目录:
Floyd介绍:一个极其易用的深度学习云计算平台
Get started:Floyb的注册、下载、登陆
关于数据集
实验: 使用Floyb训练一个基于Jupyter Notebook的项目
Flob常用命令速查表
Floyd介绍:一个便捷的深度学习云计算平台
Floyd的网址是: 它是一个云计算服务平台,号称“Zero Setup for Deep Learning”。它的服务主旨是: “您就专心于您的深度学习研究,其它的环境配置、部署、版本控制等等都交给我们来做就行了”。

从主页上我们就能看到Floyd的服务主旨。
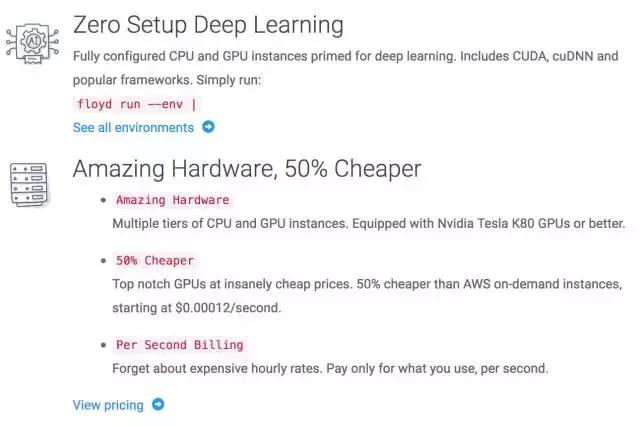
Floyd使用亚马逊云计算的硬件资源,然而价格更便宜,新注册用户可以享受100小时的免费GPU使用时间。

我简单体验了下Floyd,感觉它最突出的特点有两个:
-
不用部署深度学习环境了!Floyd为用户提供了主流框架各个版本的环境。
所有可用的环境:
-
不用上传数据集了!Floyd在云端为用户提供了现成的主流深度学习数据集,且用户上传的个人数据集可以共享使用。
常用公共数据集:
这两个特点可以说是解决了大多数机器学习研究者的烦恼。原来单单配置一个Caffe环境就好好长时间,更别提上传数据集了。我有一个做机器翻译的朋友,训练数据集多达160G,光是上传那么多的训练数据得花多少服务器时间,时间就是白花花的银子呀!现在使用Floyd只需要在启动计算环境的时候设置公用数据集的ID,就可以直接使用啦!
Get started:Floyb的注册、下载、登陆
1、注册
首先到 注册一个账号
2、安装客户端
再安装folyd客户端,就一句命令而已:
$ pip install -U floyd-cli
3、登陆
安装好后我们需要登陆,在终端中运行命令:
$ floyd login
终端中会提示:
Authentication token page will now open in your browser. Continue? [Y/n]:
回车确认后,会打开一个网页以获取身份验证令牌:
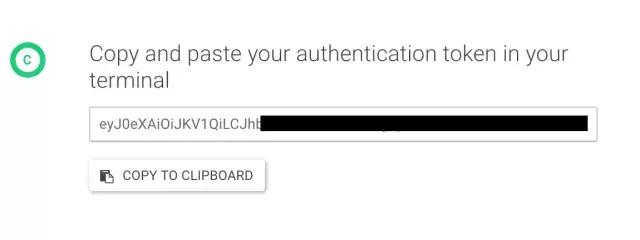
在网页的下方,你可以找到登陆用的口令,把这个口令粘贴进终端即可,注意在这里粘贴是不会显示出来的。
This is an invisible field. Paste token and press ENTER:
登陆成功后,会提示:
Login Successful
4、计算实例机制
这时候你发现没有?登陆成功后,并不是像SSH登陆那样进入到了一个新的Shell,终端还是你的终端,目录还是你的目录。
这就是Floyd的特点了,它并不像亚马逊AWS那样给你一个云主机就让你自己折腾去,而是很简洁的为你提供“计算实例服务”。
即在你login以后,怎么折腾数据集什么的都不算云服务时间,直到你通过“floyd run"命令运行自己的程序文件的时候,才算是一个计算实例的开始。
那一个计算实例什么时候结束嘞?
