阅读:0
听报道

导语
“学习”是一个宽泛的概念,而今年来人工智能和认知科学的一系列工作,正在尝试将学习过程量化。在一篇论文中,研究者发现对于计算机系统和生物大脑,可能存在普遍共性——学习内容的训练精度接近85%时,学习速度达到最优。
作者:十三维
编辑:张爽
目录
1.“恰到好处”——学习的迷思
2.计算最优学习率
3.模拟验证:感知机模型
4.模拟验证:类生物神经网络
5.心流的数学理论
6.学习的定量时代?讨论、延伸与启示
附:参考资料
如何对学习者施行最好的教育?这似乎是一个无解的问题。
然而在2018 年底,来自包括亚利桑那大学、布朗大学、加州大学洛杉矶分校、普林斯顿神经科学研究所等多院校合作研究者发布表的一篇预印本论文,《The Eighty Five Percent Rule for Optimal Learning》中,研究者们通过关注训练难度这一单一变量,定量考察了其对学习速度的影响。
论文题目:
The Eighty Five Percent Rule for Optimal Learning
论文地址:
该论文证明,无论学习者是人类、动物还是机器,在大多数情况下,都存在一个学习的最有效点——在这个“甜蜜点”(sweet spot)附近进行学习既不会太容易,也不会太难,然而学习速度却是最快的。
论文的研究从二分类任务(Binary classification)开始,得出了一大类学习算法“甜蜜点”的条件。对于所有这些基于梯度下降的学习算法,论文计算出:最佳学习错误率为15.87%,或者相反,最佳训练精度为85%。,在此最佳难度下训练可以导致学习速度的指数级增长,同时论文证明该“85%规则”对于人工智能中使用的人工神经网络,或者和用来描述人类和动物学习的类生物神经网络都是有效的。
1. “恰到好处”——学习的迷思
人们在学习新技能时,例如语言或乐器,通常会觉得在能力边界附近进行挑战时感觉最好——不会太难以至于气馁,也不会太容易以至于感到厌烦。
历史传统中有所谓的中庸原则,我们也会有一种简单直觉经验,即做事要“恰到好处”。反映在学习中,即存在一个困难程度的“甜蜜点”,一个“金发姑娘区”。在现代教育研究中,在这个区域的不仅教学最有效果[1],甚至能解释婴儿在更多更少可学习刺激之间的注意力差异[2]。
在动物学习研究文献中,这个区域是“兴奋”[3]和“失落”[4]背后的原因,通过逐步增加训练任务的难度,动物才得以学习越来越复杂的任务。
在电子游戏中几乎普遍存在的难度等级设置中,也可以观察到这一点,即玩家一旦达到某种游戏水平,就会被鼓励、甚至被迫进行更高难度水平的游戏。
类似地,在机器学习中,对于各种任务进行大规模神经网络训练,不断增加训练的难度已被证明是有用的 [5,6],这被称为“课程学习”(Curriculum Learning)[7] 和“自步学习”(Self-Paced Learning)[8]。
