阅读:0
听报道
导语
根据奥卡姆剃刀原则,好的模型即便是在高阶的条件下也应使用最少的假设,推导出可泛化的结论,从而使得模型的适用范围超过最初建模的情景。
1. 从传统模型到高阶模型
近期《Nature Physics》刊登了一篇Perspective(观点)类型的文章,摘要如文章标题一样短小精悍。下图的短短两句话中,除了high order(高阶)之外,还有两个关键词,读者可以先思考:

题目:
From networks to optimal higher-order models of complex systems
地址:
摘要:
Rich data are revealing that complex dependencies between the nodes of a network may not be captured by models based on pairwise interactions. Higher-order network models go beyond these limitations, offering new perspectives for understanding complex systems.
pairwise
第一个关键词是“pairwise”(成对),传统的复杂网络由点与边构成,所有的实体都属于同一类,意思是其数据是不管是用有向图还是无向图表示,都只表示为点与点之间的两两关系。如果点A与C之间存在关系,那么隐含条件就是点A与点B,点B与点C之间分别存在联系。换句话说,模型假设A与C的关系可以分解为A到B、B到C的关系,且其中A→B,B→C这两个过程是相互独立的。
很多基于复杂网络的研究案例,例如根据一个网络中点的中心度(centrality)对网络中点的重要性进行排序,或者计算网络中的群落(community),都是基于这个假设之上。