当你“run“的程序跑完了,计算实例的状态会变为”success“,这时候一个实例就算结束了。
如果”run“的是不会跑完的程序,比如”Jupyter Notebook“文档,那么你可以在需要的时候运行:
$ floyd stop <RUN ID>
来手动结束一个计算实例。
计算实例结束后,自动停止计算云服务器时间。
关于数据集
在运行Floyd计算实例时,可以指定计算所需的数据集,这个我们会在下面的实验中讲到。
你可以直接使用Floyd提供的常用的数据集,也可以上传自己的数据集。
上传数据集操作非常简单,你可以参考官方提供的指导,只需要几条命令就可以搞定,非常方便。
同时Floyd也支持直接在云服务器上下载数据集,不过这个是要计算云服务时间的。
不管是公共数据集,还是自己的数据集,都是通过数据ID来指定的。
你可以通过以下方式查看公共数据集的内容:
$ floyd run --data GY3QRFFUA8KpbnqvroTPPW "ls -la /input"
Syncing code ...
...
$ floyd logs -t GY3QRFFUA8KpbnqvroTPPW
...
2017-02-16 03:41:15,863 INFO - -rw-r--r-- 1 root root 4151 Feb 16 11:38 positive_sentences.txt
2017-02-16 03:41:15,863 INFO - -rw-r--r-- 1 root root 4621 Feb 16 11:38 negative_sentences.txt
2017-02-16 03:41:15,863 INFO - -rw-r--r-- 1 root root 7797 Feb 16 11:38 neutral_sentences.txt
...
实验: 使用Floyd训练一个基于Jupyter Notebook的项目
我将使用Floyd提供的一个基于Jupyter Notebook的小项目来演示使用方法。你可以在这里找到官方的指导:
1、Clone 项目代码到本地
$ git clone
2、进入项目目录
$ cd tensorflow-notebooks-examples/3_NeuralNetworks
3、初始化项目
$ floyd init neural-networks
Project "neural-networs" initialized in current directory
初始化后,Floyd会在本目录里生成一些临时文件,以便运行计算实例时,上传目录中必要的程序文件到云服务器。
4、启动一个Jupyter Notebook实例
以下命令将启动一个基于当前目录的,运行在云端的Jupyter Notebook计算实例。
$ floyd run --mode jupyter --env tensorflow-0.12:py2 --data R5KrjnANiKVhLWAkpXhNBe --gpu
其中:
--gpu 代表使用GPU计算
--env tensorflow-0.12:py2
代表使用Python2.0版本的Tensorflow0.12
--data 代表我们使用这个ID所代表的数据
注意数据包含的所有文件都会挂载在云服务器的“/input“文件夹下
所以在程序中需要指定数据的根目录为“/input”
命令运行后,终端中会有类似于以下的提示:
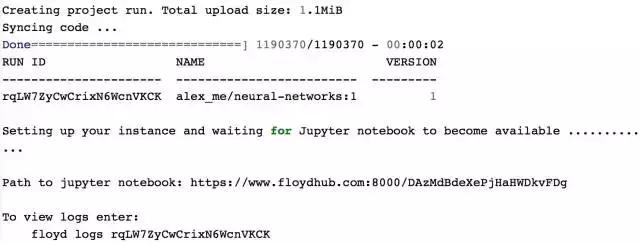