尽管这些历史经验有很长的历史,但是人们一直不清楚为什么一个特定的难度水平就对学习有益,也不清楚最佳难度水平究竟是多少。
在这篇论文中,作者就讨论了在二分类任务的背景下,一大类学习算法的最佳训练难度问题。更具体而言,论文聚焦于基于梯度下降的学习算法。在这些算法中,模型的参数(例如神经网络的权重)基于反馈进行调整,以便随时间推移降低平均错误率[9],即降低了作为模型参数函数误差率的梯度。
这种基于梯度下降的学习构成了人工智能中许多算法的基础,从单层感知器到深层神经网络[10],并且提供了从感知[11],到运动控制[12]到强化学习[13]等各种情况下人类和动物学习的定量描述。对于这些算法,论文就训练的目标错误率提供了最佳难度的一般结果:在相当温和的假设下,这一最佳错误率约为15.87%,这个数字会根据学习过程中的噪音略有不同。
论文从理论上表明,在这个最佳难度下训练可以导致学习速度的指数级增长,并证明了“85%规则”在两种情况下的适用性:一个简单的人工神经网络:单层感知机,以及一个更复杂、用来描述人类和动物的感知学习[11]的类生物神经网络(biologically plausible network)。
2. 计算最优学习率
在标准的二分类任务中,人、动物或机器学习者需要输入的简单刺激做出二元标签分类判断。
例如,在心理学和神经科学[15,16]的随机点动实验(Random Dot Motion)范例中,刺激由一片移动的点组成 - 其中大多数点随机移动,但有一小部分连贯一致地向左或向右移动。受试者必须判断相应一致点的移动方向。
决定任务感知判断难度的一个主要因素是一致移动点所占的比例。如下图所示,一致点占0%时显然最难,100 %时最容易,在 50%时难度居中。
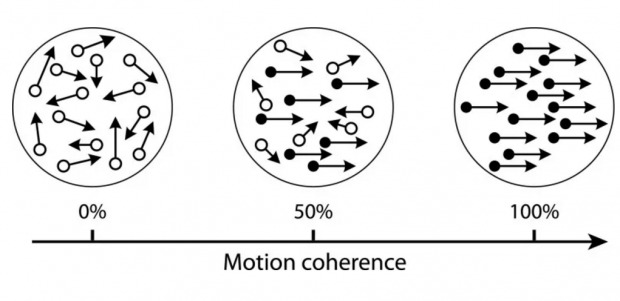
实验人员可以在训练过程中使用被称为“阶梯化”(staircasing)的程序[17]控制这些一致移动点的比例以获得固定的错误率。
论文假设学习者做出的主观决策为变量 h,由刺激向量 x(如所有点的运动方向) 的经函数 Φ 计算而来,即:h = Φ(x, φ) ——(1),其中φ是可变参数。并假设变换过程中,会产生一个带噪声表示的真实决策变量Δ(例如,向左移动点的百分比),即又有 h = ∆ + n ——(2)。
噪声 n 由决策变量的不完全描述而产生的,假设 n 是随机的,并从标准偏差σ的零均值正态分布中采样。设 Δ = 16,则主观决策变量 p(h) 的概率分布如图1A所示。
红色曲线是学习之后新的曲线,可以看到其分布标准差σ比原来有所降低,使更多变量分布在了Δ=16 附近。这就说明学习者在学习之后决策准确度有所提高。曲线下方的阴影区域面积(积分)对应于错误率,即在每个难度下做出错误响应的概率。
