阅读:0
听报道
文 | 张江
导语
没错,AlphaGo的确有一个同父(Deep Mind)的亲哥哥,出生于2015年。从某种程度上说,AlphaGo的这个哥哥比Alpha狗还要厉害,因为它更接近我们人类追求人工智能的终极目标:通用人工智能。所以,这个哥哥一出生就引起了当时的舆论界一片哗然。这个哥哥名叫Deep Q Network,简称DQN。

如果你看着AlphaGo虐待咱人类围棋冠军不爽,那就来一起把它的哥哥DQN解剖了吧!
人工智能打游戏
这个DQN是干嘛的呢?它是一个专门负责打游戏的人工智能!可能你会认为人工智能打游戏没什么了不起,因为游戏本身不就是一种计算机程序吗?但关键是,这个神经网络是要像人类玩家一样通过读取屏幕上的像素级画面获取输入信息,并直接进行判断应该采取什么行动。该网络需要一边玩一边学,从而达到人类的水平。
要知道最终训练得到的这个DQN网络有多牛,不妨让我们来看看它是如何一点点学会打砖块这款游戏的:
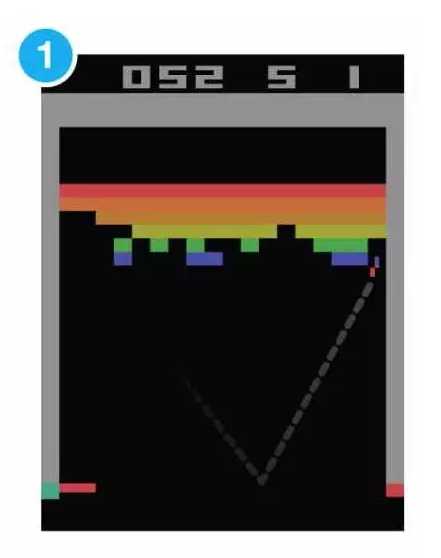
这是DQN算法在开始玩打砖块游戏的时候的表现,它显得非常笨拙,球拍总是躲在一个角落里,不知道去接球。
随着DQN不断地学习、总结经验,它的表现开始变好了:
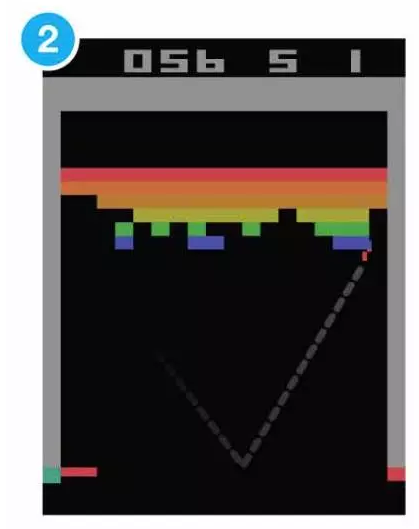
这个时候的DQN已经学会了如何接球。不过,它还在进化……
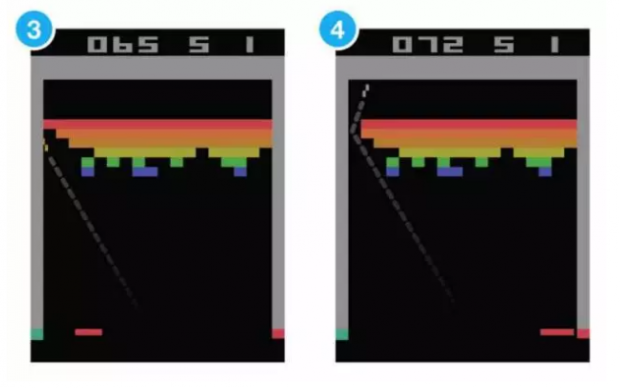
慢慢地,它竟然学会了将一侧的砖块打穿,然后让小球弹到砖块平台的上边,保证求不掉下来的同时,一直不断地打砖块得分。关键的是,这种看起来能够体现一定智力的策略并不是人类通过编程告诉DQN的,而是它自己通过深度强化学习算法学习出来的。
那么,DQN究竟是如何学习到这种“创造性”的玩游戏策略的呢?接下来,就让我们拿出手术刀,解剖一下这个DQN算法。
Q估值
其实,DQN的思想来源于一种被叫做Q学习(Q-learning)的古老算法。这种算法的基本思想是,给打游戏的人工智能主体赋予一个价值函数Q。这样Q就可以给主体所面临的当前环境状态S(游戏的状态)和主体当前所采取的行动a一个评分,并且主体会在若干个可能行动中选择一个让Q函数值最大的。这就好比一个小孩子,当他面对一个陌生的环境的时候,就会经常问自己,我现在是不是应该躺在地上打个滚儿?Q函数就是它自己的评价标准。如果他的Q函数对陌生环境,打滚这个状态、动作组合评分高的话,它就真的会这样做!
