阅读:0
听报道
原文作者: Christopher Hesse ——2017/2/19
原文链接:
导语
你听说过GAN可以将白马“转化”为斑马,可以积木“转化”为建筑,可以把线条“转化”为猫咪、鞋子、挎包,可以把白天转化为黑夜……
这些都是在基于GAN的框架下实现的图片翻译,这就是pix2pix这篇论文【1】,真的非常值得一读。本文就来给大家讲述一下它背后的原理。
让我们先来看一些例子:
建筑立面标签到建筑的转换
本模型使用“建筑立面标签和建筑立面数据集”训练。在面对一大片空白时,它往往不知道怎么做,但是如果你提供足够的窗户位置信息给它,它往往能产生相当不错的结果。
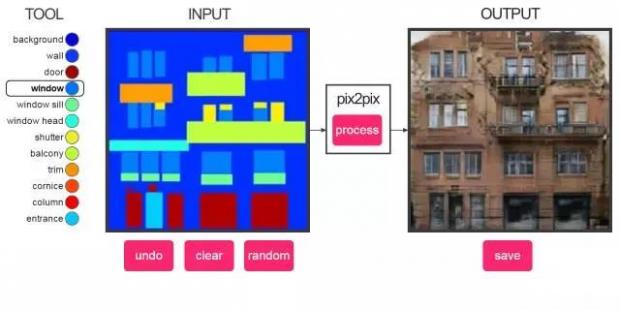
绘制代表“墙”颜色的矩形可以擦除已绘制的对象。我不知道在“建筑立面”中,不同部分的专业术语应该怎么说,所以我就猜着来了。
轮廓到猫的转换
这个模型是使用了大约2000张猫的图片,以及对应的自动生成的轮廓图片来训练的。
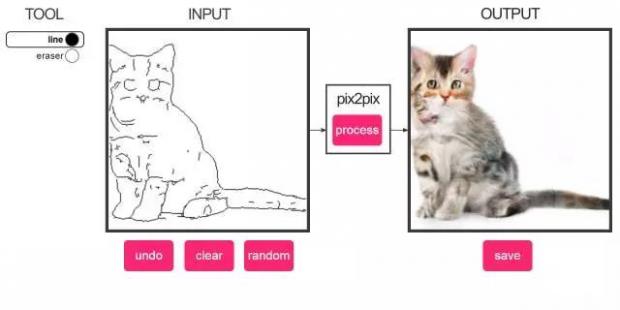
它可以生成一些“类似猫”的物体,有一些生成的图片蛮恐怖的。我印象最深的是这一张“ cat-beholder(怪化猫)”。
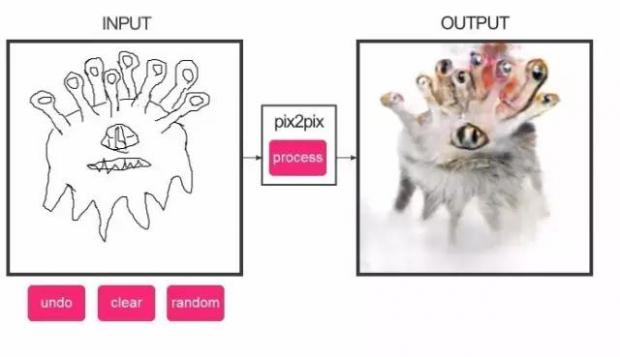
一些图片看起来着实让人心里发毛,很容易注意到,在生成的动物不太对劲时,眼睛是最诡异的部分。我想是因为“轮廓识别”功能并不是很好用,在很多时候,它识别不到图片中猫的眼睛。导致使用图片训练模型的时候,效果并不是那么的好。
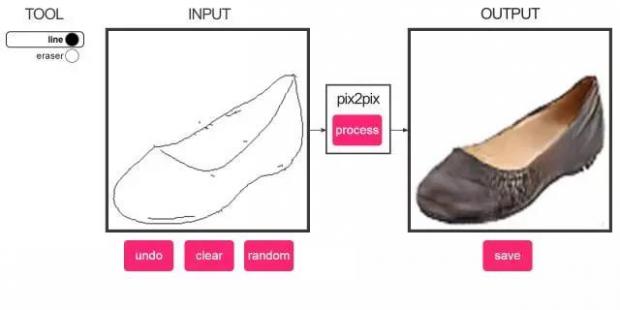
轮廓到鞋子的转换
本模型使用5000张左右的“鞋子图片”和对应自动生成的轮廓图片来训练,这些图片来自于Zappos。如果你真的非常擅长画鞋子的轮廓,你可以尝试设计一些新的款式。记住这个模型是使用真实的鞋子图片来训练的,所以如果你能画出鞋子的3D轮廓,模型将表现的更好。
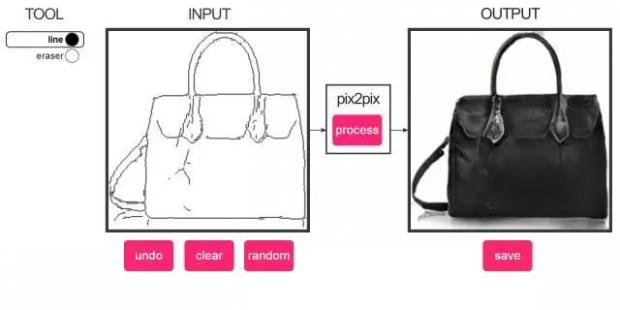
轮廓到手提包的转换
和前面的那个类似,本模型是通过137000张来自亚马逊的手提包图片,以及根据这些图片自动生成的轮廓图来训练的。如果你在这里绘制的是一只鞋而不是一个手提包,你将获得一只有诡异纹理的鞋子。