如果把决策界面(decision boundary)设置为 0,当 h > 0 时模型选择选项 A,当 h < 0 时选择 B, h = 0 时随机选择。那么由带噪声表示的决策变量导致的错误概率分布为:

如图1B所示,无论学习前还是学习后,随着决策变得更容易(Δ增加),两条曲线皆趋于下降,从而使错误率变得更低。
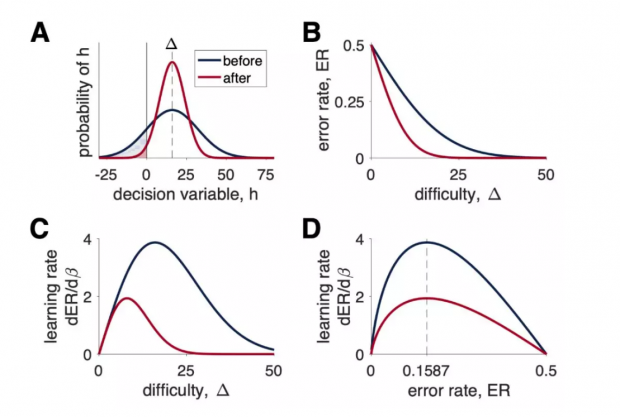
但两条曲线的下降速度是不一样的:当β增加(σ变小)后,曲线更集中和陡峭,因此学习之后的红色曲线下降速度也更快,这表示学习者对任务挑战的技能水平越趋于完善。
由最初的公式(1) 可知,学习的目标是调整参数φ,使得主观决策变量 h 更好地反映真实决策变量Δ。即构建模型的目标应该是尽量去调整参数φ以便减小噪声 σ 的幅度,或者等效地去增加技能水平精度 β。
实现这种调节的一种方法是使用误差率函数的梯度下降来调整参数。例如,根据时间 t 来改变参数。论文在将梯度转换为精度β的表示后,发现影响因子只在于最大化学习率 ∂ER/∂β 的值,如图1C所示。显然,最佳难度Δ随着技能水平精度β的函数 dER/dβ 而变化,这意味着必须根据学习者的技能水平实时调整学习难度。不过,通过Δ和ER之间的单调关系(图1B),能够对此以误差率ER来表达最佳难度,于是可以得到图1D。
在变换后,以误差率表达的最佳难度是一个精度函数的常量。这意味着可以通过在学习期间将误差率钳制在固定值上实现最佳学习。论文通过计算得出,对于高斯分布的噪声这个固定值是:
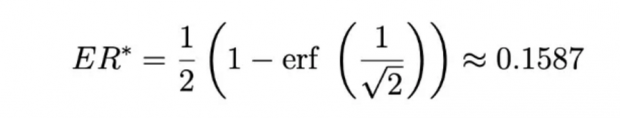
——即最佳学习率下误差率约为 15.87 %。
3. 模拟验证:感知机模型
为了验证“85%规则”的适用性,论文模拟了两种情况下训练准确性对学习的影响:在人工智能领域验证了经典的感知机模型,一种最简单的人工神经网络,已经被应用于从手写识别到自然语言处理等的各种领域。
感知机是一种经典的单层神经网络模型,它通过线性阈值学习过程将多元刺激 x 映射到二分类标签 y 上。为了实现这种映射,感知机通过神经网络权重进行线性变换,并且权重会基于真实标签 t 的反馈进行更新。也就是说,感知机只有在出错时才进行学习。自然的,人们会期望最佳学习与最大错误率相关。然而,因为感知机学习规则实际上是基于梯度下降的,所以前面的分析对这里也适用,即训练的最佳错误率应该是15.87%。
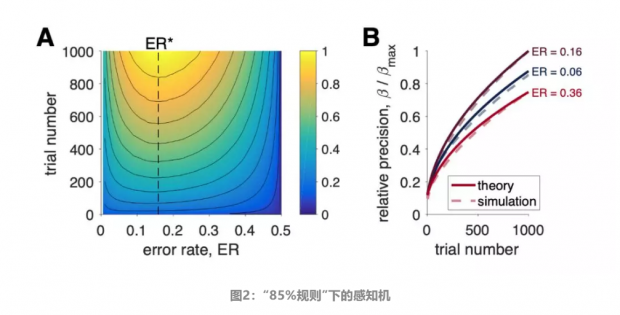
为了验证这个预测,论文模拟了感知机学习情况。以测量范围为0.01到0.5之间的训练误差率,步长为0.01(每个误差率1000次模拟)训练。学习的程度由精确度β确定。正如理论预测的那样,当以最佳错误率学习时,网络学习效率最高。如图2A所示,不同颜色梯度表示了以相对精度β/βmax 作为训练误差率和持续时间的函数,在 β=βmax 时学习下降最快;在不同错误率比例因子下的动态学习过程,图2B也显示,理论对模拟进行了良好的描述。
