导语
前些日子AlphaGo以一“人”之力横扫了国内几大顶尖围棋高手的事情,相信在江湖上已经无人不知无人不晓了。
新闻之外,如果你对AlphaGo的实现技术感兴趣,相信你也已经听说过“强化学习”了。
AlphaGo是个大工程,除了“强化学习”,还利用了“蒙特卡洛树搜索”等多种技术,今天我们不去讲这些复杂的技术,就单单讲下,啥是强化学习?
1
什么是强化学习?
1、强化学习的概念
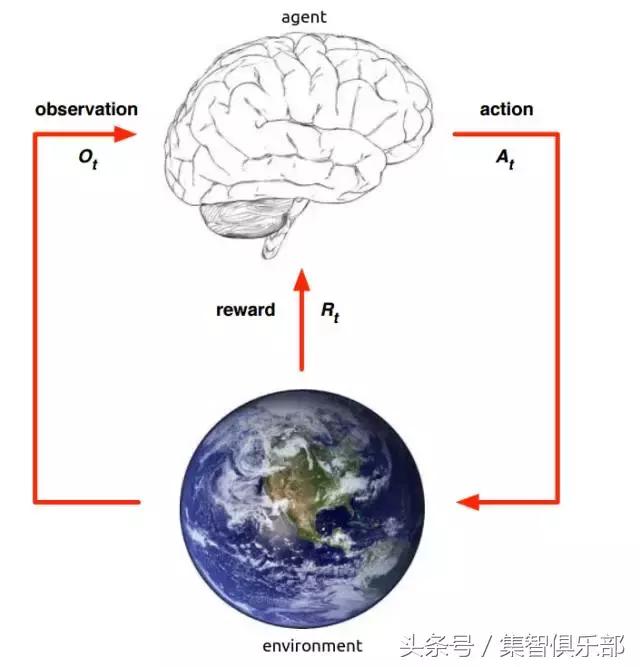
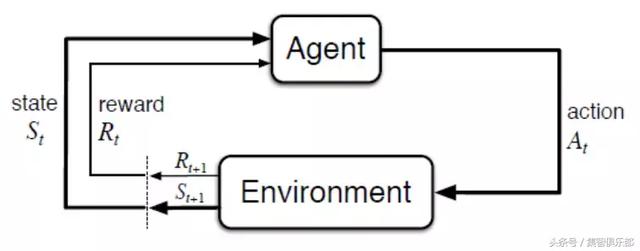
强化学习是一种通过主体(Agent)与环境(Environment)交互而进行学习的方法。它既不属于有监督学习,也不属于无监督学习。它的目标是要通过与环境(Environment)交互,根据环境的反馈(Reward),优化自己的策略(Policy),再根据策略行动(Action),以获得更多更好的反馈奖励(Reward)。
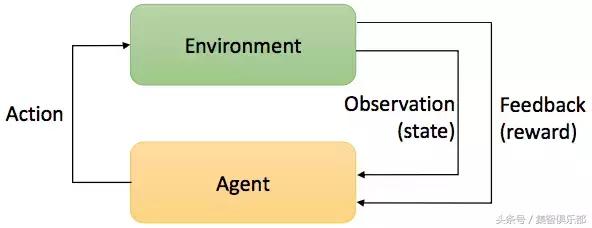
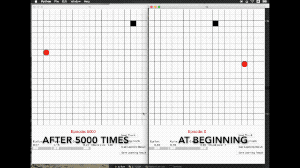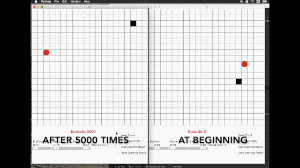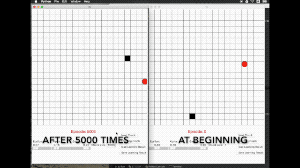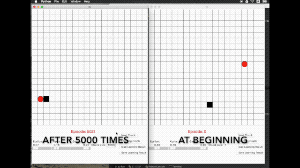
这是一个行动&反馈环,简单的来讲就是强化学习的主体可以通过环境的反馈,将自己完成任务的方式优化的越来越好,下面的动图就很好的说明了这个情况。
2、除了下棋,强化学习还能干点啥?
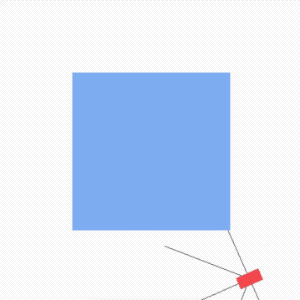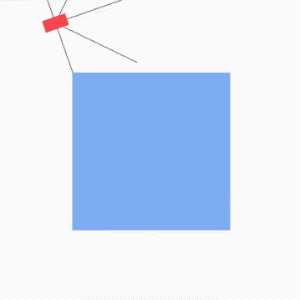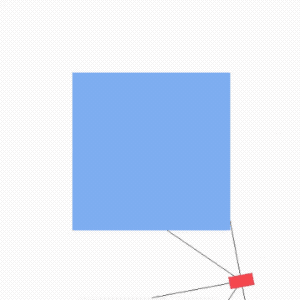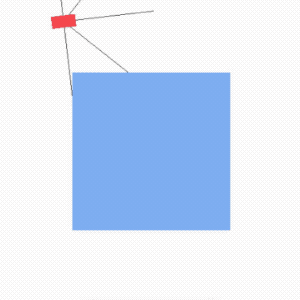
除了下棋,强化学习在其它方面的应用也是非常的火热,比如,自动驾驶,再也不需要老司机啦。
再比如,机器人机械臂的控制学习。