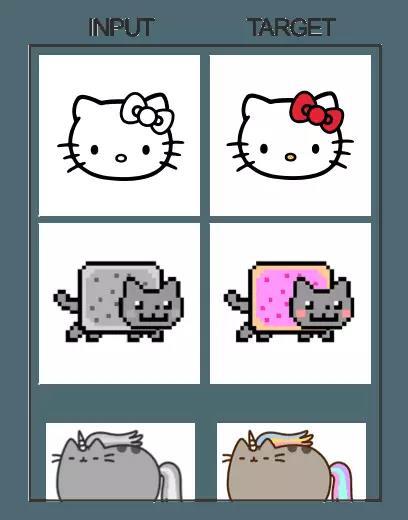
pix2pix的工作原理
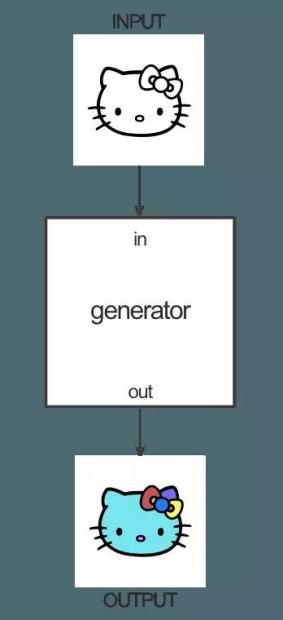
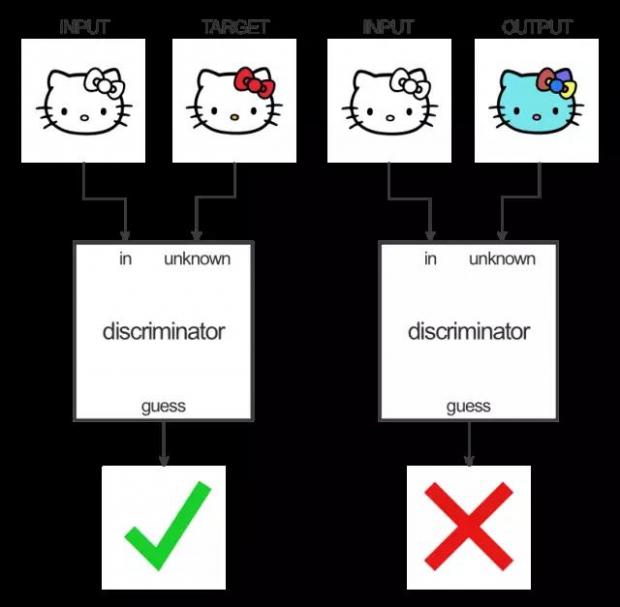
pix2pix使用了一种被称为条件生成对抗网络(cGAN)的技术来学习从输入图像到输出图像的映射。整个网络由两部分构成:生成器和辨别器。生成器将一些图像变换应用到了输入图片上以得到输出图像。辨别器的任务是比较输入图像和一个未知的图像(要么是要翻译的目标图像,要么是从生成器生成的图像)并猜出来它是不是由生成器生成的。
一个例子是我们输入一张黑白图,而目标则是彩色的图,例如:
生成器就是要学习如何将黑白图上色:
辨别器的任务则是比较生成器给的染色和训练数据中实际的染色方案,并指出它们是否有区别。
为什么要费劲这么做呢?因为我们用辨别器的损失函数可以自动学习得到一个生成器,而不需要指定生成器如何工作的细节,这种想法真的非常赞!手动地编码这种转换将会被训练神经网络所取代,那么为什么我们不连损失函数也让机器自动学出来呢?别想太多了!如果真这样了,那么你就可以一边歇着睡大觉了。
下面,就让我们来详细看看这两部分:生成器网络和判别器网络。
生成器:
生成器的任务就是将输入的图像转换成目标图像。在pix2pix中,这是用一种编码-解码器架构来实现的,如图:
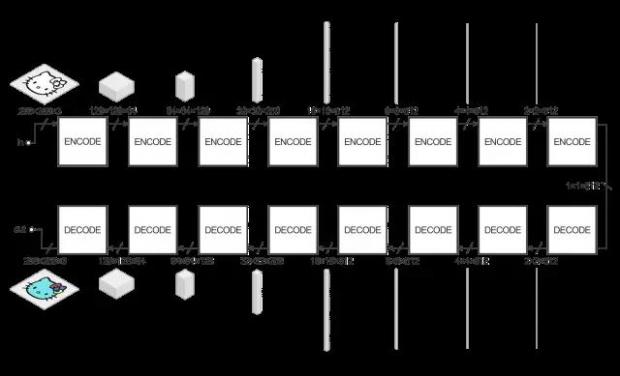
这里面,很多的立方体表达了卷积神经网络的参数张量,下面的数字则是张量的维度。在这个例子中,输入图像是256*256大小3种颜色通道的图像(红、绿、蓝通道,对于黑白图,这三个通道的数值相等),而输出则相同。
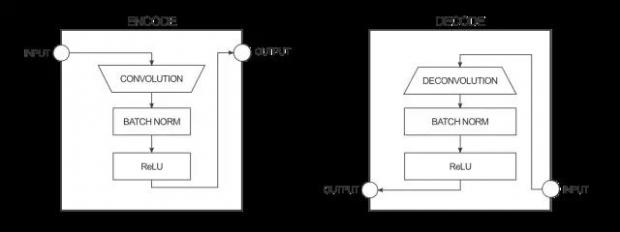
生成器接收输入,并将它用一系列编码器(卷积+激活函数)简化成更小的表示(representation)。这样做的基本想法是我们用最终的编码层可以得到一种对数据更高层次(抽象)的表达。解码器层呢主要做了相反的操作(反卷积deconvolution+激活函数),并将编码层的动作反过来。