4. 模拟验证:类生物神经网络
为了证明“85%规则”如何适用于生物系统学习,论文模拟了计算神经科学中感知学习的“Law和Gold模型”[11]。在训练猴子学会执行随机点运动的任务中,该模型已被证明可以解释包括捕捉行为、神经放电和突触权重等长期变化情况。在这些情况下,论文得出相同结果,即当训练以85%的准确率进行时,学习效率达到最大化。
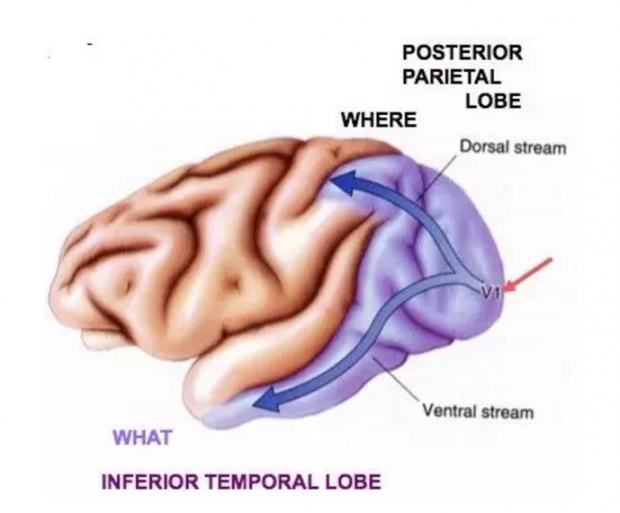
具体来说,该模型假设猴子基于MT脑区的神经活动做出有关左右感知的决策。MT区在视觉系统的背侧视觉通路(Dorsal visual stream),是已知在大脑视觉中表征空间和运动信息的区域[15],也被称为“空间通路”(where),相对的,视觉系统另一条腹侧视觉通路(Ventral visual stream)则表征知觉形状,也被称为“辨识通路”(what)。
在随机点动任务中,已经发现MT神经元对点运动刺激方向和一致相关性 COH 都有响应,使得每个神经元对特定的偏好方向响应最强,且响应的幅度随着相关性而增加。这种激发模式可通过一组简单的方程进行描述,从而对任意方向与相关刺激响应的噪声规模进行模拟。
根据大脑神经集群响应情况,Law 和 Gold 提出,动物有一个单独脑区(侧面顶侧区域,LIP)用来构建决策变量,作为MT中活动的加权和。不过它与感知机的关键差异在于,存在一个无法通过学习来消除的随机神经元噪声。这意味着无论多么大量的学习都不可能带来完美的性能。不过,由论文计算结果所示,不可约噪声的存在不会改变学习的最佳精度,该精度仍为85%。
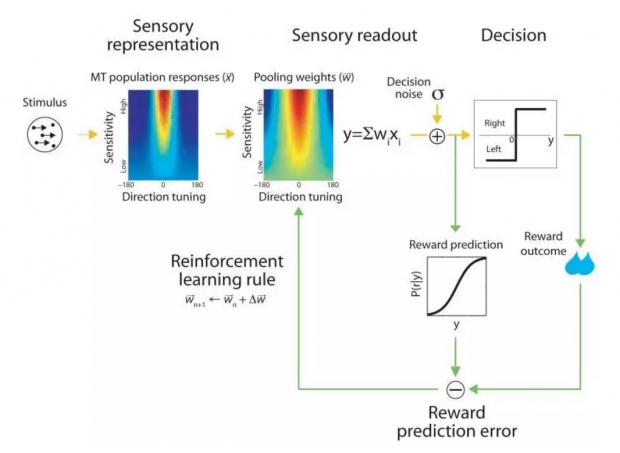
Law and Gold 模型和感知机的另一个区别是学习规则的形式。具体来说就是有基于预测误差正确的奖励,会根据强化学习规则进行更新权重。尽管与感知器学习规则有很大的不同,但Law和Gold模型仍然在误差率[13]上实现梯度下降,在 85%左右实现学习最优。
为了测试这一预测,论文以各种不同的目标训练误差率进行了模拟,每个目标用MT神经元的不同参数模拟100次。其中训练网络的精度β,则通过在1%到100%之间以对数变化的一组一致性测试上,拟合网络的模拟行为来进行估计。
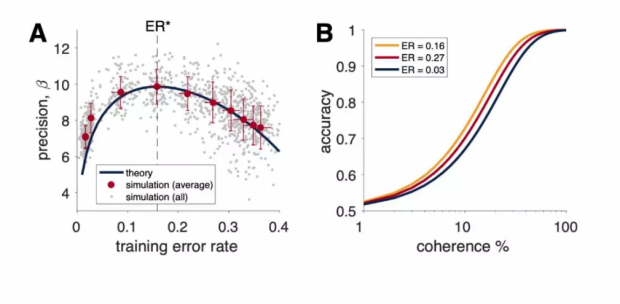
如图3A所示,在训练网络精确度β作为训练错误率的函数下,蓝色的理论曲线很好描述了训练后的精度。其中灰点表示单次模拟的结果。红点对应于每个目标误差率的平均精度和实际误差率。
此外,在图3B中,以三条不同颜色测量曲线显示了三种不同训练错误率下行为的预期差异 。可以看到,在误差率为 0.16 (接近 15.87%)的黄色曲线上,结果精确度高于过低或过高误差率的两条曲线,即取得了最优的训练效果。
