阅读:0
听报道
文 | 李嫣然
本期推出的第三篇文章“Attention和Memory Network”则是由著名的小S(李嫣然)献给大家的。她也是系统地梳理了有关注意力和记忆的相关重要论文。我们会看到,为了应付数据之中的层级性,人们想出了各种各样的办法。
今天分享 ICLR 2017,主题是 Attention 和 Memory。这两者作为2014年到2016年最火的 Neural Network Mechanism 和 Architecture,将非常多的 Vision 和 NLP 任务的 performance 都提高到了不少。尤其是 Attention,已经成为了新的 state-of-the-art,不加 Attention 的 NN 几乎无法再和 attention-based models 抗衡。
然而,Attention 和 Memory 这两者之间其实也有着密不可分的关系,以及其两者都有各自的不足。ICLR 2017 中便有许多对于它们两者的讨论与改进工作。于是乎,今天会分享的论文如下(仍然只是部分,剩下的下次分享):
Structured Attention Networks
Hierarchical Memory Networks
Generating Long and Diverse Responses with Neural Conversation Models
Sequence to Sequence Transduction with Hard Monotonic Attention
Memory-Augmented Attention Modeling For Videos
1 Structured Attention Networks
第一篇[1] 是今天推荐的重中之重吧,它将我们经典的 attention mechanism 和他们提出的新的两种(两个 attention layer)统一在一个框架里,使得 attention mechanism 从普通的 soft annonation 变成了既能 internally modeling structure 信息又不破坏 end-to-end training 的新机制。
具体来讲,我们以往的 attention 机制的作用方式是,encoder 端的 input x_1,..., x_n,这个被作者称为 x,decoder 端已经解码产生的序列 y_1, ..., y_n,这个被作者称为 q(query)。那么,attention 机制就可以看做是一个 attention position 基于 x, q 的分布,如下式:

有了这样一个框架,我们就可以将一系列独立的 z 变成了互相之间有关联,有依赖——从而也就有了 structure 信息的 z 的分布表达——也就是一种 structured attention networks。为了实现这个,作者使用了 CRF 来建模,并给出了两种具体的例子。
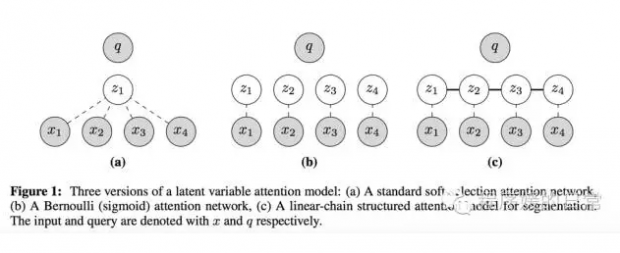
第一个例子叫,segmentation attention layer,它可以用于选择源句子中的 sub-sequence(而不再是经典 attention 中以 word 为单位了)。它的设计也十分简单直观,就是我们把 z 像 gate 机制一样,变成 z=[z_1, ..., z_n],并且 z_i \in {0,1}。这样的话,对于我们之前的 annonation 就可以得到如下的表达:
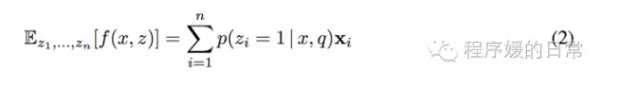
这个表达使得我们可以同时选择多个 z+i,并且 z_i 与 z_j 之间是有依赖关系的,而这个依赖关系就是通过上式中的 p(z_i | x,q) 来建模的:
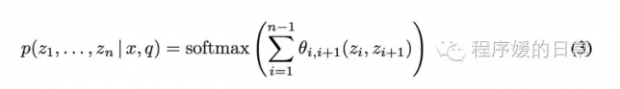
那么第二个例子,则在这种虽然是 seb-sequence 上但仍然是 continuous、顺序进行的基础上,又改进了一些,被叫做 syntactic attention layer。它的 motivation 是直接去建模我们 NLP 中的语法树结构。这一次,我们要从 z_i 变成 z_{ij},用它来表示一对语法树中的父结点和子结点。于是乎,类似的,我们就可以得到如下这个建模表达:
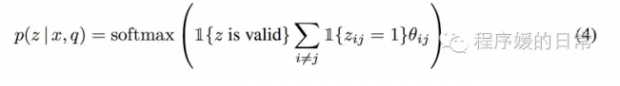
用这两种新的 attention layer,作者在多个任务上都取得了比经典 attention layer 更好的结果。
2 Hierarchical Memory Networks
第二篇[2] 论文则是将 Memory Networks 改造成了一种 soft attention 和 hard attention 之间的 trade-off。我们都知道,attention mechanism 其实是提供了一种 access,告诉 decoder how to access/where to access——这其实是一种 read 操作;而我们很多时候希望能有一种 write 操作,可以一边 decoding 一边去 update 我们一些中间结果。这也是 attention 和 memory 之间的主要区别,也是它们可以被放进统一的一个框架中的原因。