为了提高这种图像到图像转换的效率,作者用了一种称为U-Net的方法而不是编码-解码器方法。它们本来是一回事,但是U-Net引入了所谓的“跳跃链接”,以便将编码器层和解码器层直接相连,如图:
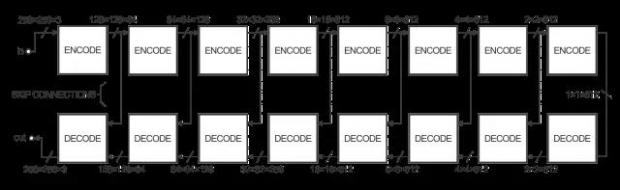
这种跳跃链接可以为网络提供一种省略编码/解码部分的选择,从而当网络真的用不到它们的时候,处理效率就会很快了。
当然,在我们的图示里,我们省略了很多东西,例如一开始的batch norm层,以及中间的dropout单元等。
辨别器:
辨别器的工作就是要区分输入的图片是由生成器生成的还是我们想要的目标图。结构如下图:

这个结构看起来很像生成器的编码器部分的网络,但是它们工作起来的作用却不太一样。辨别器的输出是一个30*30的图像,每一个像素都是0~1的数值,代表了这一部分与目标图像比起来有多像。在pix2pix的执行中,这30*30图像中的每一个像素都对应了输入图像的70*70个块(patch,这些patch会有很多重叠,因为输入图像大小是256*256)。这种架构称为“PatchGAN”。
训练:
训练这个网络需要两步,训练判别器和训练生成器。
要训练判别器,首先要让生成器生成一张输出图片。然后让判别器检查“输入/目标图像对”和“输入/输出图像对”,并计算出两者的“真实程度”。
根据“输入/目标图像对”和“输入/输出图像对”的分类误差,调整判别器的权重值。
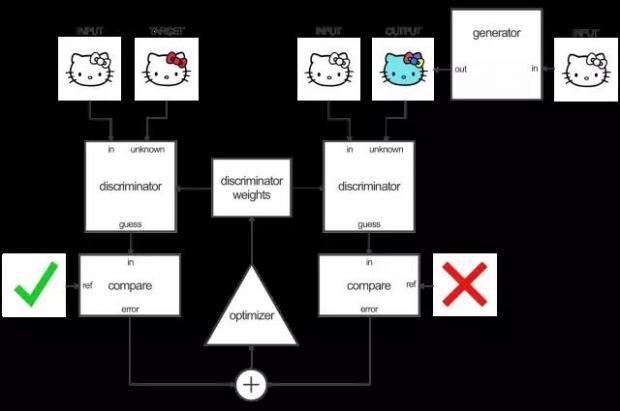
根据判别器的输出调整和生成图片与真实图片的误差,调整生成器的权重值。
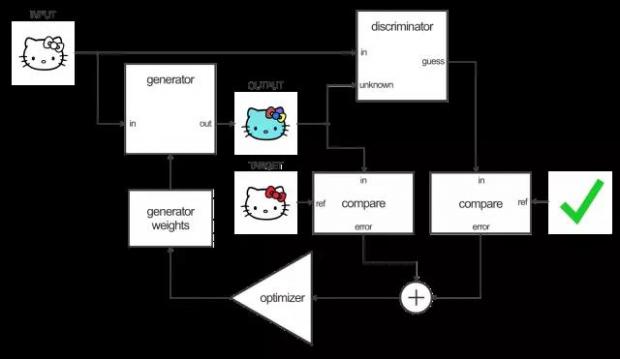
在这里有个聪明的小花招,当你使用判别器来训练你的生成器的时候,实际上你在通过判别器来计算梯度。这意味着判别器同时也会得到改变,你正在训练生成器来打败判别器。
原理就是随着判别器变的更好,生成器也变的更强大。
如果判别器可以很好的工作,同时生成器通过梯度下降,也将映射函数学习的很好,你就可以生成足以乱真的输出了。
“pix2pix-tensorflow”实现
“pix2pix”的算法思想是基于“GAN”的,所以模型都是使用成对的图片来训练的,比如使用:“建筑立面标签图片”和“建筑立面图片”。训练后就可以通过你的“输入图片”来生成“回应图片”。