例如,如果我们希望通过国际贸易的复杂网络建模来了解中国在全球贸易中的地位,建模时需要假设中国“购买石油”和“出口工业品”这两个行为之间不存在相关关系。如果这个假设满足,那模型可能会给出结论——“中国处在贸易网络的中心位置”,但现实中这两个行为都受到贸易争端的影响且不相互独立的,因此模型可能会高估中国经济的影响力。
这就是传统的复杂网络建模的局限性。这种情况下需要引入higher-order models(高阶模型),才能更好地反映真实的状况。
optimal
另一个关键词是“optimal”(最优),暗含着模型并不盲目追求高阶,合适才是最好的意味。由此,我们引出了一个在建模过程中很重要的一个原理:奥卡姆剃刀原理。
人类从周围纷繁复杂,不断变动的环境中过滤冗余的信息,总结成方便利用的规律,形成了我们所说的“模型”。然而,模型并不是越高阶越有效。普通人并不需要对某些问题有过于细致深入的理解,他们关注问题可能仅仅了解线性趋势。对于某些领域的专业工作者来讲,他们需要关注的细节则更多,比如需要了解事物发展趋势的变化,模型也就越复杂。需求影响下,那些最简单但是又能充分满足需求的模型要比复杂模型更有效,满足需求下尽量从简,这就是奥卡姆剃刀原理。
当我们追问高阶现象的原理、对其进行建模时,模型本身也会变得更为复杂。根据奥卡姆剃刀原则,好的模型即便是在高阶的条件下也应使用最少的假设,推导出可泛化的结论,从而使得模型的适用范围超过最初建模的情景。
2. 高阶网络模型都关注什么信息
在介绍具体的每一种高阶模型之前,先看看高阶模型可以引入哪几方面的信息来扩展传统的复杂网络模型,具体分为下面几类:
传统的方法认为点与点之间的联系可以两两之间建模,但正如上文贸易争端的例子,在高阶网络中抛弃这个假设。
传统的模型假设点与点之间的联系没有外部性,高阶的网络通过将网络中边的相互影响引入模型,从而改变传统模型对节点重要性,以及网络中群落组成的判定。
高阶网络模型将点和点之间的连接分为不同的类型,例如在国际贸易网络中,将民用和军用的贸易分开,由于前者受经济规律影响,而后者受国际政治影响,从而需要以不同的方式对待。
高阶网络模型将点与点之间的连接发生的时间和先后顺序引入模型。
高阶网络模型会考虑节点之间关系的对全局,即网络中每个点的影响。
