阅读:0
听报道
文 | 张江
导语
发这篇文章的时候,柯洁与AlphaGo世纪大战首战已经结束了,可以说是毫无悬念,柯洁最终还是输掉了一局,这也是在大家意料之中的事情。今天借着这样一个契机,我写下了这篇文章,重点想和大家聊一聊AlphaGo背后的人工智能技术。

我们知道,去年三月份战胜围棋高手李世乭的AlphaGo实际上是一个多种AI技术、多个深度网络的混合体。它的总体架构如下图所示:
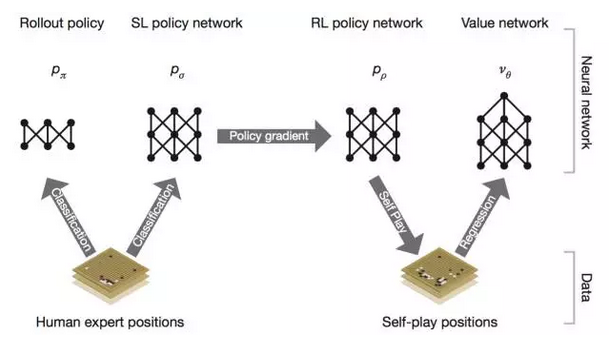
其中整个架构分成左右两部分,左边是两个神经网络,利用人类的走棋来训练得到。DeepMind获取了韩国网络围棋对抗平台KGS上大量高手走棋的棋谱,并训练左边的神经网络来预测人类下一步的走棋。右侧的部分则是不需要借鉴人类下棋的经验,机器完全通过强化学习,自己跟自己玩从而训练网络达到强大的水平。据说,现在的AlphaGo是升级版本的,它已经完全抛弃了基于人类专家下棋经验的走棋网络(左边),而只剩下了AlphaGo左右互博的强化学习部分。本篇文章就主要讲讲右半部分,左右互搏的AlphaGo。
走棋网络
首先,我们可以将AlphaGo看作是一个机器人,棋盘加对手就是它所面临的环境。AlphaGo需要学习的就是在面对不同环境的时候,它应该如何进行决策,也就是给出下一时刻的走棋。我们把这种从当前棋局决定我应该走到哪里的对应称作一个策略(Policy),AlphaGo通过大量的自己跟自己下棋从而得到这样的一个走棋策略。
具体的方法是,我们首先构造一个深度的卷积神经网络(称为走棋网络),输入的是棋盘状态所构成的一张二维图片;输出的则是AlphaGo下一步的走法,如下图所示。
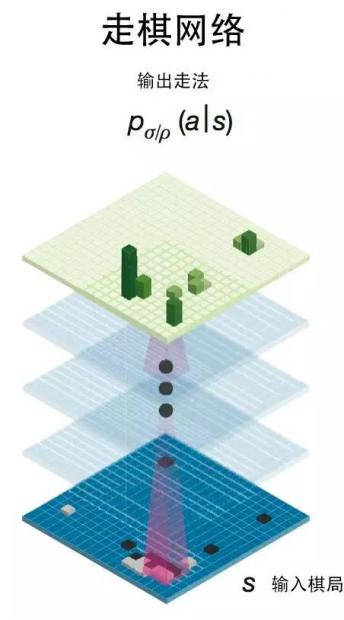
我们知道,深度卷积神经网络非常擅长处理图像,它不仅可以敏锐地辨别图像属于不同的类别,而且还可以提炼出图像中的多层次信息。例如,当我们把大量的图片喂给卷积神经网络的时候,它就可以在低层的网络提炼图像中的细节信息(如边缘、棱角),而在高层则处理图像中的大尺度信息。之所以在和李世乭的世纪大战中,AlphaGo展现出了某种“大局观”,就是因为卷积神经网络可以提炼棋局中的大尺度、高层次信息。
有了这样的网络架构,我们就要训练这个网络了。然而,卷积神经网络的训练是需要有监督信息的,而我们知道围棋是一种无监督的博弈,AlphaGo只有在走完了整个棋局才能获得反馈,怎么办呢?答案就在于左右互博!我们可以让当前的AlphaGo和它自己来进行比赛,走到终点!这样不就可以获得反馈信息了吗?
