阅读:0
听报道
文 | 甄慧玲
前导语:“你有一个苹果,我有一个苹果,彼此交换,我们每个人仍有一个苹果;你有一个思想,我有一个思想,彼此交换,我们每个人就有两种思想。”这是但丁的名句。今天,在深度学习,启发式算法和统计物理的共同促进下,我们说,你有一个思想,我有一个思想,我们一起发酵,会有n个思想!
什么是『层级结构』呢?
简单来理解,就是我们认为training sets中的数据不仅仅是有平面上的clusters的,还有空间结构上的区别!例如,同时在training sets中出现了“1”和“数字”,同时出现了“猫”和“动物”。纵观各个论文,人们一开始对这个问题的处理,是不断的增加神经网络的层数,并且认为每加深一层,就可以提取出更高level的特征(因此,从2015年的highway networks和residual networks开始,有越来越多的文章要训练越来越深的神经网络)。但是,这对于解决层级结构的问题还远远不够!例如,如果training sets的数据是在一个双曲平面上的,只是简单的增加网络层数显然解决不了问题的本质!
解决层级结构所带来的问题,当然要从『网络结构』和『学习算法』两方面来双管齐下。
一方面,由于不短的时间内我的工作都集中在神经网络的『学习』和『记忆』上,在我们的研究结果中,人们常提到的『记忆(memory)』和『注意力(attention)』也是有层级结构的!另一方面,根据香港城市大学张青富老师(感谢张老师!!张老师也是启发式算法中MOEA/D算法的提出者。)的推荐,在启发式算法或者组合优化问题的研究中常有“1+1>2”的trick,而这个trick其实是和我们之前分享过的curriculum learning以及baby step“不谋而合”:明明看起来只是将原目标函数分成了几个循环步骤,但是效果却明显变好!在我看来,无论是在深度学习的网络模型中,还是在记忆的空间结构中,或者是在启发式优化算法以及population的“合作”问题上,它们对于“层级”都有异曲同工的意味。
本篇内容将尝试围绕“层级结构”串联起“网络结构和记忆”,“学习”以及“启发式算法”三个方面的内容,看看明明那么不同的内容在这个问题上是如何“异曲同工”。
Hierarchical在网络和记忆中的最新结果
主要涉及到下面三篇文章:
1. Deep and Hierarchical Implicit Models (D. Blei), arxiv: 1702.08896v1 (2017/3/2)
2. Mean-field message-passing equations in the Hopfield model and its generalizations (M. Mezard) arxiv: 1608.01558v2 (2016/8/26)
3. Using Fast Weights to Attend to the Recent Past (J. Hinton) arxiv: 1610.06258v2 (2016/10/28)
今年3月2日D.Blei在arxiv上的最新文章”Deep and Hierarchical Implicit Models (D. Blei), arxiv: 1702.08896v1“就恰好讨论到了这一点。这篇文章主要提出了两种模型,分别是图1(右)hierarchical implicit model和图2(右)它对应的deep版本。
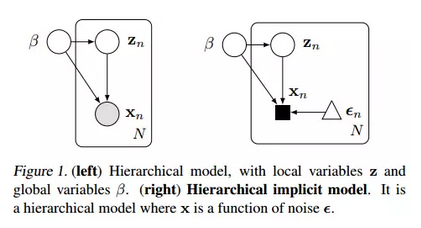
事实上,图1(左)就已经是传统的hierarchical networks了:x是我们能观察到的量(output),β和z都是隐变量,区别是β是全局隐变量,而z是局部的。全局和局部的区别我们可以理解为:β会影响z(例如多层feedforward神经网络的第一层会影响第二层)但是反过来不会。显然,这样的网络并不等同于传统的深度网络,因为即使是在第二层的z依然对x有影响(而且这种影响显然不是诸如fine-tuning这样的过程可以表现的)。对于这样的模型,目标函数显然要用KL熵:
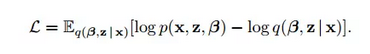
相应的算法当然是随机gradient descent (这已然成为套路)
那本文模型的特点是x还受到噪声的影响!为什么要引入噪声?