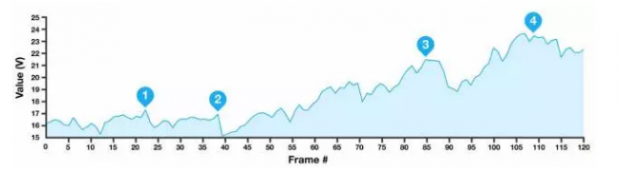
该图是DQN学习打砖块游戏的时候Q函数值随时间的变化情况,我们会看到Q在缓慢上升。
但是,即使引入了Q函数,我们还是没有解决问题,因为Q函数又怎么来确定呢?
Deep Q Network
DeepMind的工程师们在这里引入了深度学习技术,它们用一个多层的深度神经网络来建模这个Q函数,如下图所示:
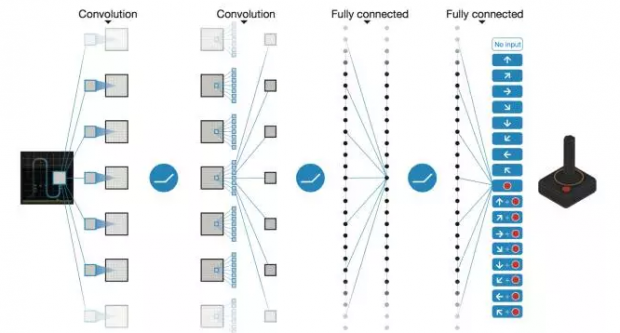
如图所示,左边的神经元负责接收来自游戏屏幕的像素级的画面(这就是环境状态S),然后网络连接到了一个三层的卷积神经网络。我们知道,卷积神经网络是个认图、识图的高手,它不仅可以对图像中的物体进行准确的分类,而且还能够从图像中提取多尺度信息,例如低层的卷积层会提取图像中的边缘、棱角等特征,而高层的卷积网则可能会提取人物、障碍物等大尺度高层次特征。总之,卷积神经网络会帮助智能主体进行分辨图像。
网络的输出层由多个神经元构成,每一个神经元都对应了一种可能的行动a(例如球拍的左移或者右移),输出的数值则表示在在这种环境S和行动a组合下的Q函数值。也就是说,整个网络就是一个Q函数。
Q-learning
我们知道,这个神经网络是一个典型的前馈神经网络,因此,它需要有一个目标函数来指导它的学习。在DQN中,它的目标函数是什么呢?答案就在于这个Q函数要能尽可能地对主体在未来所获得的激励进行准确地评估。这里的激励既包括来自于外在环境的外在激励,例如游戏在下一时刻所获得的积分,也包括内在激励,即主体的Q函数对未来状态和行动的估计值。所以,当环境的外在激励为0的时候,DQN仍然能够学习,它在尽可能地做到让自己的Q函数在现在和未来的预估要尽可能地一致!
