
2018年11月7日,集智俱乐部与腾讯研究院联合邀请世界知名计算社会科学学者、美国芝加哥大学社会学教授、Knowledge Lab主任、芝加哥大学计算社会学硕士项目创始人James A. Evans博士,作为AI&Society沙龙第十二期的嘉宾,带来一场精彩的主题演讲。
扫秒上方二维码,或登录网址,看现场实录:
从推理到预测——计算社会科学的革命

James的演讲从社会计算开始。James具体解释了什么是计算社会科学、计算社会科学意味着什么——使用电脑来生成数据、发现模式或者产生和检验解释——没有电脑你根本无法实现过程。这也标志着计算式研究的设计、方法和理论标准的转变。
2009年,以哈佛大学的David Lazer、麻省理工学院的Alex Pentland等为首的十六位科学家联合在著名期刊《Science》上发表了题为“计算社会科学”一文,标志着这一新型交叉学科的诞生。
2009年经典文献:计算社会科学

仅从题目上来看,计算社会科学与2000年前“基于agent模型的社会学仿真与人工社会的研究”并没有什么本质区别,但二者最大的不同就在于,计算社会科学更加强调运用大数据的手段去获得第一手的社会调查材料。
客观来说,我们可以通过实验、观察、档案馆、调查和模拟来获得大数据。事实上,大数据研究在罕见但社会意义重大的事件中极为重要,例如引发集体注意力的流行事件、网络连接的搭建、新奇的行为或表达以及频次分布的尾部事件等。
计算社会科学带来了一场社会数据获取和分析的革命,意味着人们可以使用自然语言处理、机器学习方法处理海量的文本、语音、图片、网络等,也可以建立高维的模型,实现高效的计算。
从理论意义上来看,小数据需要强模型来解释一个具体的现象,而大数据只需要弱模型,因为你可以通过多个数据集来发现一个普遍的模式,在这个过程中你可以从多个模型中作出选择。
同样,在实验设计中,我们也不再受时空限制,可以获得优化后的样本。按照社会科学的认知论,“如果没有生成它,我们就不相信它”。从“必要但不足够”到“足够但不必要”,从社会科学到社会技术,从因果推测到预测,从降低误差到平衡误差,这些都是计算社会科学所带来的转变。
从购书行为
大数据看到了政治偏好
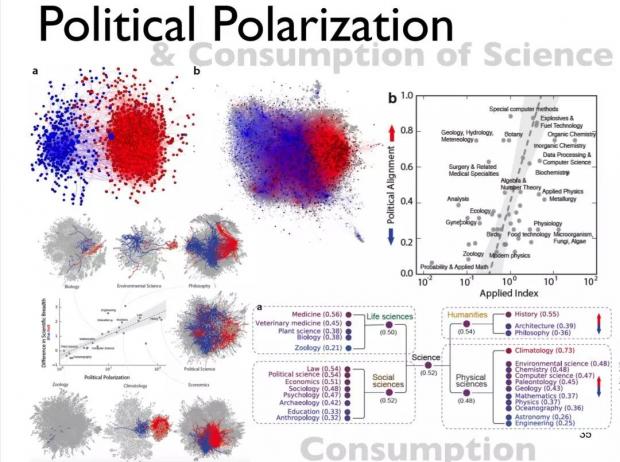
为了更好地理解计算社会科学的解释和预测作用,James从政治偏好的角度切入,通过一个实证案例帮助我们理解政治偏好和科学消费之间的关系。
在这个案例中,研究者使用了亚马逊网站上人们对不同书籍的购买记录,分析科学书籍与不同党派观点的(保守/自由)书籍之间共同购买的联系,也就是探究科学和政治之间的关系。
为了完整的描述科学与意识形态的关系,我们设计出了三种测量:政治关联(Political relevance),政治取向(Political alignment),以及政治极化程度(Political polarization)。政治关联描述科学与政治的远近(不分左右意识形态)。政治取向定义为某一学科的读者更多选择保守主义还是自由主义的书籍。政治极化程度用来测量某一学科内部的分化程度。