我们曾经分析过Bengio去年12月份的文章关于plug-play generative networks,里面最成功的一点就是引入了噪声导致样本的多样性。这个模型对应的deep版本在图2(右)。
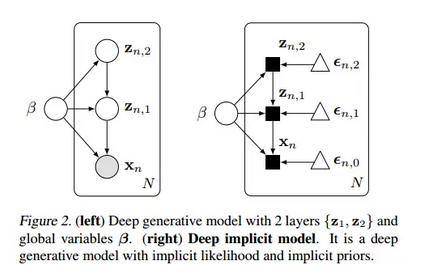
由于引入了噪声,在练算法上也与之前的稍有不同:引入了ratio parameter r,这里star表示要求表达式的最小值。
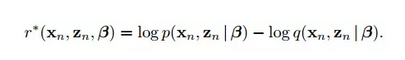
更重要的是,文章的后半部分借助这个模型改进了现在风头正劲的GAN,也就是在generative model中加入了noise和hierarchical的bayesian GAN, 我们发现,这样的改进让GAN在诸多数据集中test error都几乎最小。
给我们带来的insights是:首先我们要承认数据中是有可能有层级结构的,而这种层级结构会让模型更好的了解数据,这种了解不是深度网络仅依靠深就可以实现的!
那么这样的结构在其他方面会有体现吗?事实上,在2016年冬天关于“记忆”的各个文章中都有所体现,而且这样的结构,是有物理意义的!例如,我们接下来要分析的文章:Mean-field message-passing equations in the Hopfield model and its generalizations (M. Mezard) arxiv: 1608.01558v2 (2016/8/26) 。文章作者可能很多做深度学习的人不熟悉,其实他是巴黎高师的校长,也是统计物理方向的superstar之一。这篇文章通篇都是在用统计物理中的“近似消息传递算法”(Approximate Message Passing,AMP或者TAP,T是2016年诺贝尔物理学奖得住Thouless的名字简称)来分析联想记忆网络。但是在文章的第五部分,他将传统的pattern ξ分解成了两个矩阵的乘积:
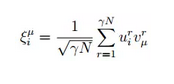
他认为,pattern是会有叠加的,也就是,还会有一组向量v(不妨假设这里v是相互独立的)来表示原始pattern的特征,而u则是这组pattern的线性组合的系数!
这意味着什么呢?意味着pattern ξ是可以被分解的,而分解出来的元素则是更基本的level的pattern !在这样的假设下,作者得出了另外的一组方程:
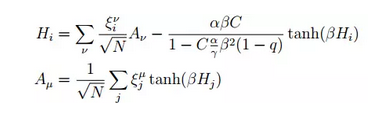
如果熟悉统计物理在RBM和Hopfield网络上的结论的话,就可以发现:当把RBM的连接权重W分解成不同的pattern的乘积,则在形式上对应了Hopfield网络(当然也要让visible和hidden neurons的外场全是0);如果把Hopfield网络中pattern继续分解,则在形式上对应了上面的模型。而这三个模型在AMP算法的表达式上差别仅在于Hi的第二项(也就是所说的Onsager项)的系数!
这又意味着什么?这篇文章给出了attention和memory的统计物理上的解释!attention和memory不仅在人们已知的capacity上有差别,它们在物理上的差别关键是Onsager项的系数不同,但是naive mean-field系数是相同的!换句话说,当我们考虑到记忆的层级结构时,不同的分层影响的是二阶或者更高阶的作用,但是不改变线性关系!所以,当考虑到层级结构对网络的影响时,对模型本身(无论是学习还是记忆)的影响都是非线性的,也就是当不断的考虑分层时,对最后效果的改变远远大于层级数的改变!
在“记忆的层级结构”这个问题上同样意识到这件事的,还有Hinton去年的文章:Using Fast Weights to Attend to the Recent Past (J. Hinton) arxiv: 1610.06258v2 (2016/10/28)。当然,Hinton用的是完全不同于Mezard的思路。
Hinton在这篇文章中提出了fast asssociated memory(或者叫fast weight),其实就是在hidden layer的连接之间引入了A(t):
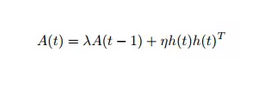
换句话说:在一个常规的RNN的迭代过程中,本来是要将hidden layer的h(t)迭代n次(从h^0到h^(n-1)),现在呢,是将h(0)迭代s次(从h(0,0)到h(0,s-1)),而后再将h(1)迭代s次(从h(1,0)到h(1,s-1),其中h(1,0)的初值由h(0,s-1)给出),以此类推……具体的迭代公式如下:
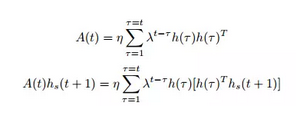
这个过程是不是似曾相识?!再来看看Mezard是怎么做的:他将本来的associative memory中的pattern ξ分解成了u和v,其中v被当成pattern的pattern,u被当成了线性组合的系数。那Hinton这篇文章呢?他将隐层的连接矩阵h(t)分解,导致从h(0)到h(n-1)的n次分解变成了h(0,0),……,h(0,s-1),h(1,0),……,h(1,s-1),……h(n-1,s-1)的n*s次分解!从统计物理的角度来理解,如果我们写出fast weight所对应的AMP方程,每一个A(t)会且只会影响Onsager项的系数,因此,虽然计算的数量级从n变成了n*s,但对效果的影响确实远大于此(至少是n*s的平方!)
