阅读:0
听报道
文 | 李嫣然
导语
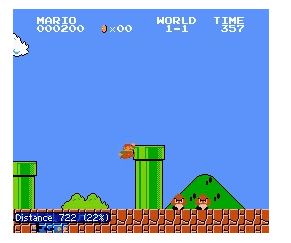
是的,机器也可以有好奇心。这不,科学家们正在努力赋予人工智能算法好奇的本能,帮助它们更好地完成强化学习。在ICML2017的这篇论文《Curiosity-driven Exploration by Self-supervised Prediction》中,作者就用好奇心作为一种奖励激励,来让人工智能控制的马利奥救出公主。
ICML 2017 accepted paper 已经公布。其中一篇值得关注的工作就是来自 UC Berkeley 组的《Curiosity-driven Exploration by Self-supervised Prediction》。这篇工作的主张是,即使没有明显的(外界)reward,用他们的算法也可以让马里奥大叔一路顶蘑菇地勇往直前去救碧姬公主啦:
不过其实啦,很多工作都有非常相似的“前人”工作。虽然不一定没有新意,但是互相对比来看会对整个大的思路有更不错的理解。今天要对比的工作分别是:
1. 《Curiosity-driven Exploration by Self-supervised Prediction》 by UCB. ICML 2017.
2. 《Learning to Act by Predicting the Future》 by IntelLab. ICLR 2017 (oral).
3. 《Deep Successor Reinforcement Learning》 by MIT & Harvard. NIPS 2016 workshop.
这三篇工作都是想解决复杂任务中奖励很稀疏的问题。比如如果我们只用是否最终完成了一个任务,完成就给一个正的奖励,没完成就一直没有奖励,那么整个马尔科夫决策过程只有最终那一步才会得到奖励,这就是一个很严重的稀疏问题。这也是大部分增强学习算法面临的最主要的问题之一。
为了解决这样的问题,其实过去已经有不少工作提出了一些解决思路。如果我们把这些完成任务后会得到的最终奖励叫做 external reward(外部激励),我们也可以通过一些别的设计来为 agent 提供 intrinsic reward/motivation(内部激励)。这篇 ICML 的工作[1] 就是将这种内部激励设计为特别的 curiosity-driven(好奇心驱动)的形式。并且他自己也提到了,这种形式在过去的工作里也已经被探究多次(有机会下次再和大家一起总结讨论)。
好奇心驱动的工作如果放在增强学习的框架中来看,主要有两大类具体形式:
1)激励 agent 去探索更多的新状态(novel state);
2)激励 agent 去执行一些会减少自己对于未来不确定性的动作,或者可以反过来理解为去执行一些能增加自己对于未来的信息的动作。
这两个思想都非常好理解,几乎可以完全在人类的学习中找到映射。然而只考虑这两点则会出现一些问题,当当前问题或者环境存在很多噪音的时候,这类驱动方法往往会导致 agent 被无关干扰物吸引。
为了解决这个问题,ICML 2017[1] 的思路就是去尽量减少噪音的影响。因为去激励 agent 去执行那些会降低自己对于未来不确定行的动作,必然涉及到要去预测某个动作会产生怎样的影响,所以他们的思路是只预测那些和当前动作有关的影响。也就是说当 agent 执行一个动作或者随着 timestep 的进行,环境的变化有两大类,一类是由 agent 造成的,一类则是噪音,和 agent 如何选择动作无关。后者是 ICML 2017[1] 这篇工作想要排除掉的。
所以 ICML 2017 的工作[1] 就是只预测那些和 agent 相关的环境变化,也就是将预测拆解(factorize)。从这个角度去理解的话,ICML 2017 的工作[1] 则和一篇 NIPS 2016 的 workshop[3] 非常相关。NIPS 2016 workshop 这篇工作中提出用一种叫 successor representation(SR)的方法去求解 RL 问题,这个方法的主要思路就是将 value function 拆成(factorize)两部分:一个是通过预测任务学习到的表达,和一个与表达紧密相关(低噪音的)激励函数,而且这个激励函数还是 immediate and intrinsic 的。下面就会从对比这两者的角度来介绍这篇工作。
ICML 2017 中提出的模型结构叫 Intrinsic Curiosity Module(ICM):
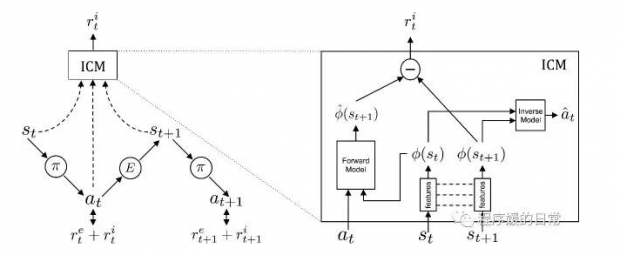
其中 r^e 代表外部激励(external reward),r^i 代表内部激励(intrinsic reward)。可以看到首先,每个状态都会被 ICM 编码成 \phi (s_t) 得到一个特征空间中的表达。这个特征空间的表达,有两个作用,一个是用于经过 inverse model,预测当前(或者说上一刻的)动作,另一个是用于经过 forward model,预测下一刻的状态表达。而这种预测的误差就被认为是好奇心激励(curiosity reward)。