传统的复杂网络,该文中即初阶马尔可夫模型(first-order Markov model),是符合马尔可夫的独立性假设的模型。
案例:论文合作者网络
下面举一个被经常研究的复杂网络的例子,论文的共同作者和相互引用网络,网络中的每个节点是一个研究者,假设我们需要将网络的建模方法升阶,那最应该引入那些信息了?让逐个看看上述的列表:
传统的方法是A和B合作发表过文章,那就在AB之间增加一条边,现在要考虑三人之间的合作,这样网络会变得很复杂;
两位作者合作发表一篇文章后,双方的研究方向都会从中受到影响,但这样的影响是难以定量估计的;
文章的作者分为不同的类型,两位作者做为共同一作和一个出现在通讯,一个出现在一作中有着不同的意味在内,因此有必要将链接分类讨论;
将节点的连接的时间顺序引入网络很简单,这些信息会解释与时间相关的问题产生帮助,需要具体问题具体分析;
一篇突破性的文章会对所有的研究者及其合作网络产生影响。但是同第二条因素,模型难以用简单又客观的标准定量衡量。
综上所述,如果要在“论文共同作者相互引用网络模型”中引入高阶网络模型,第三条条件的可操作性最好。这也体现了上文说的奥卡姆剃刀原则,不是越复杂的模型越好,而是要用最简单的模型来涵盖尽可能复杂的现实。
接下来将逐个介绍文中6个不同的复杂网络高阶模型,通过和传统模型的对比,展示高阶模型的优势与必要性,文章最后给出两个在线工具,用于高阶网络建模的探索。
3. 自我中心网络
自我中心网络(Ego network)的节点是由唯一的一个中心节点(ego),以及这个节点的邻居组成的,它的边只包括了中心和邻居之间,以及邻居与邻居之间的边,如下图:
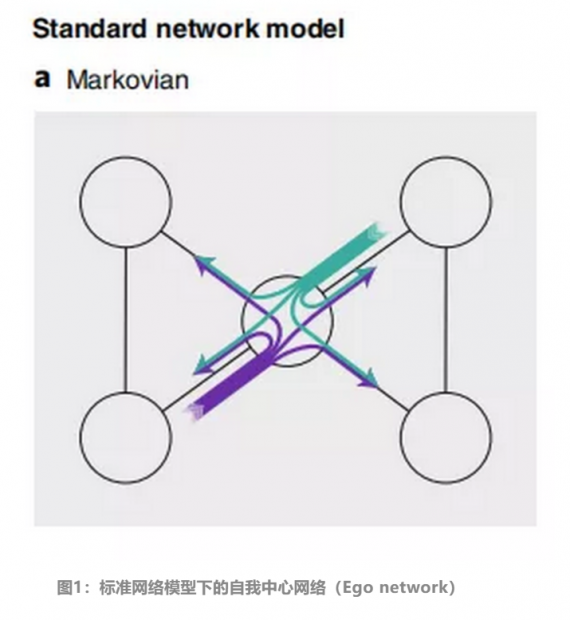
上图描述的是中心节点小C的社交网络,图中的边代表了小C和不同邻居的联络关系。假设我们知道图中右边的两位是小C的同事,左边的是小C的朋友,事实是小C朋友之间联系很多,和同事也联系很多,但小C的朋友联系小C的同事并不多(图中紫色的线),反之亦然(绿色的线)。