研究发现,相对于一般读者,购买科学书籍的读者更愿意购买政治类书籍,而科学与政治书籍之间较高关联主要取决于社会科学,而生命与物理科学与政治关联较弱。其次,自由倾向的书籍共同购买的科学书籍更为广泛,而保守倾向的书籍共同购买的科学书籍分布相对集中。在科学类书籍的不同子科目下,发现气候类、医药类、法律类、历史类的书籍政治取向更为保守,而工程学的书籍政治倾向更为自由;自由派偏爱基础科学,保守派偏爱应用科学。
通过可视化分析与不同学科子类下不同倾向的政治书籍共同购买的科学书籍的分布,发现:在哲学学科下,不同倾向的政治书籍共同购买的科学书籍差异极大;在经济学科下,保守和自由倾向的政治书籍共同购买的科学书籍最为相似。
除了科学的消费,还有文化层面上的消费。为什么自由主义者更喜欢喝拿铁?一个人的服装、饮食都有可能和他的政治偏好相关,这些相关性究竟对我们有没有帮助呢?可以帮助我们更好地决策吗?这些都是我们关心的问题。
大团队,小团队,
真正的创新来自哪里?
大团队,小团队,
真正的创新来自哪里?
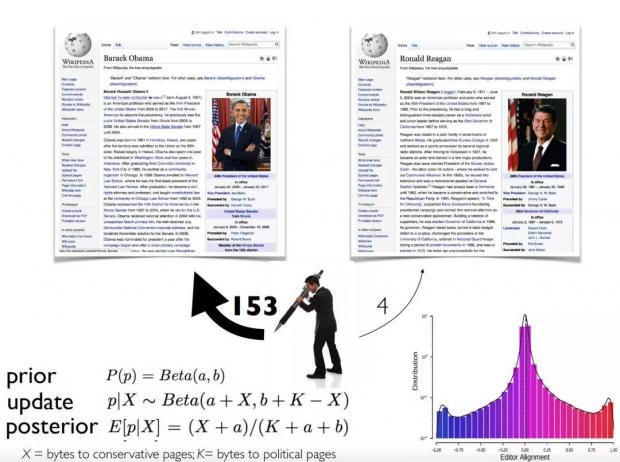
James还分享了和团队相关的一些有趣的研究。团队里不同党派的成员之间能够更好的合作吗?团队里有更多的女性、倾听者会有帮助吗?James表示,我们可以在维基百科的语境下研究团队的问题。
如果一个人写了153个保守类的页面,却只写了4个自由类的页面,那么他就更有可能具有保守派的意识形态。James 等人发现,编辑团队的多样性、极化程度越高,页面的质量也会越高。这背后的原因是,他们会在Talk版面会进行很多的信息交换,提供更多的证据来支持自己的观点。
那么,小的团队还是大的团队更擅长创新?
Web of Science数据库在一百年(1915-2015)间记录的四千四百万论文数据、美国专利数据库中在四十年(1975-2015)间记录的五百万专利数据、GitHub数据库在三年间记录的一千六百万开源代码的数据,它们涵盖了人们在科研、技术、开源代码三个领域中,相对不同的组织关系与知识生产方式。分析这三大数据库发现,在团队规模增大过程中,团队引用最新的论文随之增加,而引用历史较久的经典论文随之减少。
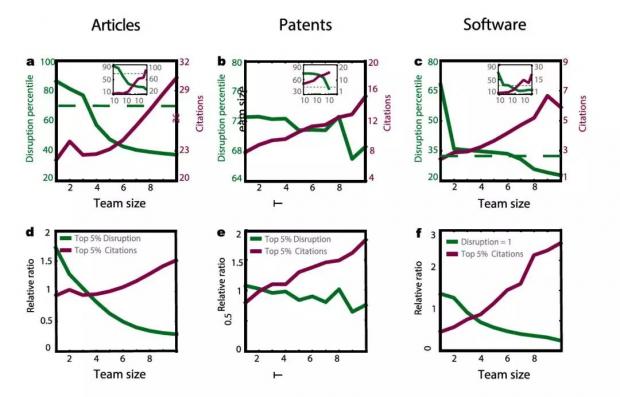
由此James得出结论:大团队偏向引用新文献,聚焦于流行的研究。小团队在研究过程中,对过去的文献追溯更深、思考更深入,从而能够提出新想法,实现“颠覆性”创新。
简而言之,小团队在创造新的方向,而大团队在发展这些方向。换个说法,小团队擅长提出问题,而大团队擅长回答问题。
未来,计算与社会彼此融合
未来,计算与社会彼此融合
最后,James以一幅漫画来结束他的演讲。世界上有许多不同的巨人,而最好的方式是把他们分开。极化会促进竞争,极化会调动积极性,极化也会使人精疲力竭。

不平衡的极化是危险的,平衡的极化是安全的。计算可以帮助我们理解社会事件,社会也能够让我们更好了解计算,社会和计算彼此融合。
无疑,随着计算社会科学的兴起,未来是振奋人心的。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}