甚至,控制航天器的着陆。

3、强化学习的独特之处
强化学习即不属于有监督学习,也不属于无监督学习,这是为什么哪?

笼统的讲,强化学习和监督学习还是有一些共同点的,比如两者都是根据输入做出决策。
但是两者的差别也很大。比如在监督学习中,一般一次输入对应一次输出,即输入和输出在时间序列上是对应的。而强化学习中,一般是以一个序列化的数据作为输入,需要不停的作出决策。并且在采取一个动作后,并不能立刻得到环境的反馈。比如下围棋的时候在17步走了一子,导致在33步的时候输掉了整盘棋。环境并不能在17步的时候就告诉你走的不好,只能在输掉整盘棋后,再去思考哪一步走的不好。
所以强化学习要思考怎样才能达到一个长期的目标,而不能只顾及眼前的利益。
2
强化学习的核心
1、建模及核心概念
要深刻了解强化学习,最好先熟悉强化学习在模型上是如何定义的,下面我们就讨论下强化学习的模型定义方法。
强化学习是以MDP(Markov Decision Process)作为基础模型的。即假设环境状态(state)是“Markov”的,这表示state未来的变化,只与当前的状态有关,跟过去的状态没有任何关系。
举个例子,当我们去观察别人下棋的时候,我们过去一看就能知道当前的棋局状态是怎么样的,甚至还可以七嘴八舌的指导棋手怎么走,这并不需要知道他们之前下棋的步骤。
所以,主体所做的策略(Policy)就可以表示成:

即表示当前的状态St,动作At,已经包含了过去所有有用的信息(S0,A0,R1……)。有了上面的假设,机器所做的决策(π,Policy,表示下一步行动的策略),可以表示成只与当前状态有关的函数。

