阅读:0
听报道

文 | 集智小仙女
现今人工智能概念的火爆到什么程度?
各大科技媒体争相报道关于人工智能的最新消息,AI初创公司的数量不断增长,人工神经网络、深度学习技术时时刻刻都被提及......
我们知道,在人工智能领域,目前应用最广泛的是深度学习技术。而深度学习是基于人工神经网络的。那么问题来了,到底什么是人工神经网络,它到底干嘛了,才让计算机拥有“智能”?
通常来讲,神经网络是一种数学模型,是人们在计算机上构建的模拟生物神经网络的系统,所以又叫作人工神经网络(Artificial Neural Network,即ANN)。
神经网络由大量的神经元节点和节点之间的联系构成。神经元可以起到传递和加工信息的作用,同时也可以通过训练被强化。通过向神经网络输入大量训练数据,改变神经元之间连接的参数,可以让神经网络整体“被训练”而能够拟合出输入输出间的关系。
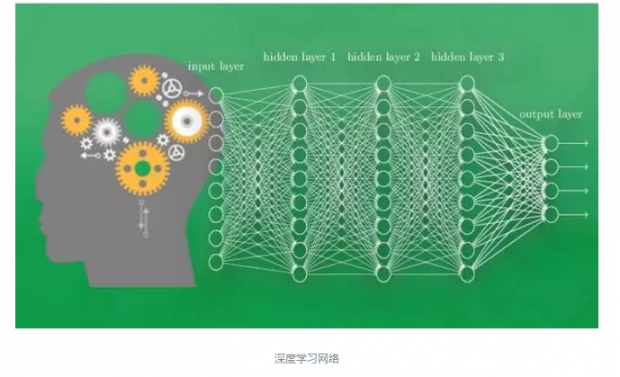
上图就是一个典型的神经网络系统,它具有多个层级。多个层级构成了“深度”,也就是我们常说的深度学习网络。不管网络有多深,一般都会包含“输入层”、“隐藏层”和“输出层”。输入层负责接收信息,比如,一只猫的图片。隐藏层负责在网络中,对输入的信息进行加工处理。而输出层就是根据隐藏层计算的数据,得出计算机对输入信息的认知,比如判断输入的图片是不是一只猫。
听起来有些因吹丝汀?!那么就让我们看看神经网络到底是如何被训练的吧!
首先,它需要大量的训练数据。如果要让神经网络判断一张图片是不是一只猫,那么就必须给它看大量的猫猫狗狗的图片。既然要训练神经网络,那么肯定也要告诉它这些图片哪张是猫,哪张不是,也就是给这些图片“打标签”。

在训练的过程中,神经网络会先依靠自己的“主观意识”,尝试对图片进行判断。然后将判断结果与图片标签做对比,看看自己是不是判断错了。当然一开始它的判断几乎全是错的,但每当它判断错误时,错误的判断结果会被计算而转化成宝贵的学习经验。神经网络利用积累下来的经验去改善“自我”,以至于下次可以作出更佳准确的判断。
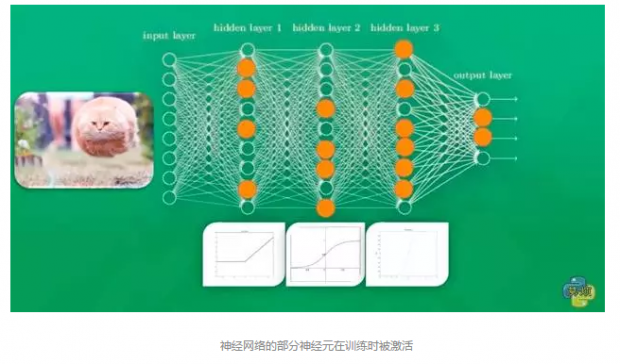
那么它究竟是如何从经验中学习的哪?首先就是比对正确答案和错误答案之间的差别,计算出预测误差值,然后再把这个误差值反向传播回去,依据误差值去调整不同层神经元之间的连接参数。初期的误差较大,所以反向对神经元连接参数的调整就比较大;随着训练次数的增加,预测准确性增加,误差减小,此时反向对神经元连接参数的调整就变的微小。慢慢的神经元连接参数趋于稳定,整个神经网络能够较好的完成预测,训练就可以结束了。
那么这个反向传播到底是什么?为什么就能将神经网络调整的越来越好?
有没有更高明的方法,可以让神经网络训练的更快?
还有除了上面介绍的简单神经网络,CNN,RNN,LSTM,又是怎样工作的?
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}