5. 心流的数学理论
沿着相同的思路,论文的工作指向了“心流”状态的数学理论[17]。这种心理状态,即“个体完全沉浸在没有自我意识但具有深度知觉的控制”的活动,最常发生在任务的难度与参与者的技能完全匹配时。
这种技能与挑战之间平衡的思想,如图4A所示,最初通过包括另外两种状态的简单概念图进行描述:挑战高于技能时的“焦虑”和技能超过挑战时的“无聊”,在二者中间即为“心流”。
而以上这三种不同性质的区域:心流,焦虑和无聊,可以本篇论文的模型中自然推演出来。
设技能水平为精度 β,以真实决策变量的反函数 1 /Δ 为技能挑战水平。论文发现当挑战等于技能时,心流与高学习率和高准确性相关,焦虑与低学习率和低准确性相关,厌倦与高准确性和低学习率相关(图4B和图C)。
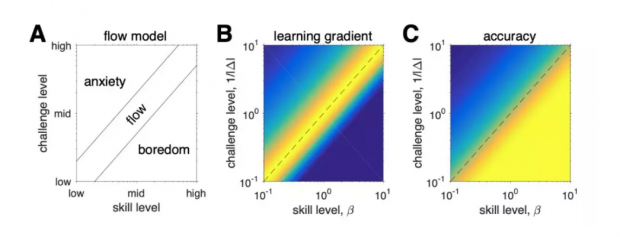
也就是说,在技能与挑战水平相等时以“心流”状态进行的学习,具有最高的学习率和最高的准确性。
此外论文引述了 Vuorre 和 Metcalfe 最近的研究[18]发现,心流的主观感受达到巅峰时的任务是往往主观评定为中等难度的任务。而在另一项关脑机接口控制学习方面的研究工作发现,主观自我报告的最佳难度测量值,在最大学习任务相关难度处达到峰值,而不是在与神经活动的最佳解码相关难度处达到峰值[19]。
那么一个重要的问题来了,在使用最佳学习错误率,达到主观最佳任务难度即心流状态进行学习时,其学习速度究竟有多快?
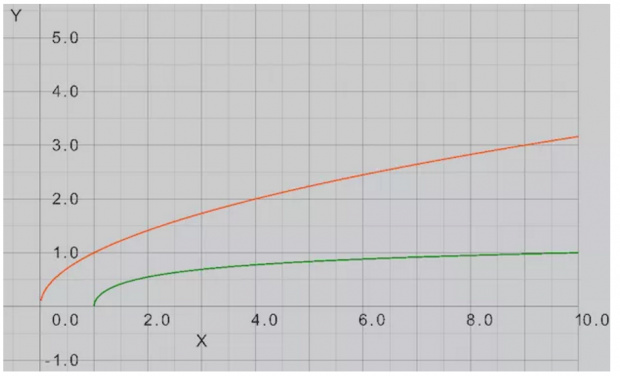
论文通过比较最佳错误率与固定但可能次优的错误率、固定难度进行学习来解决了这个问题。通过对训练误差率函数计算,最终得到,在固定错误率下:学习技能β精度随着时间 t 的平方根而增长。
而相对的,在没有使用最佳固定错误率学习,即决策变量固定下一般学习,其结果会强烈地依赖于噪声的分布。不过论文计算出了噪声为正态分布的情况下的近似解,对β的提升,学习技能以更慢的对数速度增长。即若最佳训练率下,可以相当于对后者实现指数级增长的改进。二者学习增速趋势对比图如下:
从论文对感知机和Law and Gold 模型测试,心流理论的数学化可以看出,未来研究者们去测试各种学习类型活动参与度的主观测量值,验证是否在最大学习梯度点达到峰值,“85%规则”是否有效将会是有非常有趣的。
然而这篇论文的作用还远不仅于此,下面就本文意义做进一步深入探讨。
6. 学习的定量时代?讨论、延伸与启示
学习对个体生物个体的重要性不言而喻,甚至比大多数人想得更重要。在2013年1月,《心理学通报与评论》上发表了一篇 论文①的就认为,学习不仅一个是认知过程,在更本质的功能层面是一种个体自适应过程,包括生物体在有机环境规律作用下的行为改变,并认为就如演化论是生物学核心一样,学习研究应该是心理学的核心。
