阅读:0
听报道

导语
随着硬件和技术的同步发展,我们收集和分析数据的能力也逐步提高。新兴的人工智能分析技术,助力于我们更快的感知社会经济发展态势。然而同时,海量数据带来的信息过载,让我们重新审视传统经济学中完全信息的假设。把“信息”要素纳入经济解释分析框架,为开创新信息经济理论奠定了思想基石。

数据时代下,在很多传统学科(例如社会学、经济学、教育学)都面临重大方法论的变革——从定性分析过渡到半定量分析,最终走向定量分析。在数据驱动的社会经济研究背景下,新的交叉学科研究方向——计算社会经济学(Computational Socioeconomics)应运而生。
传统的方法感知社会和经济发展状态,主要依赖于大规模的社会经济普查。然而,普查数据的获取耗时费力,往往有很长时间的滞后。另外,很多经济不发的国家和地区,信息系统不够完善,也无力财力支撑大规模普查。
近年来,新数据的获取和新方法的应用,促进了计算社会经济学的发展。一方面,大规模社会经济数据(包括:卫星遥感、手机通讯、社交媒体等),拥有低获取成本、实时更新和高时空分辨率等优势。另一方面,统计分析和计算方法的进步(包括:机器学习、网络分析、文本挖掘等),提升了对发展态势的预测能力。
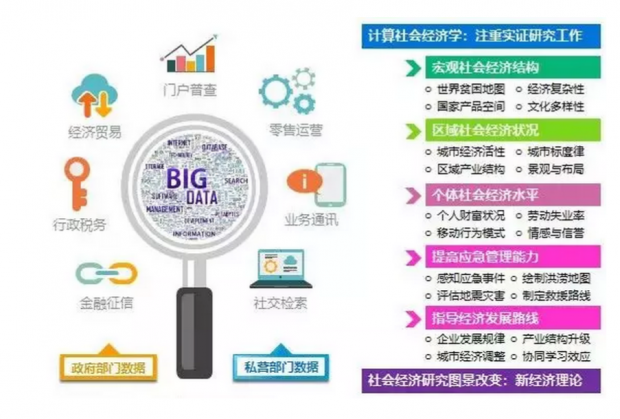
依靠数据来驱动社会经济洞察,计算社会经济学致力于精准及时感知社会经济发展状态,更好地揭示社会和经济现象。
计算社会经济学的研究内容,主要涵盖三个层面(国家社会经济状况、区域/城市经济结构、个人社会经济属性)和两个应用(应急和灾害管理、发展和升级策略)。
宏观社会经济发展状况
高分辨率卫星遥感图像有很短的更新周期,为感知全球经济发展状况提供了新数据。利用捕捉夜间光亮的卫星图像数据,结合高分辨率的LandScan人口数据,使用统计方法估计国家和区域的社会经济状况,以此绘制出世界贫困地图,提高对全球贫困问题的及时感知。
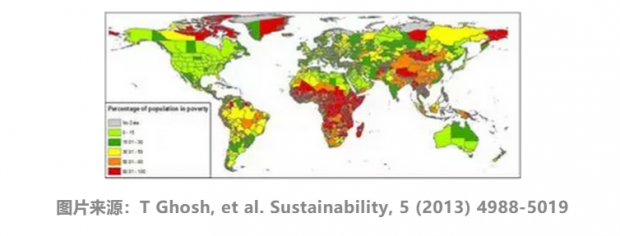
