阅读:0
听报道

今天凌晨,在 YouTube 和 Twitch 上播出了一系列星际争霸 II 游戏比赛中,谷歌子公司 DeepMind 开发的人工智能系统 AlphaStar,连续10场比赛击败人类。
星际争霸 II 是著名的即时战略游戏,这是人工智能在该项赛事中首次与人类顶尖职业选手对战,并取得压倒性胜利。
谷歌放出了两个系列共10场对战视频录像,这10场比赛2018年12月进行的。在这两个系列中,AlphaStar 分别与人类职业选手 MaNa和 TLO 的对战,都已5:0的战绩横扫人类玩家。
最受瞩目的,是今天 AlphaStar 和人类选手 MaNa 的一场直播比赛。比赛中 AlphaStar试图将整个军团作为整体推进,横扫 MaNa 的基地。但 MaNa 在 AlphaStar 基地后方反复骚扰,获得足够的建造时间。虽然 MaNa 曾经被 AlphaStar 多次击败,但在 AI 面前,人类也有学习能力。
尽管 MaNa 发现了 AlphaStar 的漏洞,获得了人类玩家的唯一一次胜利。但 AlphaStar 已经与另一位职业选手 TLO 在比赛中,取得了5:0的完胜。只能说这是挽回颜面的一局。
全部比赛过后,AlphaStar 在星际争霸 II 中与人类对抗的总战绩是10:1。
DeepMind 研究员 David Silver 在赛后表示,人工智能已经在不同游戏中取得许多标志性的胜利,此前包括国际象棋、围棋、Dota2 等。未来仍有大量工作要做,但将来人们回顾今天,也许会认为这是人工智能跨出的重要一步。
在实时影像类电子游戏中击败人类似乎跟人工智能的主要功能无关,但这是一项重大的研究挑战。类似星际争霸 II 这样的游戏,对于电脑来说比棋盘游戏难度更高。
在星际争霸 II 中,人工智能无法观察所有物体的移动从而计算后续行动,而是被要求和人一样,只能通过观察屏幕视域内的物体移动,来做出实时反应。
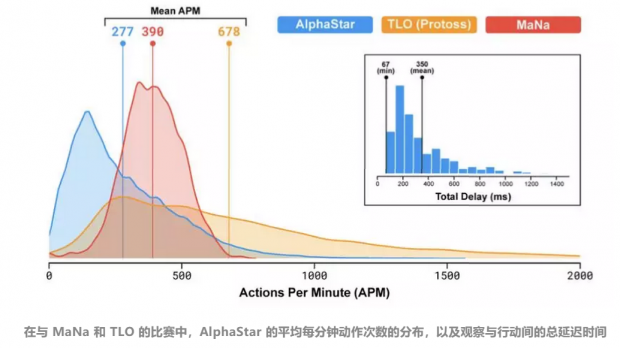
TLO 和 MaNa 等职业玩家平均每分钟可以做出数百个游戏动作,但这比现在多数机器人要弱。为了提高系统的反应准确性,AlphaStar 平均每分钟发出的动作只有280次,这比人类职业玩家还要低。原因是 AlphaStar 模仿了人类玩游戏的方式。此外,AlphaStar 的观察和行动之间的平均延迟时间为350毫秒。
但这些没有成为难倒 DeepMind 人工智能系统的障碍。AlphaStar 使用深度神经网络学习星际争霸 II 的完整游戏视频,利用原始游戏数据,以监督学习和强化学习的方式进行训练。
AlphaStar 还使用了多体智能算法(multi-agent learning algorithm)。研究者为智能体(agent)设置了目标(获胜或者仅仅活着),首先通过模仿人类玩家来学习,然后让智能体相互比赛,最强的生存下来,最弱的被淘汰。

DeepMind 估计,AlphaStar 通过强化学习的方式,已经积累了大约200年的游戏训练时间!
与人类玩家在游戏中对抗的目的并不是在游戏中击败人类,而是为了提升 AI 训练方法,更是为了尝试在类似星际争霸游戏这样的复杂虚拟环境中,建立可运行的 AI 系统,最终实现可以执行任何人类任务的通用人工智能。
因此,重要的不是击败人类,而是通过比赛对 AI 的任务表现进行基准测试。
而 AlphaStar 的这次比赛并非终点。参赛的 MaNa 和 TLO 两位选手虽然是职业选手,但仅仅是优秀职业选手,而非冠军级别。
2月15日,世界冠军芬兰职业电竞战队 ENCE,将向最强 AI 发起挑战!
参考资料:
DeepMind 技术博客:
AlphaStar游戏视频全程录像:
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}