然而,自心理学诞生后的诸多理论,对学习的研究往往止于简单行为操作或概念描述层面。比如行为主义研究者巴普洛夫和和斯金纳经典条件反射、操控条件反射,苏联心理学家维果斯基(Lev Vygotsky)有关儿童教育的“最近发展区”理论,有关动机和表现之间的关系的耶基斯–多德森定律(Yerkes–Dodson law)、基于舒适-学习-恐慌区的“舒适圈理论”,还包括米哈里·契克森米哈赖的“心流理论”,安德斯·艾利克森的“刻意练习”等等。
这些学习理论,要么强调学习需要外部刺激相关性、或正向奖励负向惩罚的某些强化,要么强调学习在大周期的效果,或较小周期的最小行动,要么寻求某种任务难度与技能水平、或动机水平与表现水平之间的一个折中区域。但是却从来没有给出如何到能达这种状态的条件,往往只能凭借有教育经验的工作者在实际教学中自行慢慢摸索。
而在这篇论文中,研究者考虑了在二分类任务和基于梯度下降的学习规则情况下训练准确性对学习的影响。准确计算出,当调整训练难度以使训练准确率保持在85%左右时,学习效率达到最大化,要比其他难度训练的速度快得多,会使学习效果指数级快于后者。
这个结果理论在人工神经和类生物学神经网络具有同样的效果。即“85%规则”既适用于包括多层前馈神经网络、递归神经网络、基于反向传播的各种深度学习算法、玻尔兹曼机、甚至水库计算网络(reservoir computing networks)[21, 22])等广泛的机器学习算法。通过对∂ER/∂β梯度最大化的分析,也证明其适用于类生物神经网络的学习,甚至任何影响神经表征精确度的过程,比如注意、投入或更一般的认知控制[23,24]。例如在后者中,当∂ER/∂β最大化时,参与认知控制的好处会最大化。通过关联预期价值控制理论(Expected Value of Control theory)[23,24,25]的研究,可以知道学习梯度 ∂ER/∂β 由大脑中与控制相关的区域 ( 如前扣带回皮层 ) 来进行监控。
因此可以说,本篇论文无论对计算机科学和机器学习领域研究,还是对心理学和神经科学研究,都具有重要的意义。
在前者,通过“课程学习”和“自步学习”诉诸广泛的机器学习算法,本文基于梯度下降学习规则思路下包括神经网络的各种广泛学习算法,都急需后续研究者进行探索和验证。在最佳学习率上,论文的工作仅仅是对机器学习学习效率数学精确化实例的第一步。并且同时也促使研究者思考:如何将这种最优化思路推广到在更广泛的环境和任务的不同算法中?例如贝叶斯学习,很明显和基于梯度下降的学习不同,贝叶斯学习很难受益于精心构建的训练集,无论先出简单或困难的例子,贝叶斯学习者会学得同样好,无法使用 ∂ER/∂β 获得“甜蜜点”。但跳开论文研究我们依然可以思考:有没有其它方法,例如对概念学习,通过更典型或具有代表性的样本、以某种设计的学习策略来加快学习速度和加深学习效果?