但单看这幅图,却看不出明显的区别,我们会自然而然认为小C的朋友和同事之间也保持了很高的交流频率,从而没有反映真实的情况。当我们引入了高阶模型之后,这个社交网络中信息流动的规律就会更加清晰。
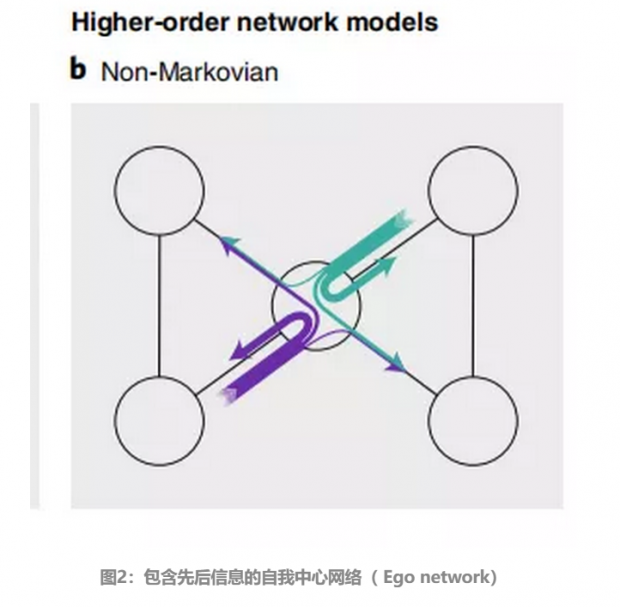
为了更好体现现实情况,如果我们将节点之间的先后关系纳入考虑,可以看到从左边到右边的连线比之前细了很多,而这样建模生成的网络,能够更好的反映出图中左边和右边的两对节点各自组成群落,群落内的联系大于群落间的联系。
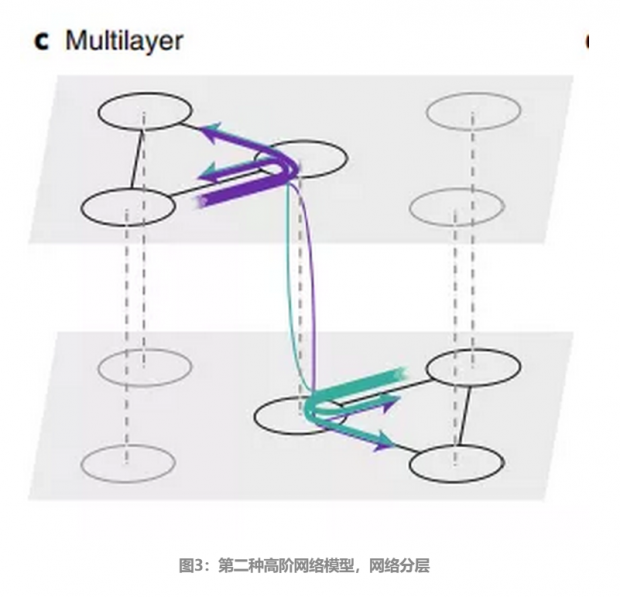
另一种建模的方法是对网络分层,将网络分为两层,将网络中的连接分为第一层,第二层和跨层三种,这样也突出了节点的类型不同这一洞见。
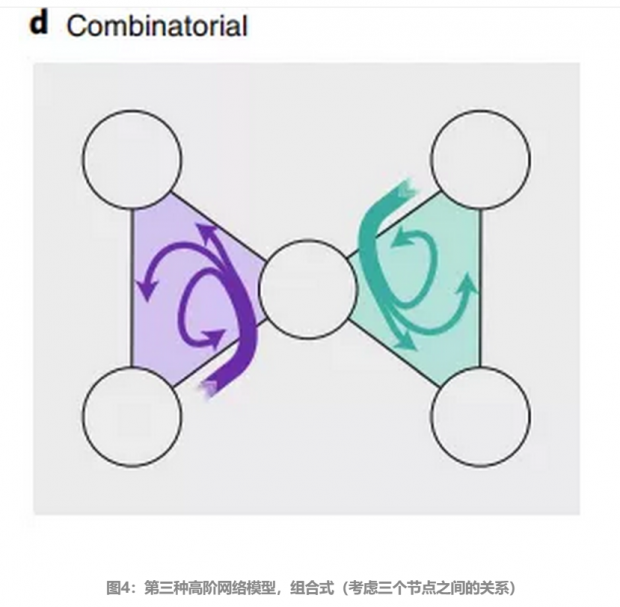
最后一种高阶模型考虑三个节点之间的相互关系,即只考虑了左右两个三元组之内的连接,而忽视了跨越三元组的连接。
以上这几种高阶自我中心网络都捕获到了节点间形成的群落,文章通过一个只有5个点的最简单的网络,展示了这四种不同的高阶网络和传统网络的区别,说明了在网络中引入更多维度信息的必要性。
4. 时间序列数据的建模
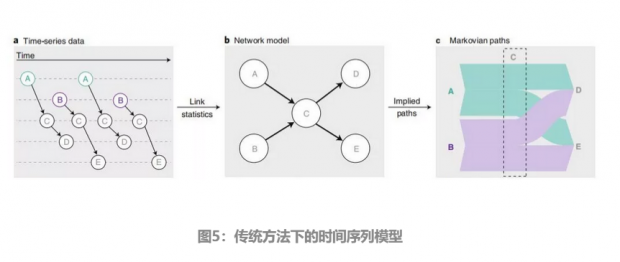
图中最左边是原始要建模的数据,横轴代表时间的流逝,b图是按传统方法建模后的结果,如果不考虑时间的影响的方式分析,我们最终会得到最右侧的Markovian paths。
这种方法有它的局限性,图a中不存在的从A节点到E节点,从B节点到D节点这两条路径错误的出现在了图c的分析中。
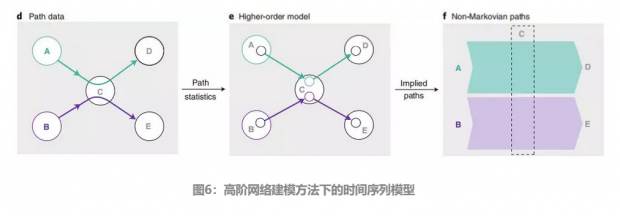
这里图中节点C由于处在两个不同的时间线上,所以经过这个节点的过程理应被分类讨论,路径中没有出现的从a到e及从b到d的不存在路径,而这反映了原始待建模数据的真实情况。该方法的一般形式是在一个有n个时间点的环境下,通过将一个节点按照发生的顺序,拆分成n-1个子节点,从而对时间序列给予更准确的建模。