从实验上也确实是这样!例如下图:fast weight在n=20的时候,对比普通的RNN,test error从62.11%降低到了1.81%,而参数更多的lstm却只降低到了60.81%!当n=50或者更高的时候,fast weight的test error干脆降低到了0!
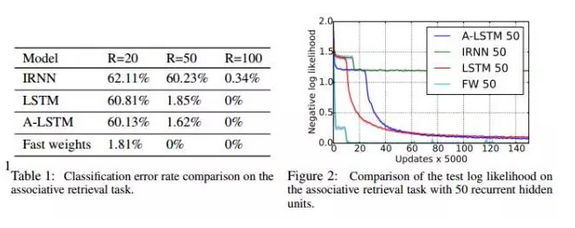
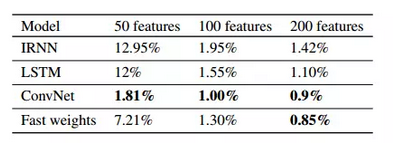
而对比CNN,在特征是200的时候,fast weight的test error从0.9%降低到0.85%,效果依然好于rnn和lstm ! 当然,在特征数较少的时候,优势不明显,这当然是很好理解的:给出一个极端情况,如果你只有2个feature,这种hierarchical的假设只会带来overfitting (∩_∩) (∩_∩)!
神经网络的泛化学习本质与hierarchical的关系
不仅在记忆和网络结构中,会有hierarchical的存在,下面我们会说,在2017年初关于神经网络学习本质的“Bengio兄弟之争”论文中,依然可以从这个角度理解!
去年11月份,Bengio的弟弟(目前在Google Brain)提交了这样一篇文章:Understanding deep learning requires rethinking generalization (S. Bengio) arxiv: 1611.03530v1。当然,这篇文章是从泛化generalization的角度来说的。
这篇文章本身是想解释为什么大规模神经网络在泛化这个问题上表现的好。借助随机梯度算法,作者在CIFAR10和ImageNet上正式了即使单独的使用标签随机化而不改变模型的大小和参数等易燃可以让模型的泛化大幅度提升!原因是,他们认为CNN的泛化效果好是因为更容易拟合随机标记,也就是说,网络是通过记忆来学习的(不是通过不断的提取特征)!!
首先,作者通过引入随机数据来证实虽然随着噪声的引入导致训练时间变长,但是网络总是可以让输入和输出相拟合,如下图:

然后,文章也讨论了正则化虽被认为是有助于减小泛化学习的误差,但是对于低测试错误,正则化是不必要的。因此,他们认为,正则化起作用的时候是由于“将可能的假设空间减小到更小的子集”!文章的最后还证明了“存在具有 ReLU 激活和 2n + d 个权重的两层神经网络,其可以表示d维中的大小为n的样本的任何函数”。
引起我们注意的正是文章的后两部分结论,这看起来和统计物理的想法如此相似:正则化不是一直有效,只有将空间减小的时候才有效(其实就是相当于说只有分解了latent parameter而利用分解后的特征来学习的时候才有效!!)至于最后一部分证明,其关键是将input x分解成了x1,……,xn,在空间I1,……,Ib上分别积分!(这就相当于本来是只有n步的计算变成了n*b,有没有在Hinton和Mezard的文章中找到共同点?!)
但是,由于在2017年初Bengio本人提交了这样一篇文章:Deep Nets don't learn via memorization (E. Bengio) 2017, ICLR workshop。这篇文章针对弟弟的结果主要说明:DNN不会记忆!虽然看起来对于每个训练样本,DNN 都能实现完美的分类精度是由于“记住”了样本,但是这仅限于training sets!
