫使我们能够读懂层级性的数据。于是,深度学习技术应运而生,它通过加深神经网络层次,从而应付数据中的层级性。从对卷积神经网络的剖析来看,不同层次的神经元实际上是在不同尺度上提取特征。例如,如果我们用大量的图片训练了一个可以对动物进行分类的深度神经网络,那么该网络就会抽取数据之中的多尺度(层次)信息。
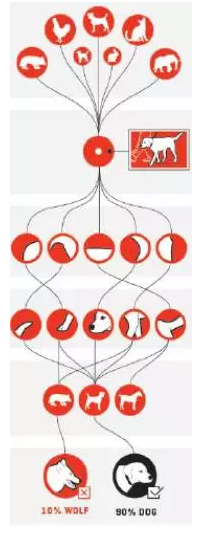
上图是一个深层卷积神经网络,信息从上到下流动。我们喂给这个网络大量的动物图片,网络的低层就会提取出局部边缘的信息,高一层则会提炼动物的腿、脸等更大范围的信息,而到了最高层,则网络提取的就是整个物体的信息。所以,神经网络从低到高刚好能够提取图片数据中从低到高(从局部到整体)的多层次信息。对多尺度层级结构的提取才使得深度学习神经网络可以得到很好的效果。
3.LSTM
与图片不同的是,在类似于自然语言这样的序列信息中,存在着概念或时间尺度上的层级性。比如:“大自然和人工系统中这些形形色色的层级性会反映到我们的数据中”这句话。在最高层次上,这句话表达的是“层级性会反映到数据中”这个概念,然而为了修饰“层级性”,我们加入了低层次的“大自然和人工系统中”以及“形形色色的”这些概念。所以,整个句子也可以被分解为一个树状结构,最底层的叶节点是单词,每个子树都是一个动宾短语。
面对这种序列的层级性,虽然我们也可以用卷积神经网络来处理(参看李嫣然的《自然语言处理中的卷积神经网络》课程,见文末),但是更多地则是使用循环神经网络(Recurrent Neural Network,RNN)。由于网络中环路的存在,这就为信息存储提供了方便。然而,经典的RNN存在着梯度消失、梯度爆炸的信息,于是人们发明了LSTM(Long Short Term Memory)。LSTM对神经网络的最大贡献就是引入了门(Gate)电路。
我们知道,对于神经网络来说,无论它的结构多复杂,其基本单元无非是这样的McCllotch Pitts神经元:
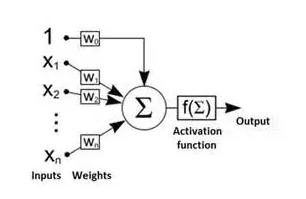
信号之间的组合都是线性的加合关系。而LSTM中则引入了信号之间非线性的相互作用关系,如图:
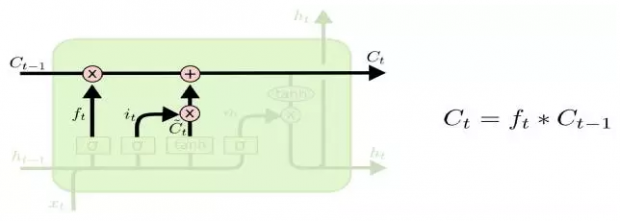
图中C(t-1)这个信号与f(t)这个信号被乘到了一起(严格讲,由于信号都是向量,*是“按位乘积”,即element-wised product),同样i(t)与C(t)~也是乘到了一起。
这种乘积作用其实是在做控制,就好像经典计算机中的逻辑门电路一样,f(t)就是控制信号。比如如果f(t)=0,则C(t)的更新就与C(t-1)无关了,于是我们就忘掉了C(t-1)的信息,而当f(t)趋近于1,同时i(t)=0的时候,则C(t-1)的状态就会影响C(t)了,于是我们的单元可以用C(t)这个信号将信息存储住。
其实,这种门电路是在提升神经通路信号的层次。因为,在经典的神经网络中,所有的信号都是同一层次的,它们的相互交织完全靠的是加权求和。信号被当成了数据在网络中传递来、传递去。传递通路完全被网络结构控制。
但是,引入了LSTM的逻辑门之后,信号就不仅仅是信号了,它也成为了系统控制的一部分。比如f(t)就不再是普通的数据或信号,它还能够控制系统是否要存储C(t-1)。这就好像计算机中的代码与普通数据的区别。一般的数据只能被被动地处理,而一旦某些数据成为了代码,它就能够主动地操控整个机器。