具体地说,我们可以用同一个走棋网络的两个副本完成两个AlphaGo的博弈,然后让其中的一个AlphaGo进行学习。这样,每从一个棋局S开始,AlphaGo和它自己的副本完成了对局,就会获得一个输赢的得分;然后它再从S开始,再下到棋局结束,……,一共进行3千万次。由于每一次走棋都是有随机性的,所以每次的得分都会不一样,有的时候AlphaGo可能赢,有的时候则可能是输,于是针对一个棋局S,我们就可以计算这三千万盘棋的平均得分。我们把这个平均得分作为目标,来训练卷积神经网络以实现这个目标的最大化。于是,我们就用左右互搏的方式,训练出了一个走棋网络。
价值网络
然而,单纯依靠这样的走棋网络,AlphaGo虽然已经很强,但还没有强到能对抗人类围棋九段高手的地步,怎么办呢?DeepMind团队的科学家们想出了另外一种强化学习手段,这就是价值网络。什么是价值呢?我们都知道,人类是有自己的价值观判断的。比如,我们每个人都知道尊老爱幼是一种美德,这就是价值观。对于一个强化学习的程序来说,由于在很多情况下,它缺乏环境给它的反馈,于是人们就给程序设计了一种价值函数,在没有环境反馈信息的时候,程序可以根据这个价值函数来选择自己的行动,让价值最大化。但难点是,我们应该怎么设计这个价值函数呢?答案是,让机器自己把这个函数学到。
在AlphaGo 中,它同样是依赖于类似于走棋网络的方法来学习出一个价值函数的,这个函数能够评定每一个棋局的可能获胜的价值有多大。AlphaGo仍然利用了一种卷积神经网络的技术来实现这个价值函数,如下图所示:
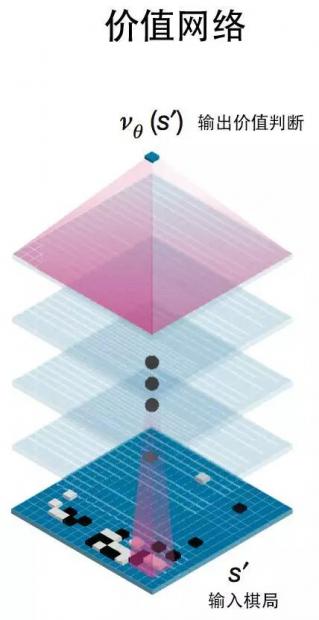
同样的,这个价值网络的反馈信息也来源于从任意一个棋局开始的左右互搏。在训练的阶段,AlphaGo从当前棋局开始运用上面已经训练好的走棋网络走棋,一直下到结尾而得到输赢的得分。这么做三千万次后计算平均得分z就是价值网络的学习目标。也就是说价值网络要根据当前棋局S'得到价值判断v(S'),以使得v(S')要尽可能地靠近z。
引入了价值网络之后,我们又会面临新的问题,我们究竟是应用走棋网络来指导我们下棋,还是依赖于价值网络呢?在AlphaGo的早期版本中,它是运用价值网络的评估结果来作为AlphaGo走棋的主要参考的。但由于价值网络在计算每一个棋局的平均得分的时候,每一次走棋都是根据走棋网络进行的,所以其实价值网络已经综合了走棋网络。
蒙特卡洛树搜索
然而,即使这样综合了两者的意见,AlphaGo还是不能达到九段的水平,因为它不能像围棋高手一样进行虚拟走棋。我们人类在下棋的时候,总会从当前的棋局开始,往前看几步,然后才决定当前这一步的走法。
所以,在实际开始下棋的时候,DeepMind再借用了一个大招,这就是蒙特卡洛树搜索,这种算法可以让AlphaGo进行虚拟地走棋,从而在一定搜索步骤后,才决定当前应该走到哪里。我们知道,经典的人工智能的方法就是搜索。我们把每一个棋局看作一个节点,如果通过一步走棋a可以从棋局A走到棋局B,那么我们就从A建立一条有向连边到B,这样通过走棋我们就可以得到一个网络。然而,我们很快就会发现,不可能在电脑空间中装下这个网络。假设每步有10种可能的走法,那么虚拟地走10步棋就会有10^10种可能棋局,这已经是一个非常大的数字了。所以,AlphaGo必须巧妙地对这个空间进行压缩,从而避免组合爆炸。