进一步,利用卷积神经网络识别白天和夜间的高分辨率卫星图像特征,最好情况下能以高达75%的准确率解释区域社会经济状况。新的机器学习方法(ImageNet -> Transfer Learning -> Ridge Regression),只需利用公开卫星图像数据,就能及时追踪发展中国家的贫困状况。
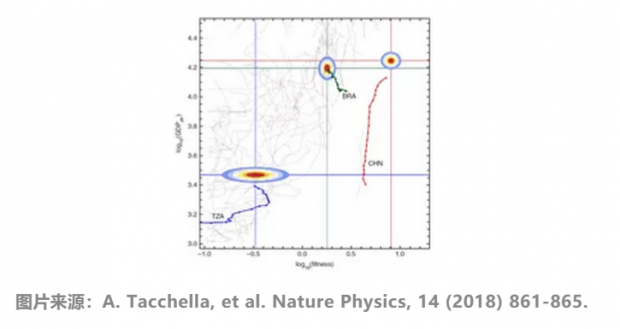
基于国际贸易数据,构建二部分网络,通过分析网络结构特征来刻画全球经济复杂性。提出的经济复杂性指标(ECI)与收入水平非常相关,能预测国家未来的经济发展。类似的,基于贸易数据还能计算Fitness指标,并将经济发展表示为二维动力系统。提出的预测模型,对人均GDP的预测能力高于IMF传统方法。
区域社会经济结构
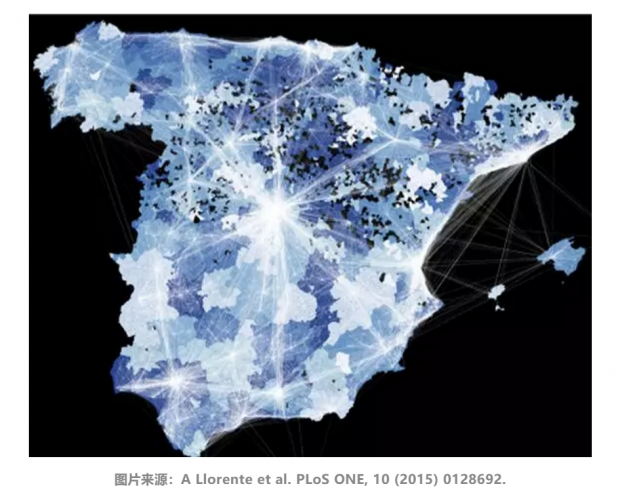
随着信息通信技术的发展,不同地域的沟通和交流变得更容易。基于千万量级的电话通讯数据,构建区域之间的社会关系网络。分析发现,区域经济发展水平与社会网络结构密切相关。特别的,地区在社会网络中的通讯多样性,与其经济发展水平的关联性高达0.73。
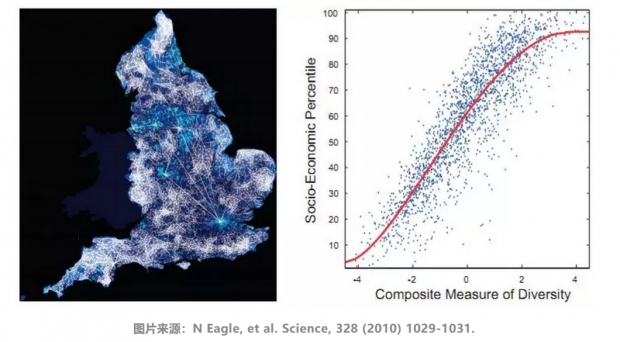
基于微博数据构建信息流动网络,基于简历数据构建人才流动网络。分析发现,信息流动和人才流动网络的结构特征,对经济发展状况都有很好的预测能力。基于两个网络特征构造的复合指标,能够最大程度上解释~84%的经济状况变化。
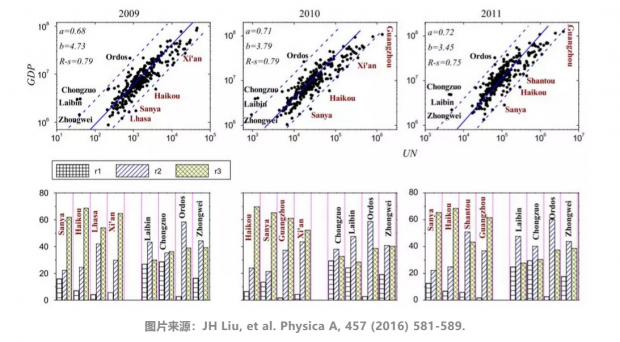
通过分析在线社交数据,还观测区域经济结构。分析超过2亿微博用户的注册数据,发现在线社交活跃度与经济发展状况非常相关。经济发展高于社交活跃度预期的城市,第二产业发达;经济发展低于社交活跃度预期的,第三产业发达。
城市景观和布局
如果不翻看统计年鉴,我们感知一个陌生城市的社会经济状况,最直接的方式就是搭一辆出租车,在这个城市里转几圈走走看看。把这个过程搬到线上成为街景“比一比”平台,让参与者每次比较两个城市的一个特征:安全、社会阶层和独特性。