我们还是用小孩子的例子来说明这种一致性。假设小孩来到了一个陌生的环境,它的父母也不在身边,环境在大多数情况下也没有任何反馈信息。那么,小孩子所做的任何行动都无所谓客观的好还是坏。这个时候,小孩子也就会慢慢地建立起一套自己的价值观(Q函数),它会给他自己的行动一种意义(选择一个行动,以最大化Q)。这种价值观怎样都行,只要它能保持前后一致。直到,这套价值观与来自环境的反馈不一致的时候,它才会调整。比如,它开始以为满地打滚就是好的,但是一旦他的父母发现,打了他一顿,他才开始修正自己的价值观。这就是Q-learning算法的本质。
DQN利用神经网络的方式实现了Q学习算法。神经网络的好处是具有非常好的泛化能力。这样,即使当DQN遇到了一种从未遇到过的环境的时候,它也能作出正确的决策。
DQN的表现
接下来,就让我们看看,这个DQN算法究竟能够表现得多好!
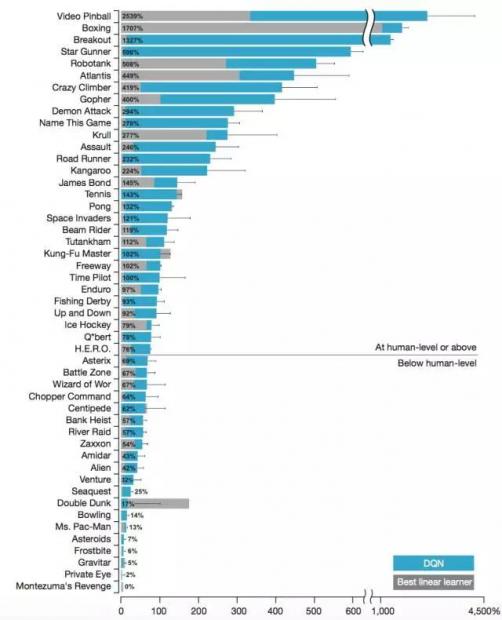
在这张图上,蓝色的柱子就是DQN算法的表现成绩,而灰色的柱子是2015年的时候最好的强化学习算法的表现。每个柱子中的百分比数值是该算法与人类最好的玩家相比的相对表现。不同的行代表了不同的游戏。我们可以看到,DQN算法可以在绝大多数游戏中表现得比人类还好,而且像Video Pinball和Boxing这些游戏上,表现已经远超人类。
DQN不仅可以给出非常酷炫的表现,更重要的是,它还可以学习得到对不同游戏状态的表征,如下图所示:
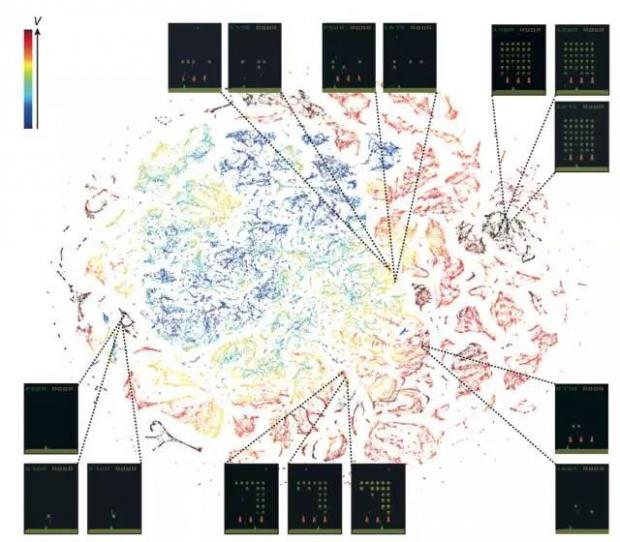
在图中,每一个点就代表一个游戏状态(外星入侵者Space Invadar),两个点彼此靠近就表示这两种状态是相似的。我们知道,DQN的神经网络不仅可以正确地估计Q函数,而且还能够在隐含层学习得到每个游戏状态的向量表示,我们利用tSNE把这个高维的向量进行降维并可视化,就得到了这张图。
至此,我们已经领略了DQN算法的有效性。然而,有一点值得强调的是,这种DQN算法是一种非常通用的算法。也就是说在保持一套相同的超参数不变的情况,我们只需要让它玩不同的游戏,就会自动学习出来不同的应对策略,因此DQN可以往通用人工智能上迈出一大步。
参考文献:
Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}