阅读:0
听报道
文 | 张江
导语
没错,人工智能界除了Alpha狗真的还有两只猫,一只叫拷贝猫(Copycat),另一只叫超级猫(Metacat)。虽然猫猫们没有Alpha狗那么有名,但是她们却本领非凡,一个可以像人一样浮想联翩、类比联想;另一个则可以自我审视、自我观察。而且,这对儿姐妹猫还有一个牛的不得了的父亲,他就是奇书《哥德尔、埃舍尔、巴赫》的作者:侯世达(Douglas Hofstader)!今天就让我们说说这两只猫!

拷贝猫(Copycat)
在介绍这只猫咪之前,让我们先来做这样一个小游戏:
如果我告诉你abc可以对应abd,那么请问xyz应该对应什么?
估计你会回答是xya。你的思路可能是这样的,d是c在字母表上的后续字母,而z是字母表的最后一个字母了,所以只能再次循环到了最前面,于是就应该对应a,于是像abd对应abc一样,我们应该用xya对应xyz。
然而,这种对应显然不是唯一的答案。你也可以说,xyd就是最终答案。因为你假设我们的规则就是用d来替换字符串中的最后一个字母。由于我并没有明确指出这种替换遵循的规律是什么,而且样本又非常地小,所以xyd的回答也未尝不可。
还有一种有趣的回答是wyz,为什么呢?注意到abc是字母表最前面的三个字母,xyz是字母表最后的三个字母,这两个字母串刚好形成了一个镜面对应关系。从a-->b-->c的顺序看我们是在从前往后往字母表的深处走;而从z-->y-->x的顺序看,我们是在反向地往字母表深处走。于是abd替换abc实际上就是最后一个字母再往深走了一步,而wyz替换xyz则是第一个字母再往深走了一步。这二者刚好构成这种镜面对称性。
类比思维
这能说明什么?
这说明了人类类比联想思维的多样性和趣味性。当你尝试抓住模式(Pattern),尽力猜出那个字符串的时候,你实际上在做就是类比思维。而这种类比通常都具有很大的任意性。有的类比可以乏味无比,比如回答abd的人;有的类比则会让人眼前一亮,甚至是创造性的源泉,就比如wyz这种回答。
类比思维是人类创造性的重要源泉之一。很多科学事实、科学原理的重大发现都起源于类比。比如,卢瑟福的原子模型就是类比太阳系九大行星模型而提出的;再比如人工神经网络就是类比人类大脑网络而创造出的一种计算模型。
起源于中国的东方哲学大量借鉴了类比思维,这种类比甚至相当抽象。例如,道家思想中的五行理论就是借鉴类比思维的典型。当他们说肾相对于心,就相当于水相对于火的时候,他们的思维方式也和解那个字母问题没有很大的区别。
Copycat
然而,人类的类比思维究竟是如何进行的却一直让人感觉扑朔迷离。似乎,类比总是跟灵感、顿悟等等这些说不清、道不明的东西有关。
侯世达是人工智能界出了名的独行侠,当年就以一本《哥德尔、艾舍尔、巴赫》而名震天下。他看不上所有当时主流的人工智能研究,却对这种扑朔迷离的“类比”谜题产生了巨大的兴趣。于是,他带领着他当年的博士生梅拉妮.米歇尔(Melanie Mitchell)一起奋战五年,终于开发出了一个可以进行类比的计算机模型,这就是拷贝猫(Copycat)。
拷贝猫的工作界面如下图所示:
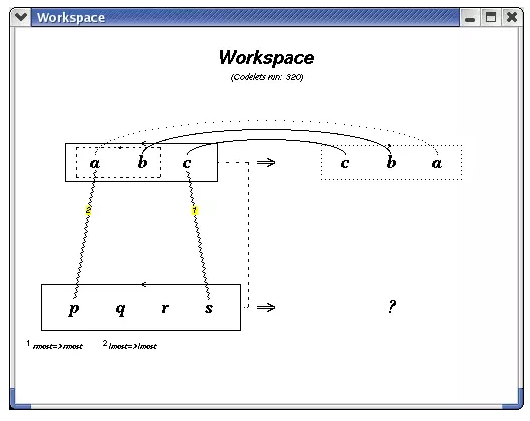
拷贝猫的唯一任务就是求解我们上面类比问题,比如“如果直到abc相对应abd,那么xyz应该对应什么?” 在上图中,字母都是一个个的单元,而用方框框住的字母则表示拷贝猫正在尝试发现的模式。方框越实表示拷贝猫对这种模式越确定。方框(字母组合)或者字母之间的连线弧表示系统发现的可能类比关系,线越实则表示拷贝猫越确定。
拷贝猫可没有可爱的小猫外形,却更像是一个由大量蚂蚁(codelet,一个小程序)组成的复杂蚁群。它们会沿着一个叫做Slipnet的网络上爬来爬去,尝试发现字母或者字母组合中的各种关系。Slipnet的示意图如下:
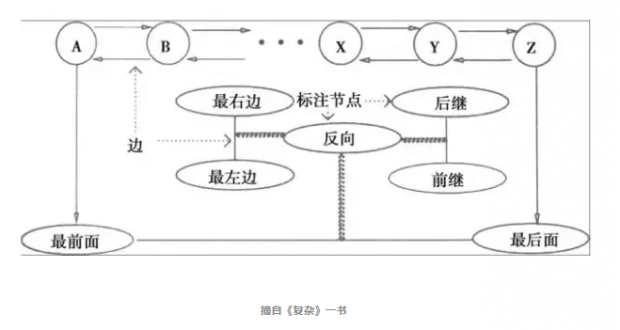
每一个节点都表示一个概念,连边表示一种关系。沿着这个网络移动的一个路径就相当于在进行类比思维。数十只蚂蚁在这个网络上爬行形成不同的类比,从而为某一种类比进行投票。最终整个拷贝猫会对类比关系形成投票的分布,从而确定对应的字母组合是什么以解答类比问题。拷贝猫就是用这样一种多个部件并行处理信息的方式完成了抽象的类比。
值得指出的是,拷贝猫模型并不试图解决真实世界中的类比问题,它只是一个玩具模型,运用复杂系统的运作模式来类比人类的类比思维。
超级猫
后来,父亲大人侯世达又对这个拷贝猫小女儿做了一次升级,这就是所谓的超级猫(Metacat,或元猫)。她与拷贝猫最大的不同就在于,这个超级猫可以进行自我觉知、自我观察。我们知道,人类思考过程的一个典型特征就是觉察到这个思考的自我本身,从而在适当的时候能够跳出系统的框框进行全新角度的思考。这样,人类就会避免像机器那样陷入死循环。
超级猫会不断地观察自己,并对出现的模式作出响应。拷贝猫就缺乏这种“内省”的能力,因此也对它自己是如何达到最终思考结果的而感到困惑。超级猫还可以通过自我观察能力来比较不同回答,还能在自己的“思维列车”中捕获、识别、回忆各种模式。所以,当超级猫进入循环的时候,它自己就有可能觉察到,并跳出来。当然,所有这一切都是在一个相当抽象的环境下进行的。
有关“类比”的新发展
无论是拷贝猫还是超级猫,她们都是侯世达在90年代开发的计算机模拟程序,在性能和实用性上显然无法与现代的各种强大的人工神经网络,人工智能算法相提并论。但是,在科学研究中,一个好的问题就好比是一只会下金蛋的母鸡,它往往会比好的解答更重要。类比就是人工智能需要认真对待的一个非常好的问题。
那么,现在“类比”这个问题进展如何了呢?非常有趣的是,2013年,Google的Miklov开发了一套从大量文本中提取词向量的工具Word2Vec。只要我们把大量的文本语料喂给这个程序,它就可以计算出每一个单词的词向量,并且让语义上靠近的单词,在向量表达上也相似。
而更有意思的是,这些单词词向量的线性组合运算就可以进行类似于开头那个小游戏一样的类比思维。比如,在Word2Vec中那个最著名的数学公式:
v(男人)-v(女人)=v(国王)-v(王后)
就表达了类比关系。这里面,v(男人)就表示Word2Vec计算出的表达“男人”这个词的词向量。我们可以将类比任务:男人相对于女人,相当于国王相对于什么?转化为数学求解,x=v(国王)-v(男人)+v(女人),于是,我们便可求得王后这个单词的词向量。
这说明实际上所谓的类比关系就蕴藏在成千上万单词所构造的大型语料库之中。当我们用这些单词去训练一个模型的时候,该模型就会自动把握其中的隐含模式,而这些模式就具有这样的类比关系。
不知道侯世达是否了解Word2Vec的工作。但从他的采访报道中可以肯定,他对当前火得发紫的深度学习、神经网络是相当不屑的。我相信,如果他了解到了Word2Vec,一定会被这个算法的简洁性所震惊!也许他会承认,运用简单的模型,在大数据中提炼隐含模式的确是一个研究类比问题的有效路径。
反过来,拷贝猫、超级猫这些早年的模型反过来对现在的基于统计和神经的类比研究也会有所启发。比如拷贝猫就可以考虑多种类比方式,而Word2Vec的向量计算恐怕就只能有一种。也许,通过知识图谱的表达理论,我们才有可能事先拷贝猫的这种多方位类比。
参考文献:
Copycat:
Metacat:~jmarshall/metacat/
梅拉妮.米歇尔:复杂,湖南科技出版社,2013.

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}