通过给出的“Path to jupyter notebook”,就可以访问刚刚启动的Jupyter Notebook实例了。
注意上面的“RUN ID”,这个很重要,我们以后对这个运行实例进行的各种操作,都需要通过这个ID来完成。
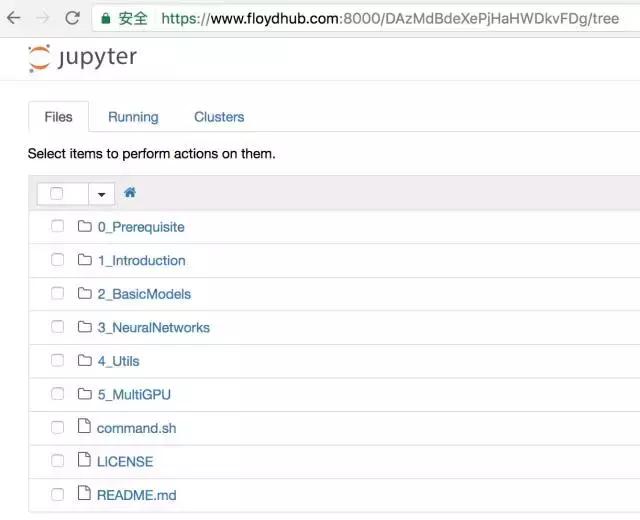
5、操作并保存
你可以像在本地一样在Jupyter Notebook里进行操作和计算。请记得一定要保存操作后的Jupyter Notebook。
我们操作的Jupyter Notebook都在云服务器上,那要怎么将修改后的Jupyter Notebook保存到本地哪?
Jupyter Notebook是在实例结束后,以output的形式保存下来的,我们稍后说明如何导出修改后的Jupyte Notebook。
6、停止Jupyter Notebook实例
当你使用Jupyter Notebook工作完毕后,记得要关闭云服务器计算实例。
$ floyd stop <REPLACE WITH YOUR RUN ID>
可以通过下面的命令确认实例关闭情况:
$ floyd status
7、通过output导出Jupyter Notebook
计算实例的输出一般都会定位在云服务器的“/output”文件夹下,所以你在程序中,需要将所有的输出数据的根目录定位在“/output”。
我在上面说到Jupyter Notebook文档本身也是通过output来导出的,你可以通过下面的命令来执行:
$ floyd output <REPLACE WITH YOUR RUN ID>
命令执行后会打开浏览器,自动进入到云服务器的数据目录,你只要选择需要下载的文件即可。
Floyb常用命令速查表
登陆: floyb login
初始化目录: floyb init
查看数据集:floyb data output
运行实例: floyb run --gpu
查看实例日志: floyb logs
查看所有实例: floyb status
手动停止实例: floyb stop
查看实例运行结果信息: floyb info
查看输出数据: floyb data output
查看输出数据: floyb output
所有命令,请参考:
所有环境,请参考:
常用公共数据集,请参考:
/guides/datasets/
上传和下载数据集的官方指导,请参考:
下期预告:
有很多深度学习的项目并不是在Jupyter Notebook中编写的,对于这些项目我们通常直接运行Python文件。那么怎么在Floyd中直接运行Python文件?如何验证训练完成的深度学习模型?下期我们将继续为大家介绍Floyd的使用方法,敬请大家关注!
通晓了Floyd的使用方法
还不赶快找个项目练练手?
不知道跑什么模型?
搭建一个属于自己的聊天机器人怎么样?
集智AI学园特推出重磅课程!
香港理工大学的美女博士手把手教你搭建一个聊天机器人!
重磅课程:打造你自己的聊天机器人|李嫣然
可开发票
团购可享优惠
咨询详细课程内容
请添加集智AI学园园长微信cancyqian
推荐阅读
集智课程推荐|厉害了我的GAN
深入浅出解读GAN!
《深入浅出GAN-原理与应用》学习笔记|王晓宇
系列课程:从知识图谱到表征学习|集智AI学园
关注集智AI学园公众号
获取更多更有趣的AI教程吧!
搜索微信公众号:swarmAI
集智AI学园QQ群:426390994
学园网站:
商务合作|
投稿转载|

 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}