因此,当神经网络在学习阶段修改连边之后,LSTM就知道在正确的时候打开f(t)这种开关,从而相当于改变了神经通路,以及信号在通路中的走向。换句话说,LSTM由于引入了门电路,它就拥有了一定程度上的“自编程”能力。
本来同是数据或信号,现在有了程序(控制信号)和数据(一般信号)的分别,我们也将这种分别理解为层次。程序(控制信号)比数据(普通信号)高一个级别。
4.Attenion&Memory
在做机器翻译的时候,人们发现了另一种改善LSTM或一般RNN的方法,这就是引入注意力机制。生物体的注意力机制是为了将我们有限的认知资源集中起来放到最重要的地方上。LSTM的注意力机制则是会根据所处环境动态地分配权重(相当于注意力资源)到相应的记忆单元上面。
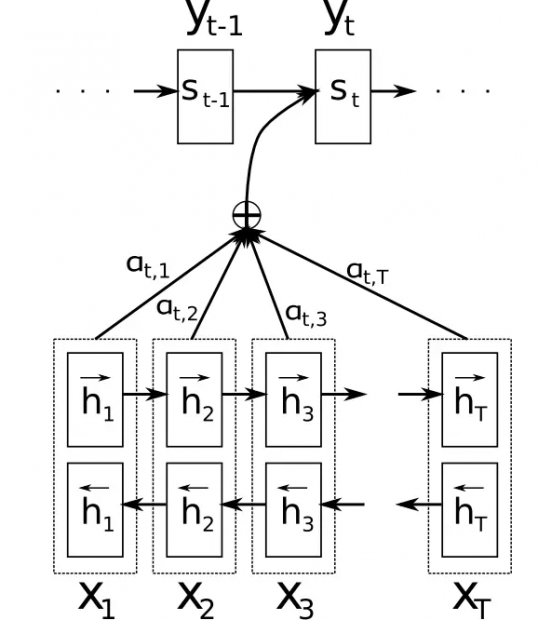
如图,h1,是过往时刻1,2,...,T的LSTM隐单元状态,a(t,1),a(t,2)...a(t,T)是t时刻的注意力分配权重。有了这种机制,LSTM就可以在不同时刻依据上下文(读入的数据和存储在cell中的数据)的不同而分配认知资源到不同的记忆h1,h2,...上面。
后来,Google的工程师又提出了神经图灵机(Neural Turing Machine,NTM)模型。现在看来,这个NTM无非就是引入了存储单元,同时运用类似于注意力的机制来从这个存储区域提取或者写入信息。
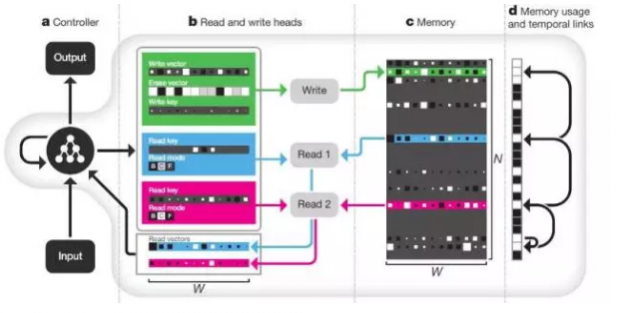
这里的Read and write heads就是一种动态地调节权重的机制,与注意力机制相仿。而Memeory就是外部存储器,读写头可以在这里写入、读出信息。
5.万法归一
其实,总体来看,无论是早期提出来的LSTM还是最近比较时髦的NTM或者Memory机制,它们都有着异曲同工的作用,这就是将信号分成了控制和普通信号两种。
在LSTM中,门电路的引入使得控制门的信号成为了控制信号,而细胞的状态C(t)则是被操作的信号。在Attention机制中,Attention动态分配的权重就是控制信号,它的作用与LSTM中输入给门节点的控制信号是同样的。Attention访问的LSTM的过往状态其实就是一种被操作信号。在NTM中,读写头则充当了控制的作用,内存为被操作信号。
同样的,实际上LSTM也可以看作是一种广泛意义上的带有存储单元的机器。其中,每个元胞(Cell)的状态组合就构成了存储器,而门(forget gate,input gate等)就相当于Attention。只不过,NTM相比较Attention机制以及LSTM来说则更加灵活得多。
总结来看,人们为了应付序列信息中的多层次性,就不得不让神经网络中的信号被分割成了两个层次,一个起到控制作用,一个起到被操作的数据作用。
如果我们站在神经元单元的角度来说,其实这种层级的划分就体现为把神经单元区分出了快变量和慢变量这两种,存储器中的神经元就是慢变量,而控制器(门,读写头)中的神经元就是快变量。只有当快慢两种变量的数目和分布达到一种恰到好处的配比的时候,我们的神经机器才能表现优秀。才能应付待处理数据之中时间上的层级性。
然而,这种最佳匹配究竟应该是什么样的呢?也许,统计物理可以给我们带来一定的启发。
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}