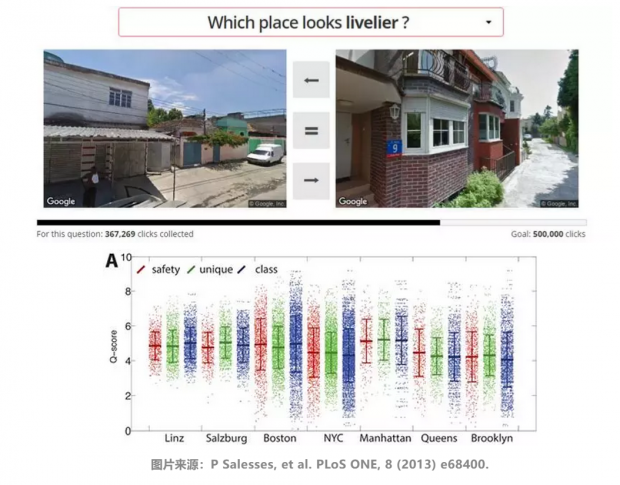
基于用户对几千张街景图片的打分,利用机器学习算法预测大规模街景的评分。进一步,定量刻画化城市街景所带给人们的感受,将城市的景观感受与社会经济发展状态联系起来。结果发现,美国的城市比奥地利的城市有更大的发展不平等性,街景测量的安全性评分与犯罪率非常相关。

城市的物理景观环境不是一成不变的。那么,哪些因素能够促使城市环境变好呢?
通过对比同一地点在不同时间的街景图片评分变化,发现能够驱使城市安全性改善的三个因素:
好的初始环境
到经济中心的距离近
受过大学教育的人数多
个体社会经济水平
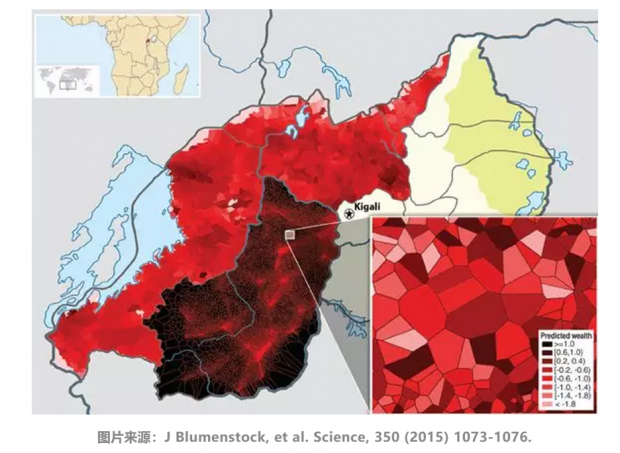
利用手机记录的通话情况、社会通讯网络、移动轨迹等数据,能建立预测个人收入的模型。使用卢旺达小规模的问卷数据训练模型,能预测超过150万人口的财富情况,并绘制高分辨率的财富分布地图。手机通讯数据还能计算个体社会网络影响力,并以此来准确推断其社会经济状况。
基于企业内部的在线互动平台数据,构建员工之间的社交和工作网络,计算员工在网络中所处的位置。
结果发现,处于网络核心位置的员工更容易在未来升职,处于网络边缘位置的员工更容易在未来离职。由此,可以构建模型,较好的预测员工升职和离职可能性。
利用手机和社交媒体数据还能推断个体和群体的失业率。当大规模裁员时,附近手机基站的通话量急剧下降。当员工失业以后,他们社交媒体的沉浸程度增加,早上的活跃程度降低,推文的错拼率上升,移动的多样性降低。所以,能通过分析社交网络数据来推断失业人口。
应急管理和抢险救灾
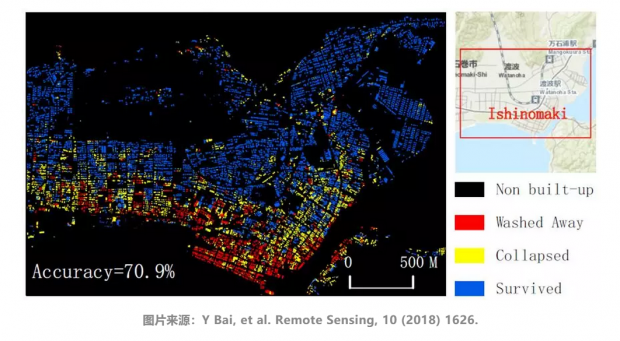
基于地震灾害前后的高分辨率卫星图像数据,利用机器学习算法提取图像特征,从而评估地震灾害情况。针对2011年日本东北地方太平洋近海地震,提出的算法可以识别一个城市遭受灾害的程度,对灾情分类的准确性达到70.9%,包括倒塌、冲走和安然无恙等。