5. 高阶网络与群落检测
Nature子刊群落
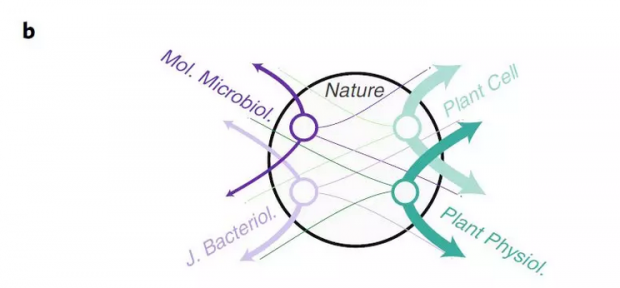
接下来看看现实存在的网络。Nature作为一个跨学科的期刊,其和诸多子刊之间都有相互引用的关系,根据Nature及其子刊的引用关系网,理想的情况下可以按学科将不同的子刊按学科分成不同的群落,但在传统的建模方法下,无法进行这种区分。
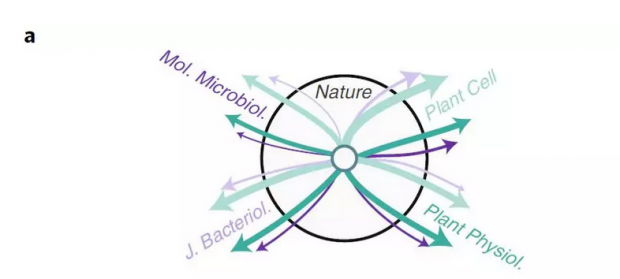
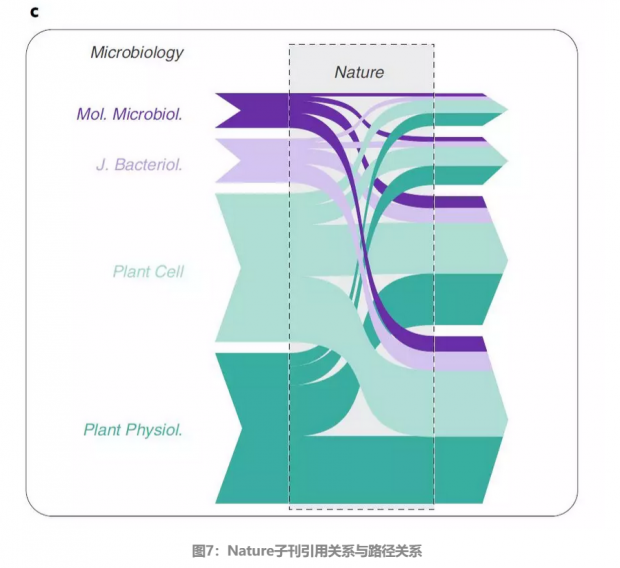
上图中紫色的是微生物相关的期刊,绿色是植物相关的期刊,中间的节点代表"Nature"中刊登的文章,上图是不同期刊间的引用关系,线的粗细代表了文章数目的大小,下图是将其展开为路径关系。由于"Nature"中会出现同时包含植物与微生物内容的文章,所以上图中两种不同类型的子刊无法被分为两个不同的群落。
但如果将引用关系分类,就可以发现,大部分的文章都是子刊A引用了主刊的文章B,而B又引用了子刊A的另一篇文章,如此可以将引用关系按是否跨子刊分为两类,由此得到下图:
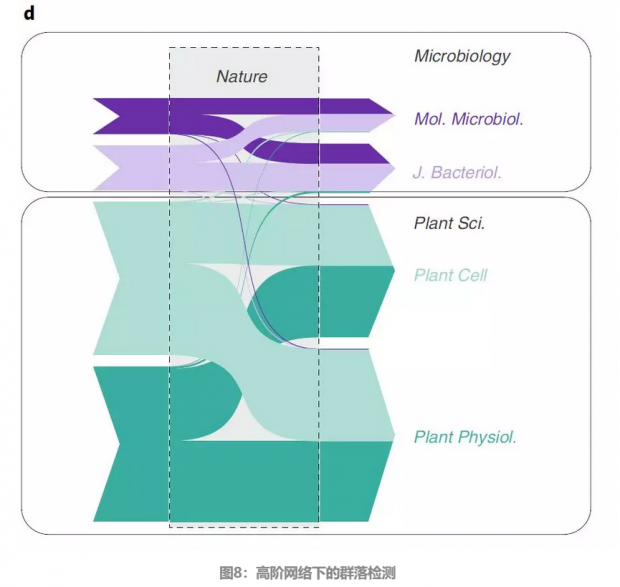
如图,只是Nature主刊这里分为了四个子节点,根据这里上图得出的路径图,可以很清楚的将子刊分为两类,从而得出了应有的群落检测结果。
6. 高阶网络与节点重要性分析
软件开发者社交网络
下图是一个大的开源项目中软件开发者的社交关系网络,按照开发者是否是为中间节点进行了可视化。这类图是复杂网络建模中最常见的,图中的点越大,说明该点的betweenness centrality(中介中心性)越高,该点位于其他成员的多条最短路上,那么该成员就是核心成员,就具有较大的中介中心性。
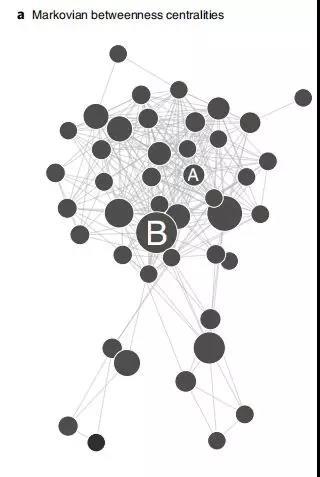
图9:开发者社交网络的复杂网络建模(常见形式)