另一方面,这篇论文的工作同样对心理学、神经科学和认知科学领域有重大启示。
前面已经提到,有关学习理论大多止步于概念模型和定性描述。除了少数诸如心理物理学中的韦伯-费希纳定律(Weber-Fechner Law)这样,有关心理感受强度与物理刺激强度之间的精确关系,以及数学心理学(Mathematical psychology)的研究取向和一些结论,缺乏数学定量化也一直是心理学研究的不足之处。
而这篇论文不仅结论精确,其结论适用于包括注意、投入或更一般的认知控制下任何影响神经表征精确度的过程。如前所述,如果我们采取“学习不仅一个是认知过程,在更本质的功能层面是一种个体自适应改变过程”有关学习本质的观点,会发现它带来的启示甚至具有更大的适用性,远远超出了一般的认知和学习之外。
例如,在知觉和审美方面的研究中,俄勒冈大学(University of Oregon)的物理学 Richard Taylor 通过对视觉分形图案的研究发现,如设白纸的维度D为1,一张完全涂黑的纸的维度D为2,即画出来的图形维度在 1~2 之间,那么人类的眼睛更偏好于看维度 D=1.3 的图形[26]。事实上许多大自然物体具有的分形维度就是 1.3,在这个复杂度上人们会感到最舒适。一些著名的艺术家,比如抽象表现主义代表人物 ( Jackson Pollock ),他所画的具有分形的抽象画(下图中间一列,左边是自然图,右边为计算机模拟图)分布在 D=1.1 和 1.9 之间,具有更高分形维度的画面会给人带来更大的压迫感[27]。

心理学家 Rolf Reber 在审美愉悦加工的流畅度理论(Processing fluency theory of aesthetic pleasure)中[28]提出,我们有上述这种偏好是因为大脑可以快速加工这些内容。当我们能迅速加工某些内容的时候,就会获得一个正性反应。例如加工 D = 1.3的分形图案时速度很快,所以就会获得愉悦的情绪反应。此外,在设计和艺术领域心理学家域唐纳德·诺曼(Donald Arthur Norman)和艺术史学家贡布里希(Ernst Gombrich)也分别提出过类似思想。
对比下 D = 1.3 和 15.87% 的出错率,如果进行下统一比例,会发现前者多出原有分形维复杂性和整体的配比,未知:已知(或熟悉:意外,秩序与复杂)约为 0.3/1.3 ≈ 23.07%,这个结果比15.87%要大。这种计算方法最早由数学家 George David Birkhoff 在1928 年于《Aesthetic Measure》一书中提出,他认为若 O 为秩序,C 为复杂度,则一个事物的审美度量 M = O/C。
因此,在最简化估计下,可以类似得出 23.07% 额外信息的“最佳审美比”,会让欣赏者感到最舒适。
当然,因为信息复杂度的计算方法不一,上面只是一个非常粗略的估计。审美过程涉及感觉、知觉、认知、注意等多个方面,并且先于狭义的认知和学习过程,因此最佳审美比应该会15.87%要大。但至于具体数值,很可能因为不同环境和文化对不同的主体,以及不同的计算方法有较大差别,例如有学者从香农熵和柯尔莫哥洛夫复杂性方面进行度量的研究[29]。
但不管怎样,从这篇文章的方法和结论中,我们已可以得到巨大启示和信心,无论是在人工智能还是心理学或神经科学,无论学习还是审美、知觉或注意,在涉及各种智能主体对各种信息的处理行为中,我们都可能寻求到一个精确的比例,使得通过恰当选取已知和未知,让智能主体在体验、控制或认知上达到某种最优。而这种选取的结果,会使积累的效果远超自然过程得到改进。从这个意义上讲,这篇论文影响得很可能不只是某些科学研究方向,而是未来人类探索和改进自身的根本认知和实践方法。
参考资料:
Celeste Kidd, Steven T Piantadosi, and Richard N Aslin. The goldilocks effect: Human infants allocate attention to visual sequences that are neither too simple nor too complex. PloS one, 7(5):e36399, 2012.
Janet Metcalfe. Metacognitive judgments and control of study. Current Directions in Psychological Science, 18(3):159–163, 2009.
BF Skinner. The behavior of organisms: An experimental analysis. new york: D.appleton-century company, 1938.
Douglas H Lawrence. The transfer of a discrimination along a continuum. Journal of Comparative and Physiological Psychology, 45(6):511, 1952.
J L Elman. Learning and development in neural networks: the importance of starting small. Cognition, 48(1):71–99, Jul 1993.