手机数据能够追踪人类移动,可以帮助理解灾害发生后,人类避难迁徙的距离、路径和地点。基于手机数据分析2010年海地大地震后人口的迁移情况,发现受灾群众短期内迁移到平时有社会联系的地方。遭遇灾难后的人群移动模式,仍然有相当程度的可预测性。
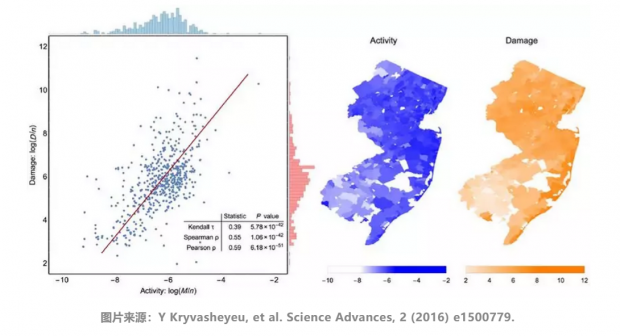
利用社交媒体数据,能够更快速的感知灾情和经济损失。基于推特数据,分析2012年Hurricane Sandy对用户线上活跃程度的影响。结果发现,飓风相关的推文数量在飓风登陆日达到最大。单位面积的飓风相关推文活跃程度,与飓风所造成的经济损失非常相关。
产业发展路径和策略
基于中国上市公司注册信息数据和巴西千万量级人力资源数据,能够刻画区域产业结构,即“产业空间”。产业空间中,接近性大的产业彼此相连,接近性小的产业相隔较远。产业空间具有“中心-边缘”结构,复杂性高的产业占据中心(如制造业),复杂性低的产业占据边缘(如农业)。
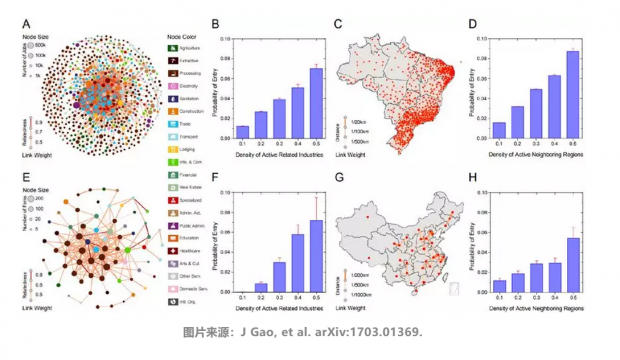
新产业出现和发展,存在两条学习路径。其一是相近技术学习,自身的相似技术产业越多,越容易发展。其二是近邻区域学习,有相同技术的邻居越多,越容易发展。这种学习规律具有普适性,比如相关的产品和研究领域越多时,越有可能在未来发展相应的产品和研究领域。
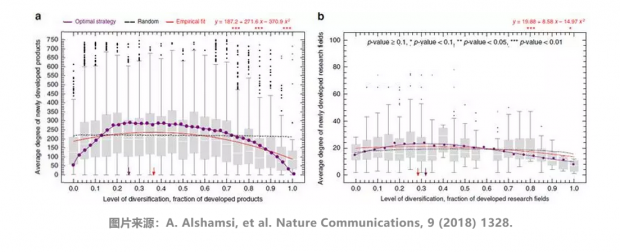
在发展经济时,由于产业空间特殊的“中心-边缘”结构,存在最佳时机去发展处于核心的复杂产业。核心产业周边有很多接近的产业,非常不容易被激活。一旦被激活,又能带来非常大的收益。随着经济不断发展,有最佳时机(一般比预期要早)来激活核心产业,加速经济发展。
本文整理自高见博士在 AI&Society 第十三期上的讲座,
PC端观看地址:
作者:高见
编辑:王怡蔺
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}