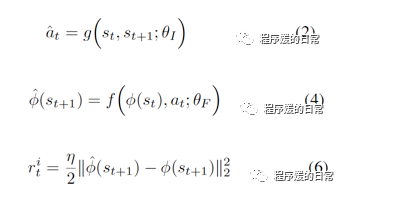
inverse model 和 forward model 结合在一起,双向模型共同,就构成了一种自我监督(self-supervised)的学习方式。从 inverse model 的角度看(公式2),网络 g 只会去学习那些对于预测上一刻动作 a_t 有用的特征。同理,从 forward model 的角度看(公式4),网络 g 只会关心那些和预测有关的特征。所以,通过这样的方式,环境中那些不能被预测的变化,即噪音,就不会被“注意”到,自然也就被排除掉了。
在回过头来看 NIPS 2016 的工作[3]。这个 successor representation(SR)其实从名字上就反映了类似的思想。SR 的公式如下:
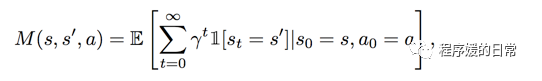
通过这其中涵盖的指示函数,可以将 SR 的公式理解为已经覆盖/访问过的状态的数目(state visitation count)。把 SR 的公式和更熟悉的 Q-function 对比:
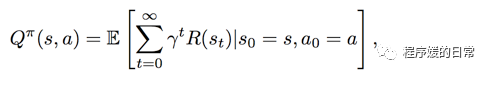
就会发现两者之间有很多相似之处。Q-function 用来计算的 expected discounted future return, SR 计算的是 expected discounted future state occupancy. 有了这样的 SR 表达式,就可以进一步将 Q-function 拆解(factorize)成 SR 表达式与激励函数表达式的内积了:
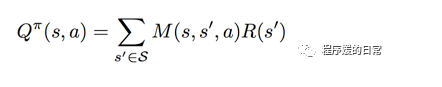
至此,再回顾一下 NIPS 2016 workshop[3] 的思路。他们通过 SR 的方式,将增强学习拆解成特征空间的表达学习(SR)和基于表达的激励函数学习(R)。并且这个表达学习的 SR 拟合的也是对于状态空间的探索程度——与 curiosity-driven 或者说探索更多未知领域的思路,是一脉相承的。从此也就看出了 ICML 2017[1] 和 NIPS 2016 workshop[3] 的相似之处。而这里的 R 又可以进一步拆分成外部激励和内部激励。
再来看另一篇比较相似的工作,是来自于 ICLR 2017 的 oral 之一[2],主要 direct prediction of future。他们的工作同样想寻找除了最终的稀疏的外部激励以外的“激励”。如果把奖励函数看做是对当前策略或者动作的一种评估,那么 ICLR 2017 的工作则可以看做去寻找每个状态下的多种相关“评估”指标,也叫 measurement。也因此,他们假设,一个增强学习的任务是可以表示成 measurements 的组合的。有了这个假设,他们进一步认为,预测这些 measurements 就可以得到对于自己当前策略的一种评估。换句话说,自己选择的这一步动作会产生什么样的变化,可以通过预测 measurements 来学习到。也就可以实现自我监督(self-supervision)。这个思路是和 ICM[1] 一致的。只不过最终对于 reward 的刻画,两边采用了不同的方式。
至此,三篇工作的大致思路都介绍完毕了。可以看到三者非常相似,都是尽可能地提供更多的 immediate reward。这种思路也被统称为 reward shaping。同时,有一些工作还会将这些中间状态的激励,叫做 subgoal,skill 或者 option。三篇工作甚至还做了相同的实验。ICM[1] 除了打马里奥以外,还打了 Doom。而[2][3] 也打了 Doom。来看看三者打的 Doom 结果:


三者都展现了自己对于未知地图或者说未知环境的泛化性,同时也展现了这种 reward shaping 这种方式对于增强学习训练的好处:稳定性提高、收敛变快等等。ICM[1] 的工作比较惊艳的地方在于,他们彻底地将外部激励挪去后,依然可以只通过内部激励促使 agent 学出很好的策略,完成游戏。而 ICLR[2] 的方法则直接夺得了去年 ViZDoom 2016 的冠军,从视频中可以看出它的策略会更加细致,不会“横冲直撞”,会捕捉很细微地移动,从而提高了收集物品和射击敌人的准确度(完整视频请看论文提供的地址,这里只截取了十秒)。而 SR[3] 的工作还有一些很有趣的可视化。SR 可以用于提取具体的 subgoal,从而展现出学习效果:
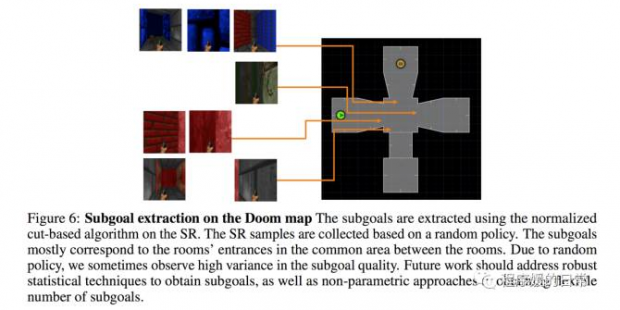
其实如果把三篇工作都看做 subgoal 或者 reward shaping 的工作,则 hierarchical RL 的相关工作也都是这些工作的“远亲”。
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}