可如果B真的是对A与C之间的连接存在着因果关系的话,也就是离开了B,A与C就无法联系了,那这意味着A和B的联系先于B与C的联系,原始数据中包含着通讯的时间,按照是否存在先后顺序来看,A和B的相对重要性就和图中表示的不同了。
下图名为alluvial diagrams(冲击图)展示的是两个节点之间的最短连接是否经过待考察的中间节点在时间上的变化,横轴代表是时间的流逝。对于左边的A节点,大部分经过A的最短路径,都是信息先传递给A,再由A传递给其他人。但是对于B节点,按照时间先后顺序来看,通过B传递的最短消息的数量明显偏少,传统的建模方法无法涵盖上述的信息,就产生了谬误。
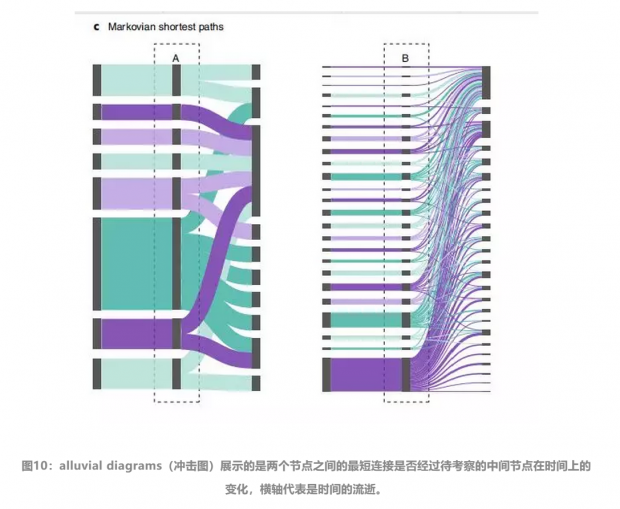
而如果在计算最短路径时,考虑时间的先后顺序,只计算有因果关系的连接(A到B先于B到C)那么得出的网络中节点的重要性就会发生不同,如下图所示:
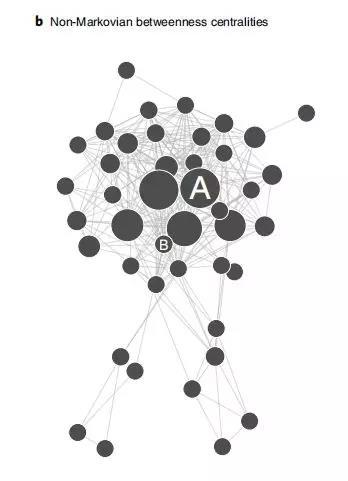
图11:考虑因果关系的复杂网络建模,网络中节点的复杂性发生了变化。
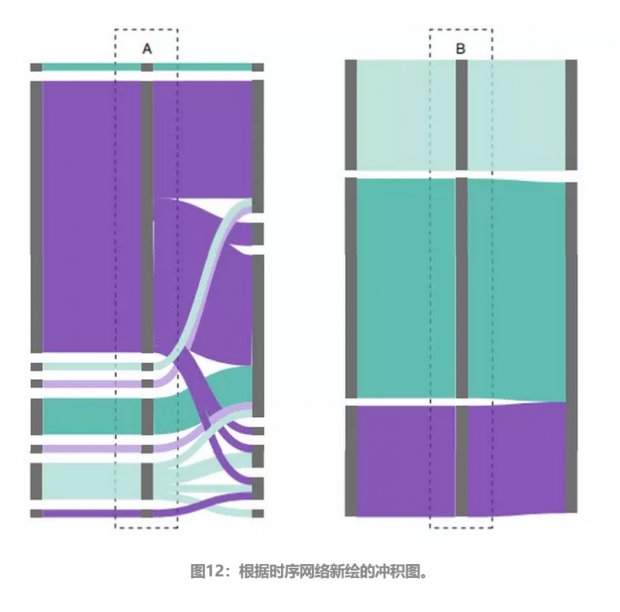
根据时序网络,画出的A与B的冲击图也能更好的反映真实的情况。从图中可以看到B似乎直接管理着一个三个人的团队,而A管理并协调着更多的人。如果不考虑时序的信息,只简单考虑网络中是否存在着通讯,那就会因为B更擅长社交而得到B是这个软件项目中最重要的成员这一错误结论。
7. 用 de Bruijn 图对高阶因果关系建模
上一个案例中我们只关注了最短路径下,间隔为2的两个节点的先后顺序。用 de Brujin 图对高阶因果性进行建模,则是一种通用的方法。
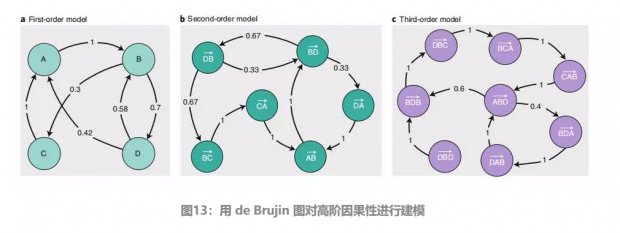
图a中的每个节点代表一个事件,图中的边代表事件之间的有多少概率会由于节点上的事件发生了从而导致发生下游事件。将图中的边的权重转换为转移矩阵,然后考虑在很多次的迭代下的一系列矩阵运算,就可以得出中间b图的二阶因果性模型。