这些预训练的模型都可以在GitHub上讲数据集的部分找到【2】。这些模型都可以使用“”,在训练结束后导出来。猫的轮廓图片是使用“Holistically-Nested”【3】的轮廓检测程序来实现的,这个功能已经添加到“”中了,并且所有的依赖包都添加到Docker的镜像中去了【4】。
pix2pix-tensorflow是pix2pix的Tensorflow实现。所有的代码都能在gitHub上找到,如果你想在自己的计算机上尝试它,我在这里会给你一些建议。
pix2pix-tensorflow使用的数据格式跟 pix2pix 的格式一样,包含并排显示的输入图像和预期的输出图像。例如:

pix2pix 的论文中已经包含了一些可用的数据集。可以使用 tools/download-dataset.py 脚本来下载这些数据集。
facades 是一个最小最简单的数据集,一般可以从这里开始。
为了对结对图像进行常规训练,你需要指定包含训练图像的目录,以及目标训练目录。目录的参数是 AtoB 或者 BtoA。
python --mode train --output_dir facades_train --max_epochs 200 --input_dir facades/train --which_direction BtoA
测试是通过参数 --mode test 来进行的。你应该使用 --checkpoint 指定检查点,这个需要指向 output_dir 目录,该目录是你之前用 --mode train 参数创建的:
python --mode test --output_dir facades_test --input_dir facades/val --checkpoint facades_train
测试模式将会自行加载一些检查点的配置参数,因此你无需指定 which_direction 参数。
测试运行完毕将输出一个 HTML 文件,位于 facades_test/index.html ,该文件显示 input/output/target 图像集合:

【1】
【2】
【3】
【4】
有关GAN的更多内容请观看如下课程:
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}