那么怎么才能让策略达到最优哪?
2、优化策略(policy)的目标
要求出最优的策略,我们还需要进行一个假设。

这个假设就是:我们优化policy需要达到的所有目标全部包含在环境给予的奖励(reward)中。所以要求最优化的策略,就需要尽可能的获取更多reward。
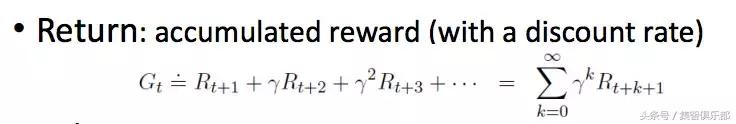
那么我们就定义一个式子,把强化学习在一轮学习过程中能获取的reward都加起来。在相加时需要给不同时刻的reward乘以一个不同的系数。为什么要乘以一个权值?因为不同时间段的reward对目标的影响程度不同。
把所reward加起来的值叫做Return,代表强化学习在未来能拿到的所有收益。
我们对Return取一个期望,就获得了Value函数。
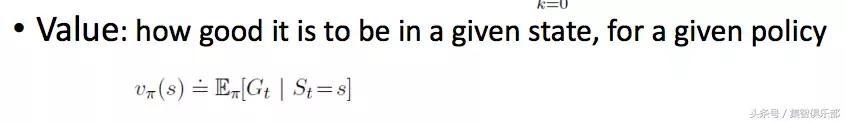
在这个函数中,s代表环境状态(state),π是策略(policy),v是state的value,代表在这个state下,采取这个策略,我们未来能拿到多少回报。
理想状态下,Value函数是只与当前环境状态(state)有关的函数。因为当前的环境状态(state)决定了系统未来的走向,也就决定了未来的环境状态(state)。
实际应用中,需要当前state和策略(policy)一起才能决定未来的state。因为根据policy采取的行动(action)会影响环境的走向,也就是影响state的变化。
我们有了Value函数来计算在当前状态下,采取每种策略(policy)能获得的收益,那么我们就可以计算每个行动(action)能获得收益(系统根据策略采取行动)。哪一个action能获得的收益(Value)越大,我们就采用哪个action。所以系统总是能选择出最优的策略。
然而这种方法有一个问题,有时候系统并不能直观的获得每个action所对应的value,因为环境存在动态性。比如对一个在现实环境里行动的机器人来说,它在采取一个action的时候,有时候会碰到墙,有时候还没行动就已经摔倒了,往往不能顺利的获取action对应的value。
针对这种问题,我们定义一个新的Value function,叫做Action-Value function。它不仅是state的函数,也是Action的函数。

所以我们就不需要预测下一个state,我们只需要针对我们当前的state,看一下哪一个action可以使qπ(s,a)最大,那我们就可以选择这个action,这样我们就不需要对整个世界的动态性进行建模,所以这种方式叫做“model-free”。
3、on-policy & off-policy
在我们上面讲到的两个价值函数中,都包含有π(即policy),所以它们都是跟策略有关的。policy会影响未来的state会怎么发展,value的计算需要policy,而policy又是根据value来采取的,所以policy和value是互相影响的。所以我们把这种value受policy约束的学习方法,叫做“on-policy”。
与之对应,还有一种叫做“off-policy”的学习方法。
on-policy估计的是当前策略的value,而off-policy估计的是最优策略的value。即不再估计自己在当前状态下能达到多少回报,而是估计在最优的情况下,未来最大能拿到多少回报。

举个例子:对待同一盘围棋,我有我的value,柯洁有柯洁的value,柯洁的value很大,因为他下围棋很厉害,而我的value很小,因为我不会下围棋。即在off-policy的情况下,优化的并不是当前policy的value了,而是所有可能value的最大值,即value的优化和当前的policy没有关系,所以叫“off-policy”。
那这个value的最大值要怎样计算?