Kai A Krueger and Peter Dayan. Flexible shaping: How learning in small steps helps.Cognition, 110(3):380–394, 2009.
Yoshua Bengio, Jérˆ ome Louradour, Ronan Collobert, and Jason Weston. Curricu- lum learning. In Proceedings of the 26th annual international conference on machine learning, pages 41–48. ACM, 2009.
M Pawan Kumar, Benjamin Packer, and Daphne Koller. Self-paced learning for latent variable models. In Advances in Neural Information Processing Systems, pages 1189–1197, 2010.
David E Rumelhart, Geoffrey E Hinton, Ronald J Williams, et al. Learning represen- tations by back-propagating errors. Cognitive modeling, 5(3):1, 1988.
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton.Deep learning.Nature, 521(7553):436–444, 2015.
Chi-Tat Law and Joshua I Gold. Reinforcement learning can account for associative and perceptual learning on a visual-decision task. Nat Neurosci, 12(5):655–63, May 2009.
WI Schöllhorn, G Mayer-Kress, KM Newell, and M Michelbrink.Time scales of adaptive behavior and motor learning in the presence of stochastic perturbations.Human movement science, 28(3):319–333, 2009.
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8(3-4):229–256, 1992.
Frank Rosenblatt. The perceptron: A probabilistic model for information storage and organization in the brain. Psychological review, 65(6):386, 1958.
William T Newsome and Edmond B Pare. A selective impairment of motion perception following lesions of the middle temporal visual area (mt). Journal of Neuroscience, 8(6):2201–2211, 1988.
Kenneth H Britten, Michael N Shadlen, William T Newsome, and J Anthony Movshon.The analysis of visual motion: a comparison of neuronal and psychophysical perfor- mance. Journal of Neuroscience, 12(12):4745–4765, 1992.
Mihaly Csikszentmihalyi. Beyond boredom and anxiety. Jossey-Bass, 2000.
Matti Vuorre and Janet Metcalfe. The relation between the sense of agency and the experience of flow. Consciousness and cognition, 43:133–142, 2016.
Robert Bauer, Meike Fels, Vladislav Royter, Valerio Raco, and Alireza Gharabaghi.Closed-loop adaptation of neurofeedback based on mental effort facilitates reinforce- ment learning of brain self-regulation. Clinical Neurophysiology, 127(9):3156–3164, 2016.
De Houwer J1, Barnes-Holmes D, Moors A..What is learning? On the nature and merits of a functional definition of learning.https://
Herbert Jaeger. The “echo state” approach to analysing and training recurrent neural networks-with an erratum note. Bonn, Germany: German National Research Center for Information Technology GMD Technical Report, 148(34):13, 2001.
Wolfgang Maass, Thomas Natschläger, and Henry Markram. Real-time computing without stable states: A new framework for neural computation based on perturba- tions. Neural computation, 14(11):2531–2560, 2002.
Amitai Shenhav, Matthew M Botvinick, and Jonathan D Cohen. The expected value of control: an integrative theory of anterior cingulate cortex function. Neuron, 79(2):217–240, 2013.
Amitai Shenhav, Sebastian Musslick, Falk Lieder, Wouter Kool, Thomas L Griffiths, Jonathan D Cohen, and Matthew M Botvinick. Toward a rational and mechanistic account of mental effort. Annual Review of Neuroscience, (0), 2017.
Joshua W Brown and Todd S Braver. Learned predictions of error likelihood in the anterior cingulate cortex. Science, 307(5712):1118–1121, 2005.
Hagerhall, C., Purcell, T., and Taylor, R.P. (2004). Fractal dimension of landscape silhouette as a predictor for landscape preference. Journal of Environmental Psychology 24: 247–55.
A Di Ieva.The Fractal Geometry of the Brain.
Rolf Reber, Norbert Schwarz, Piotr Winkielman.Processing Fluency and Aesthetic Pleasure:Is Beauty in the Perceiver's Processing Experience.http://
Rigau,Jaume Feixas,Miquel Sbert,Mateu.Conceptualizing
Birkhoff’s Aesthetic Measure Using Shannon Entropy and Kolmogorov Complexity.
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}