阅读:0
听报道
文| Matthew
1.图数据中蕴藏着秘密
事物之间的关联信息,人类已经积累了很多,但绝大多数人不知道如何利用它们。
社交媒体中的互动和关系网络图中,蕴含着深意。像WordNet这样的同义图表能够通过计算机视觉,帮助我们更好地理解和识别特定情形下研究对象之间的联系。从家谱到分子结构,我们周围世界中海量的信息都以图的形式呈现。
尽管普遍存在,图结构(Graph Structure)在机器学习的应用方面还是经常被忽视。比如“时尚潮流推荐问题”,其目标在于发现特定的能够形成凝聚趋势的一些衣服形式,也就是“风格”(style)。通常的做法是从社交媒体抓取图片并识别这些图片中的衣服,然后用这些图片的流行程度代表特定“风格”服装的流行程度。用这种方式去了解流行样式风格当然可行,这个模型能够轻易地通过图数据获得优化。比如,我们可以分析用户社交网络中潮流趋势,或者提取马逊购物网站中的“相关联产品”的集合目录。
那么,为什么结构化的信息经常被忽视呢?因为多数情况下,从这些图表中提取有效的特征实在是个巨大的挑战。
在本文中,我们将探索一些从图数据中提取有效特征的新技术。特别地,我们将重点讨论那些利用随机遍历方法,来量化图中节点之间的相似性。这些技术主要依靠自然语言处理群体的现有结果。我将建议一些未来的研究途径,特别是与时变图形的学习特征有关。最后,我们将简要讨论图卷积网络 (GCNs) 的大家族,它提供了一个在图结构数据上进行机器学习的端到端的解决方案,而无需单独的中间特征提取步骤。
这些方法本身就构成了机器学习的一个子领域,但是研究人员和从业者可以从他们感兴趣的特定范畴的结构中获益。

2.基于图的特征学习
2.1 图摘要的计算

DeepWalk(2014) 和 node2vec(2016) 正是学习上述特征向量的两个算法。下面我们就一起来看一下这两个算法是怎么工作的吧。

2.2 DeepWalk:将随机游走看做句子?
DeepWalk算法[1]背后关键的思想是,图中的随机游走(random walks)和句子很像。经验发现,句子中的单词和一个真实世界中图上的随机游走均服从幂律分布(power-law distribution)。也就是说,我们可以把这些随机游走路径想象成某种“语言”中的“句子”。



2.3 Node2vec:泛化到不同类型的邻域
Grover and Leskovec (2016)[3] 将Deepwalk算法拓展成为node2vec算法。与deepwalk算法不一样,我们不再根据现有的结点运用一阶随机游走(first-order random walks)选择下一个节点,node2vec不仅基于现有结点,还会使用现有结点前面的那一个结点,从而使用一系列二阶随机游走。

这篇论文的关键想法是通过选择不同模式的二阶随机游走,我们可以提取到网络图的不同特性。
为了证明它的必要性,作者们在文中给出了两种在网络图上做机器学习通常使用的邻域类型:(节点颜色代表类别 )
在同质性假设下,由于高度连接的节点在网络图里位置相近,因此它们属于同一个邻域。
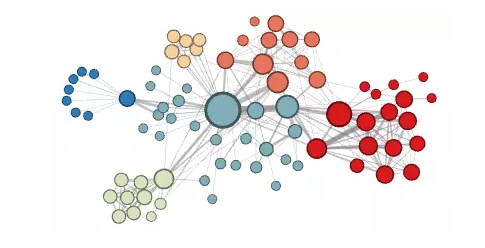
在结构性假设下,承担着相似结构性功能的节点(比如说,网络的所有中心节点)由于他们高阶结构性显著度,它们属于同一个邻域。
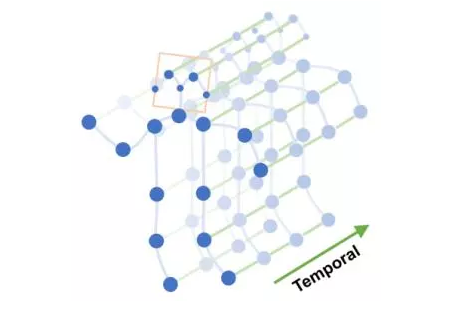
2.4 时变网络(temporal networks)中的潜在特征
这些图摘要技术很有用,但现实世界中很多图是随着时间变化的时变网络。比如,社交网络中一个人的朋友圈图会随着时间发生扩张或者收缩。我们可以使用node2vec,但是有两个缺点:
每次随着图的改变而运行一个新的node2vec实例很耗算力
其次,难以保证多个node2vec的实例能产生相似的甚至是可比较的F矩阵
对于第一个问题,有一个解决方法--每次网络改变后不立即运行node2vec,而是直到足够多的边发生改变使得原始嵌入的特征矩阵F质量下降再运行。
那么多少条边发生改变才可以被认为发生了“显著”的变化呢?这高度依赖于图中特殊的边和随机游走中的(p, q)两个参数。
观察下面这些图:

在某种程度上,第二个问题可以通过连接从多个node2vec实例得出的特征,然后训练一个自动编码器,把这些综合特征映射成压缩的表示。
如何实现时变网络上的可扩展特征学习呢?对于时变网络,一些工具可以用于图嵌入的增量更新,比如Abraham et al.(2016)[4]提出的动态频谱稀释器。这方面仍然有大量工作需要做,即使是最好的稀释器也因为速度太慢而难以实际应用于现实世界中的图,即使存在亚对数算法,算法的常量因子也非常大。我相信,结合动态图分割技术和更新图摘要矩阵F对于时变图的特征摘要来说或许是一个可行的方法。
另一个可选的方法是泛化node2vec算法到时变网络,通过添加一个额外的参数λ,影响随机游走经过“时变边界”的概率。有些预测任务中可能有“时变位置”的概念,其中有着相似时间戳的图的快照是相关的,而其他的或许有更久的依赖关系。
接下来我们开始介绍图卷积网络,一种最近提出的网络图上机器学习的方法。
3.图卷积
Node2vec和DeepWalk的方法都是先生成“语料”然后用于后续的机器学习技术。相比之下,图卷积(GCN)则是展示了一种端到端的方法进行结构化学习。
GCN尝试将传统的卷积神经网络推广到可变的、无序的结构中。由于图没有明确定义的顺序,因此节点的排序不应该对GCN产生影响。很显然,CNN并没有这个特性,因为随机交换图像像素矩阵的行和列,再输入给CNN必然会改变计算的输出(通常,用于视觉问题的CNN,在识别图像中的边缘或其他局部结构时,其输入在不同的行列置换下,计算结果并不是一成不变的)。
此外,CNN对像素邻域的形状并不是不可知的,换句话说,并没有明显的方式可以训练一个CNN同时接受在正方形和六边形网格上定义的图像,即一个内在像素分别具有八个和六个直接邻居。因此,为了解释一般图的动态结构,必须对CNN的激活函数(activation function)进行合理的松弛(relaxations)。
很多作者提出了不同的GCN松弛(relaxations)方法。其中一篇文章[5]定义了一种和CNN类似的方法,该方法优化了稀疏过滤器,而过滤器在多个尺度上对图进行聚类操作。这篇文章还提出了CNN的谱近似方法,CNN中多个谱过滤器作用在对应最大特征值的特征向量上。另外一篇文章[6]提出了一种和CNN更新具有相同的时间复杂度的GCN更新方案,即对谱过滤器只进行低度的多项式近似。还有一篇文章[7]通过使用多个线性谱过滤器简化了GCN的公式,这些过滤器可以共同捕捉高阶特征。
这些图卷积网络公式本身就很有趣,需要更多篇幅来详细描述。GCN作为之前章节描述的图处理方法的合理替代方案已经显示出了前景。GCN的完全可微分的特征也使得其稀疏过滤器能够成为端到端学习算法的一部分。虽然node2vec的偏置超参数(p, q)允许发现更多个性化的特征,但是GCN的权重矩阵也可以根据提供的训练数据进行调整。
结构化学习已经被应用到生物化学领域,文章[8]提供了一种端到端的和全微分的神经网络来预测基于稀疏原子结构的蛋白质-配体亲和力。另一篇论文[9]用GCN解决了药物发现问题,并引入了一个虚拟的“超级节点”,该虚拟的“超级节点”通过有向边连接到候选药物图中的每个节点,以便得到图特征。
GCN也已经成功应用在知识图[10]的链接预测和实体分类等方面。最近出现的结构化学习的成功和快速的研究在未来几年还会有更多。也许我们很快就会看到利用关系结构如知识图的GCN网络来提高计算机视觉中物体检测的性能,也或许,通过结构化学习方法能够加速蛋白质折叠模拟,从而大大降低原子度低的三维蛋白质的维度等等。这些应用几乎可以肯定将会出现(如果尚未发布的话),这当然使得结构化学习成为一个令人兴奋的领域。
4.参考文献
[1]Rami Al-Rfou "DeepWalk: Online Learning of Social Representations[J] knowledge discovery and data mining, 2014: 701-710."
[2]Tomas Mikolov "Efficient Estimation of Word Representations in Vector Space[J] arXiv: Computation and Language, 2013."
[3]Aditya Grover,Jure Leskovec "node2vec: Scalable Feature Learning for Networks [J] knowledge discovery and data mining, 2016: 855-864."
[4]Abraham et al."On Fully Dynamic Graph Sparsifiers.[F] New Jersey, USA, 2016, pp. 335-344."
[5]Bruna, Joan, et al. "Spectral networks and locally connected networks on graphs. arXiv:1312.6203"
[6]Defferrard, Michaël, Xavier Bresson, and Pierre Vandergheynst. "Convolutional neural networks on graphs with fast localized spectral filtering. arXiv:1606.09375 [cs.LG]"
[7]Kipf, Thomas N., and Max Welling. "Semi-supervised classification with graph convolutional networks. arXiv:1609.02907 [cs.LG]"
[8]Gomes, Joseph, et al. "Atomic convolutional networks for predicting protein-ligand binding affinity. arXiv:1703.10603 [cs.LG]"
[9]Li, Junying, Deng Cai, and Xiaofei He. "Learning Graph-Level Representation for Drug Discovery. arXiv:1709.03741 [cs.LG]"
[10]Schlichtkrull, Michael, et al. "Modeling Relational Data with Graph Convolutional Networks. arXiv:1703.06103 []"
本文由集智翻译组整理自
翻译:王昕哲\薛亚飞\张洪\彭智勇\辛茹月
审校:龚力
编辑:集智小风
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}