他们做了如下的几个实验:随着更多的样本被噪声替代,DNN 需要更多的容量才能达到最高性能。这表明网络能够以更简单的模式,也即更少的参数解释真实数据。
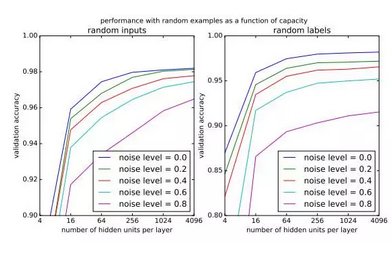
在分析正则化时,他们发现正则化是对随机标签起作用的(这个实验结果是与弟弟的文章相反)。
我们是从统计物理的角度来研究“学习”和“记忆”的,在我看来,虽然他们的结果呈现了一定程度的不同,但是都是对的,也都有不对:
(1)我们不认为DNN可以记住数据(所以并不是通过记忆来学习的!这点上绝对是站哥哥!),但是可以记住的是training sets的不动点!事实上,除非即使忽略数据集的hierarchical的性质,也依然是可以分成若干个cluster(除非你只是训练了全是0或者全是猫,还得计算机认为的一种0的写法或者一种猫,连传统的handwriting都不可以!),而当你在test set上做测试的时候,其实是看测试的sample在哪个不动点的管辖区域内。更具体的结果可以参见文章:Memories as bifurcations: realization by collective dynamics of spiking neurons under stochastic inputs (Neural Networks)。
(2)但是,关于正则化的讨论我们认同弟弟的观点。至于两篇文章出现了不一致在我看来是因为前提不一样:问题的关键是分解!有没有将inputs和weights分解将起到至关重要的作用!因为这意味着是否将hierarchical结构考虑到了里面(从哥哥提交的文章中看,似乎是没有。)。事实上,我们认为这种分解等效于curriculum learning(但是,在curriculum learning 中,是将目标函数分解成若干步骤,这里是将参数或者Inputs分解)。例如:Visualizing and Understanding Curriculum Learning for Long Short-Term Memory Networks中也会有相应的作证!
究竟是hierarchical还是deep在影响着算法的设计
为了佐证“分解”或者“hierarchical”在学习中的作用,我们也推荐如下的两篇关于启发式算法的文章:
(1)An Economics Approach to Hard Computational Problems (Bernardo A. Huberman, HP Senior Fellow and Director). Science.
(2)MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition (Qing-Fu Zhang, City University of Hong Kong) IEEE Trans
第一篇文章很短,原理看起来也很简单:把目标函数f分解成f1和f2,把p(t)分解成:
对应关系是f1对应p1(t),f2对应p2(t)。而后发现无论是在目标函数的优化还是风险估计上,都效果比直接处理f和p(t)效果要好。
如果说这是个例的话,那么第二篇文章也就是张青富老师的文章MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition就更能说明问题一些!这篇文章首次将这种分解的方式应用到了进化问题上。这个算法的关键有两部分:
(1)将一个多目标优化问题分解成不同的子问题,
(2)而且每个子问题的优化信息将通过相邻的子问题得到(有没有想到深度学习中的weights sharing!),从而减小了计算复杂度。
综合上面两篇文章,有没有发现这种处理方式和curriculum learning很像!!不直接处理原始的目标函数,而是处理一个与之相关的一部分,而后,逐渐的过度到原始的(当然,这里只是分成了两步,但其实是可以分成n步的,不过将p(t)同时分解就好)!乍一看,这个似乎和“深度网络究竟是deep还是wide效果好”这个议题相关,换句话说,似乎我们可以理解成:把f分解成的f1……fn分别可以理解成每一层的指标(类似目标函数),所以,逐层提取特征的过程就相当于逐步完成这个组合优化的过程。但是,其实不然!事实上,如果是深度网络逐层提取特征的过程的话,不同层的目标函数不会发生变化!!而这样的过程其实是在考虑优化空间的hierarchical 特征!!根据不同的level或者特性的优化空间,不断的更新目标函数!
但是,这反过来是什么意思呢?明明f1……fn分别是f的一部分,但是分别处理却效果比直接处理要好很多!!这样的现象在统计物理中也是常见的: 例如在文章“Solving the inverse Ising problem by mean-field methods in a clustered phase space with many states”“Inference and learning in sparse systems with multiple states”等解决组合优化问题的时候,都是先将data分成不同的cluster,然后,在每个cluster中逐一求解。同时,他们证实了,用这样的方法来做组合优化是可以得到整个dataset一起处理时得不到的物理现象。当然,cluster忽略了空间结构,当成hierarchical的一个某种程度上的特例来看就好。
那我们可不可以理解成,这就是所谓的“1+1>2”现象呢?也就是我们说的合作问题:深度学习中需要区分开不同的hierarchical来分层训练,组合优化中则需要利用hierarchical来取得更优的最优解!换句话说,在组合优化中将f分解成的f1……fn,恰好是不同的hierarchical的某种指标(诸如目标函数),而整个优化问题是将解空间分成不同的层次分别完成最优。既然如此,深度学习可以借助诸如MOEA/D这类启发式算法来完成训练,启发式算法或者组合优化问题则可以通过构造深度网络或者图模型来利用数据求出最优解!

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}