蒙特卡洛搜索算法的好处就在于它可以依概率来在众多的可能性中选择一个,从而砍掉大量其它的分支树,快速地展开树搜索。开始的时候,由于我们对当前棋局了解不多,于是我会纯随机地选择一种走法a。但是经过几步虚拟走棋之后,我就会积累关于棋局的信息,从而减少不必要的随机搜索。
在AlphaGo中,它的随机选择并不是纯粹的随机,而是利用了前面介绍的走棋网络、价值网络的先验信息,以及累积到的下一步棋局的信息等等再随机走棋的。
具体地,假设现在AlphaGo所在的棋局是S(真实的棋局),于是它开始展开树搜索,也就是展开虚拟的对局。每一步虚拟对局应该怎么走是依据走棋网络进行的,如下图所示:
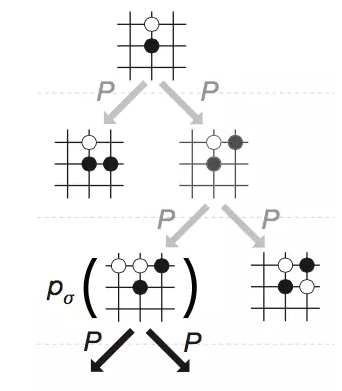
这就是一次虚拟走棋(搜索),每一步打开棋局节点都是根据走棋网络p_{sigma}。在早期版本的AlphaGo中,这个走棋网络是通过和人学习训练得到的(参见图1中的左手第二个网络),而在现在的升级版中,这个走棋网络很可能就是前面介绍的通过深度强化学习训练得到的。
这种虚拟走棋不可能一直走下去,而是在经过了T时间步后就会停止。虚拟走棋停止之后,我们就可以对这些虚拟走出来的棋局进行评估。事实上,人类在进行棋局推演的时候,也就是要评估每一种可能走棋究竟是好还是坏。AlphaGo的价值评估过程如下:
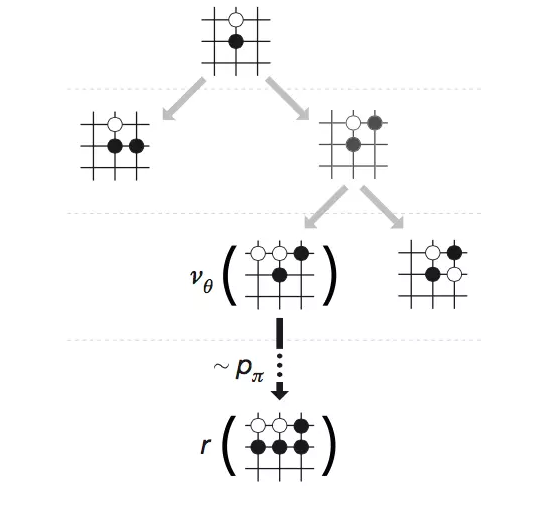
首先,对于一个叶节点(也就是虚拟走棋走到的最后一步所对应的棋局)来说,AlphaGo会利用一个快速走棋算法p_{\pi}(根据人类的棋谱训练得到的另一个神经网络,参见图1)将整个棋局走完,从而对该节点进行评估。这种评估综合了之前训练好的价值网络(v_{\theta})和快速虚拟走棋到达终局的结果好坏程度(r)来给出。
其次,对于非叶子节点,AlphaGo会将叶子节点反推回来的价值信息进行综合来计算该非叶节点的价值信息,如下图所示:
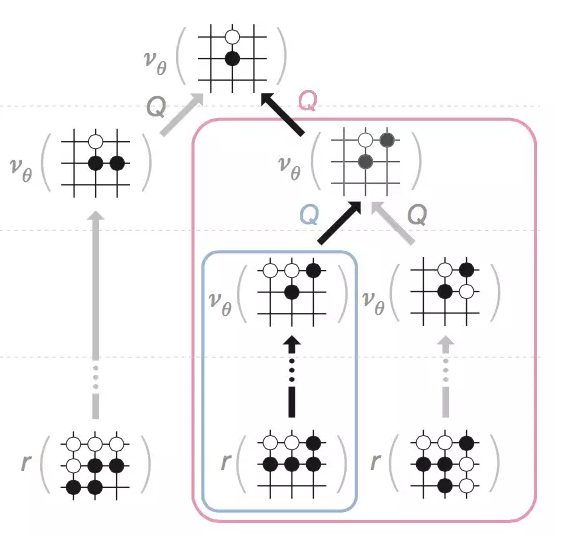
这里的Q就表示根据后续的棋局来进行综合的算法。总而言之,通过层层的计算,我们能够给每一个虚拟走出来的棋局赋值一个评估值Q,它综合了快速搜索和价值网络的评估。
最后,AlphaGo将根据这些“思考”的结果,依据估值信息Q来展开真实的走棋,也就是在所有可能的下一步棋局中,选择Q值最大的一个进行实际落子。至此,AlphaGo终于走出了艰难的一步!
综合
整个AlphaGo实际上仍然分成了学习和走棋两个大的阶段。在与柯洁对战之前,AlphaGo通过自我对局的方式完成对走棋网络和价值网络的学习。而在真正对战的阶段,AlphaGo将主要展开对蒙特卡洛树搜索的算法,并综合搜索和学习的成果完成每一步走棋。
所以,总的来说,AlphaGo是将深度强化学习的技术与蒙特卡洛树搜索技术巧妙地综合到了一起,从而得到的一种超强的算法。这种将最新的深度学习技术与传统的基于符号、推理、搜索的AI技术相综合的方法正是现在人工智能界的一个主要趋势。

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}