而 soft attention 的计算量其实是非常庞大的,hard attention 又不够 stable——分别取其二者之精华后,这第二篇论文[2] 的作者便想出了 hierarchical memory networks(HMN)。HMN 是利用层次化结构,将 soft attention 每次需要计算的量缩小。那么如何“找到”这种层次化结构呢?它们提出使用一种叫 Maximum Inner Product Search(MIPS)的方法。MIPS 不仅可以建立这种层次化形式的 memory,还能通过计算这个 maximum inner product 的值,找到和 query 最相关的 memory 子集。最后,因为这种 MIPS 的精确计算也很难,它们又提出了几种近似的计算方法。最后,它们在 SimpleQuestions(SQ)这个数据集上做了实验,实验结果如下:
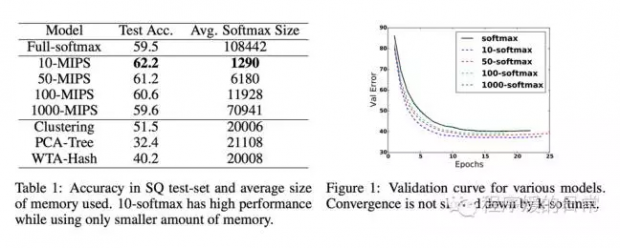
3 Generating Long and Diverse Responses with Neural Conversation Models
第三篇[3] 要介绍的论文我也比较推荐。它来自 Google Research 和 Google Brain 团队。乍一看 Abstract 会觉得并没有什么新技术(research point),但其实整篇文章对于当前 sequence-to-sequence conversation models 中存在的问题和背后的原因,分析得相当清楚。虽然最后提出的 solution 都有些偏工程化,但不妨碍是一篇值得我们也去尝试的好工作。并且,在这篇文章[3]中,作者也修改了 attention 机制,使得以前只依赖于 input(source-side) 的 attention 能融合进已经产生的 output(target-side)的信息——所以被他们成为 target-side attention。
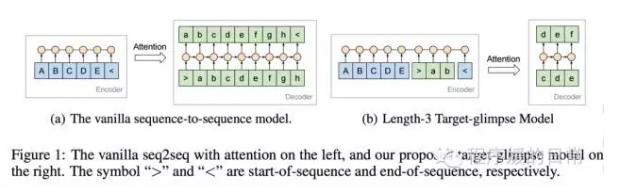
因为今天重点是介绍 attention 和 memory,所以这篇文章中的其他 point 先不提了。只说这个 target-side attention。作者指出,我们经典的 attention 机制在计算的时候,它的 attended pool 只包含了 C,也就是只包含了 source-side encoder 中的信息——这个模型也就只能 attend 这些 candidates(比如说 input words)。这个本来,在机器翻译这种任务上是没问题的,因为毕竟我们的 source sentence 已经包含了我们要产生的全部信息了;但是在对话这种任务上就有问题了。问题是啥呢,我们很多时候,source sentence,也就是用户说的那句话,是不够 informative 的,比较短——这个时候反而是 decoder 中已经产生的 output 可能会对我们更有帮助。于是乎,直接的解决办法就是把 decoder 中已经产生的序列也扔到 attention candidate pool 里去。就像这样:

这样做还有啥好处呢,好处就是我们的 decoder 的 hidden states 就可以少“记”一些已经生成的信息了,也就能更好的去做整体的语义建模和表达。
4 Sequence to Sequence Transduction with Hard Monotonic Attention
这篇论文[4] 的二作是 NLP 里良心出品的 Yoav Goldberg,所以第一时间找来读了。本文[4] 设计的 attention mechanism,也和第三篇论文[3] 有相似之处——比如都考虑了 decoder 端已经产生的 input。更独特的是,它融入了一种 hard attention 的思想,使得在 decoder 的过程中,decoder 并不是一直在 output(不是每个 step 都产生输出),而是像被一个 gate 控制一样,有的时候需要输出,有的时候则需要重新修改 attention 值(在 encoder 端进行 move)。那么这样的机制,比以往的经典的 soft attention 的好处在哪里呢?这是因为,soft attention 是比较依赖于 training data 才能自动学好这种 alignments 的,然而很多时候我们的小语料不存在足够多的能产生好 alignments 的数据 pair——这时候 hard attention 就能发挥出更好的作用了。
那么具体来讲,他们的主要改造其实就在于那个 control mechanism。这个模型不再只由 decoder 的 output 作为唯一 action,而是增加了 encoder 端 hard attention 的第二种 action:

所以,当在进行 training 的时候,就会在 step/write 两种 action 之间进行交替(不是稳定交替),只由当当前 action 是 write 的时候,output 才会输出;否则,当 action 是 step 的时候,encoder 端的 hard attention head 就会 move 一个位置,并且将新的 encoded representation 计算出来:
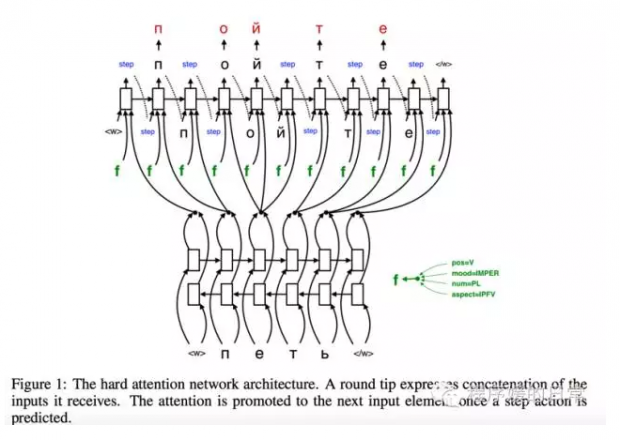
最后,为了对比这种他们提出的 hard attention 机制和经典 soft attention 机制的效果与作用,作者[4] 也画了如下的图:
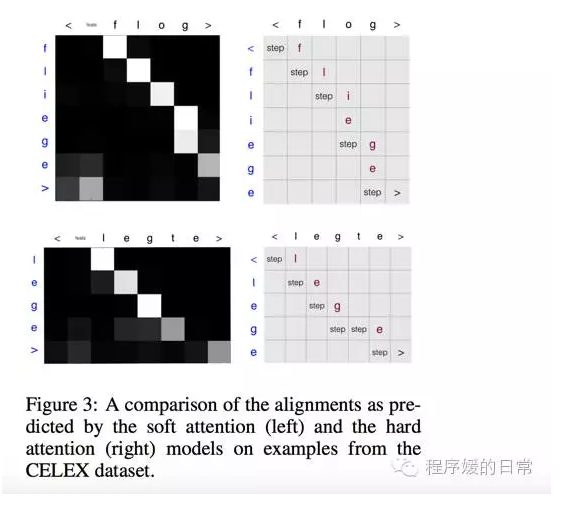
可以看到 legte->lege 和 flog->fliege 在 hard attention 机制(也就是作者[4] 提出的 model 上)都是如何被学出来的。
5 Memory-Augmented Attention Modeling For Videos
今天最后一篇要推荐的论文[5] 从题目就可以看出,把 attention 和 memory 结合在了一起。但其实我个人觉得,它主要结合上的贡献还是在于像论文[3] 一样,指出了 decoder 一边需要考虑 encoder端的 attention,一边还需要考虑自己的 language model generation,是很难 balance 的事情。更糟糕的是,因为他们[5] 做的是 video caption generation,这种多帧图片和每张图片中不同的 attention location 更加剧了这种 decoder 的困难。
于是乎,他们不仅提出了一种 temporal modeler(TEM)去选择每一帧(each frame)的 attention location,也继续提出了一种在 TEM 和 decoder language modeling 之间的建模函数,被他们称为 Hierarchical Attention/Memory(HAM):
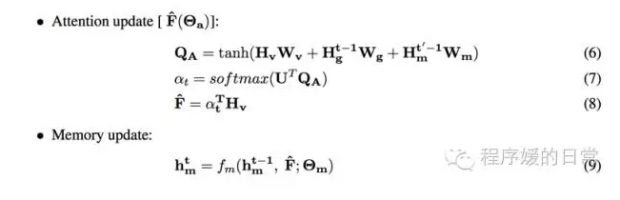
这里的 f_m 就可以实现一种 multi-layer 的 attention,然后这个 f_m 就可以传给 decoder 作为一种 balance 后的 attention。最终效果:

本文转载自「程序媛的日常」,搜索「girlswhocode」即可关注。作者 小s(李嫣然,集智科学家)。如需转载请与作者联系,谢绝二次转载。

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}