图b中将每两个节点之间的变换看成了一个节点,图中的边代表上一步发生一个节点A对应的变换后,有多少概率下一次要发生的变换是节点B对应的。举个例子,例如对于C→A这个节点,由于在一阶网络中,上游的变化只可能是B→C,而后续只可能是A→B,因此可以看到边上的数字都是1。而对二阶网络再次进行同样的操作我们同理得到了三阶网络。
另外,一些不存在的边的出现是由于在一阶网络中有这样的连接,例如B→D→B 到 D→B→D就不应该有连接,因为这两个点代表的连接本就是自我循环的。
8. 高阶网络下的网络动力学
伦敦地铁网络

网络的拓扑结构决定了网络是否具有稳定性、信息流通是否高效。这些是网络动力学关心的问题。上图中的例子是伦敦的地铁网络,每个点代表一站,一条路代表的是这两站之间有地铁联通,现在希望了解从图中红点出发能否快速的将人们运输到目的地。

针对这个问题,如图b中展示,传统的方法是从A点开始用随机游走模型。图b表示在随机情况下按照旅客换乘概率模型,经过5个时间点后人群的分散动态。其中图中越粗的边代表换乘人数越多。
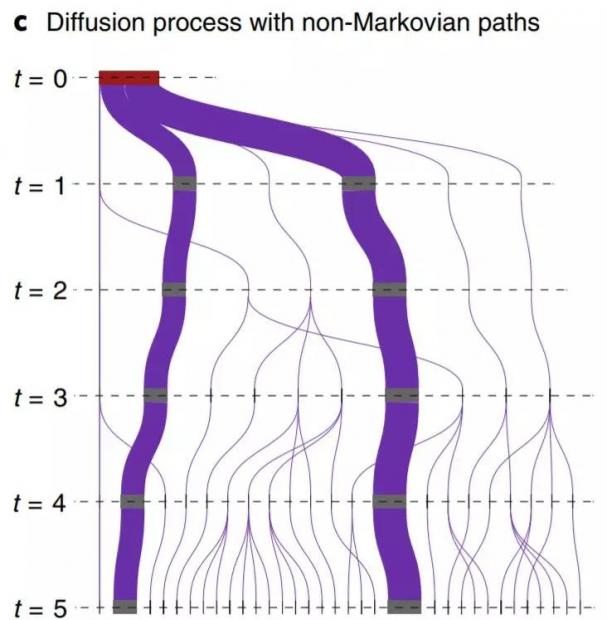
图16:根据真实数据,引入了对不同边的偏好。
但根据真实的情况,从A点出发的旅客,对先搭乘某条线有明显的偏好,在建模中根据真实数据,引入了对不同边的偏好后可以得出上文的图C,而图C更加接近伦敦地铁的实际情况。
研究系统的动力学时,仅仅看网络的拓扑结构是不够的。例如通过上文介绍的de Burijn图。如果真实世界中边和边之间是不平等的,而建模的时候又需要关注这种不平等的信息,那就应该在建模中引入它们。
9. 总结与展望
在我们总结全文之前,我们先来思索一下全文有哪些核心问题?这些问题都经历了怎么样的讨论?经过自己的思考能够留下更深的印象。
这篇文章要揭示的真相是那些研究者应该关心的?
复杂网络早已不是网络科学研究者的专长,它已经渗透到了统计物理,到社会科学,经济金融,计算生物从业者的工作中。各个行业的从业者用网络对其中实体的相互关系进行抽象并建模,而这些学科产生的数据又促使机器学习发展针对图的预测模型,例如GCN图卷积神经网络。因此对网络的基本形式进行修改和建模,因此对网络科学进行了解对各行各业的读者都开卷有益。