这就要采用上面的贝尔曼方程,把q*(s,a)的定义,写成一个迭代的方式。让当前state的value,通过下一个state来决定。
4、估计value的方法
上面我们说计算value实际上是不准确的,因为我们无法计算出value的精确值,只能通过估计。估计value的算法有很多,一般分为下面三个大类别,下面我们就来盘点一下这三种类别的算法各有什么特点。
Monte Carlo:
这种算法的特点是,不能在每一次state变化后就更新value,只能在一次完整的学习过程(比如一盘棋)结束后,通过获取最终的总收益(Return),再对过程中每个state的value进行更新。
它的优点是不需要对环境进行建模,即“Model-free”。
Dynamic Programming:
这种算法需要对环境建立一个完整准确的模型,这样以来系统的状态变化都是可以计算到的。再使用贝尔曼方程,通过未来的状态倒推现在的状态。然后使用Bootstrapping算法,用未来的value来更新现在的value。
Temporal-Difference Learning:
这种算法结合了上述两种方法的优点。
即不需要对环境建模(Model-free),又可以使用Bootstrapping,拿未来的value来估计现在的value。
在实际的应用中,被采用的大部分的算法都是基于Temporal-Difference Learning的。接下来我们就来重点讲一下最常用的两种算法:SARSA 和 Q-Learning 。
3
SARSA&Q-Learning算法
1、SARSA & Q-Learning 算法异同
这两种都是对Q value(即action-value function)做估计,都是迭代更新value的值。SARSA(on-policy):
这种算法是在每一次行动(Action)后,根据下一刻系统识别到的环境状态变化(state),更新这一刻的value。即Q是针对当前Policy的。

对于SARSA来说,每次的Training data是这样的:
St:当前的状态;At:当前的Action;Rt+1:这次的Reward;St+1:下一次的状态;At+1:下一次的Action。
之所以有At+1,是因为Q是S,A的函数,必须同时有下一步的State和Action才能计算这一时刻的Q value。
Q-Learning(off-policy):
这个算法不关心下一步Policy怎么选,直接挑一个能让下一步Q(S,A)最大的Action去做更新。公式中的maxQ(S', a)即代表我所有的action里,哪一个能让下一刻的Q value最大,就用它来更新Q value。

对于Q-Learning来说,Training data中不需要有At+1,因为不需要知道下一步的Action要怎样选择。
2、这还有个大问题!无法穷举的现实世界
解决方法是:我们不去估计和保存那么多的value和action,我们建立一个模型去拟合value函数,甚至去拟合policy和model。

那要如何才能做到准确的拟合?哈哈,那就需要深度强化学习出场了!
将深度神经网络与强化学习结合的技术我们统称为深度强化学习。实现深度强化学习的方法有多种,其中包括:
可以让机器人打电动游戏比人类还厉害的:Deep Q-Network(DQN)(点击阅读原文);
以及帮助 AlphaGo 选择落子策略的Policy Gradient算法;
还有荣获今年NIPS最佳论文奖的Value Iteration算法。
这几种算法各有什么区别,都有什么神通?
4
参考资料
如果想要更详细的了解关于强化学习的内容,可以参照一下的推荐参考材料:
首先推荐大家一本关于强化学习介绍的书:Sutton & Barto. Reinforcement Learning: An Introduction: classic, comprehensive, plenty of examples;
还有一些关于强化学习算法的介绍:CsabaSzepesvári. Algorithms for Reinforcement Learning: concise,theoretical
关于强化学习的最新研究:
YuxiLi. Deep Reinforcement Learning: An Overview
和一些Active researchers:
Pieter Abbeel, Sergey Levine, John Schulman, David Silver, Timothy Lillicrap, Volodymyr Mnih, Shixiang Gu
当然如果你想以一种更有趣的方式来了解强化学习,请查看来自澳洲格里菲斯大学在读博士生莫烦的《强化学习介绍系列》。
#src=2
最后,我再给大家安利一门直播的课程,作为课程质量担当的“小S”的李嫣然又一次在集智俱乐部开课,手把手教大家如何打造自己的聊天机器人。
重磅课程:打造你自己的聊天机器人|李嫣然
推荐阅读
张江:从AI高考透视人工智能进展
系列课程:从知识图谱到表征学习|集智AI学园
《深入浅出GAN-原理与应用》学习笔记|王晓宇
集智QQ群|292641157
商务合作|
投稿转载|
◆ ◆ ◆
搜索公众号:集智俱乐部
加入“没有围墙的研究所”
让苹果砸得更猛烈些吧!
内容转载自公众号

搜索公众号: 集智AI学园 了解更多

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}