这篇文章展示的解决方法实际应用时好用吗?会不会带来额外的问题?
首先,好用与效益,该选择什么模型,这是个需要人们自己把握程度的问题。该从那个角度对传统网络进行扩展,是一个仁者见仁的问题,就如同我在引文中举的科研论文作者合作网络该怎么扩展的问题,不同的建模方法,最终的评价还是对应模型用机器学习的方式评价的预测准确性,这也对应了奥卡姆剃刀,模型的评价,看的是模型在未知情况下的泛化能力。
其次,不论使用那种模型,都存在着网络的复杂性指数级扩展的问题,例如按时间,连接的类型将网络中的节点拆分的方法,在真实生活中,随着网络包含越来越多的节点,每个节点可以被拆分成越来越多的节点,从而带来指数级增长的网络,不具有可扩展性。正如一张和真实世界一比一尺寸的地图没有任何用处,如何让高阶模型扩展到大数据集上,需要先探察清楚数据集本身的特点,从而使引入的高阶特征,不会带来给模型带来无法承载的相互关系。
在现实生活中,如果你使用固定阶数的网络模型,例如你对因果关系用二阶的de Bruijn图建模,那么部分案例中,你用的模型太复杂了,会导致过拟合;而在另外的情况下,你用的模型太简单,无法对真实的情况如实反映。上述的两种问题往往同时发生。这需要我们使用多种不同的模型,同时对现实情况建模,还需要能够将高阶模型简化的计算方法。
文中推荐了两款开源工具:Infomap和pathpy,这些工具能根据要建模的数据,去选择最具有解释效力的最优高阶模型,来对问题进行抽象。
解决这些问题,从而让文章的核心观点改变世界,是哪些人应该关心的问题?
展望未来也是科学的一部分。假设我们可以指出当前的高阶模型缺少一个统一的框架,要引入不同的信息,需要有不同的模型,如果能够在一种模型中引入前文提到的五种信息,那就完成了高阶网络领域的大一统,而这需要跨学科的合作,这样的成果也能让复杂网络的研究更上一层楼。
作者:郭瑞东
审校:陈曦
编辑:王怡蔺
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}