阅读:0
听报道
文 | 尹相志
中文理解与金融业
如今的人工智能已经在各个子领域中取得了突飞猛进的发展。现在的AI可以听、说、读、写,但是在自然语言的理解方面仍然存在着很大的不足。
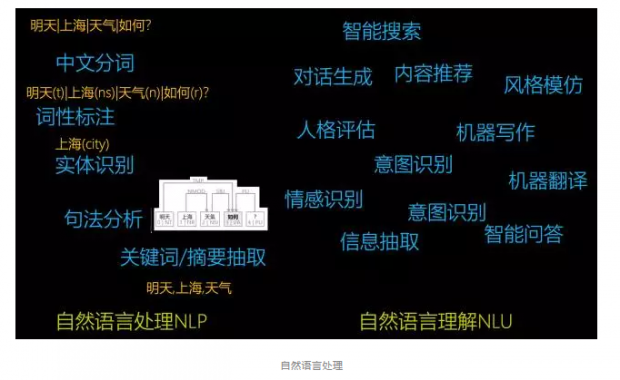
特别是,对于中文的处理恐怕是人类智力仅剩的堡垒之一。处理中文尤其困难是因为:
中文是世界上少数的几个需要分词的语言;
中文的字符(汉字)数量超多(20928);
能够依赖上下文产生相反的语义;
无需约定俗成就可以创造出新的文字。
比如,你们知道用中文表达「快递很快」有多少种表达方式吗?答案是3600多种讲法。
金融业是比较保守的行业,除非你的技术真的能解决它的痛点问题,否则它将不会采纳新的技术。那么金融的痛点问题都有哪些呢?
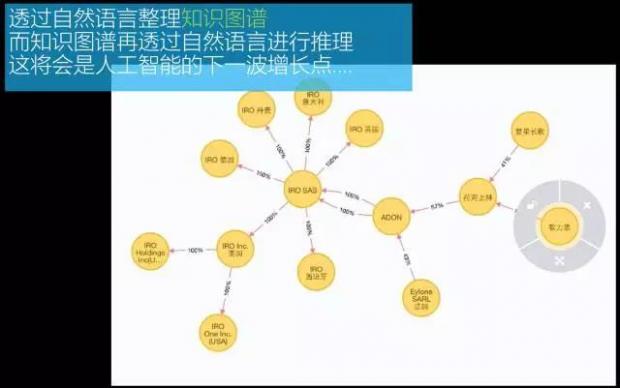
现在的金融从业人员正在阅读大量的合同、文本、网页等信息,从中提炼出重要的关键信息。而这些文本大多非常冗长难读,令人非常伤脑筋,而且还可能犯错误。下面,就让我们来看看这张图:

这样一段长长的冗余文字实际上就想表达这样的实体关系:
华夏幸福基业股份有限公司-->(父子公司)-->廊坊京御房地产开发有限公司
廊坊京御房地产开发有限公司-->(父子公司)-->廊坊市圣斌房地产开发有限公司
华能贵诚-->(向...增资)-->廊坊圣斌
华夏幸福-->(向...提供担保)-->京御地产
华夏幸福-->(向...提供担保)-->廊坊圣斌
实际上,实体-关系识别是金融行业中的最典型应用,如下列问题:法金授信、二级市场分析、个资掩码、授信照会、投资研究。
我们的技术可以透过自然语言整理知识图谱,而知识图谱再透过自然语言进行推理,这将会是人工智能的下一波增长点……
另外,利用Seq2Seq模型,我们可以利用自动对话数据理解或猜测出用户的「意图」(Intent),并同时识别「实体」(Entity)和产生「行动」(Action)。

词向量技术在金融中的应用
下面,我们展示我们利用词向量(Word2Vec)技术来自动而快速地生成实体列表和商务规则。
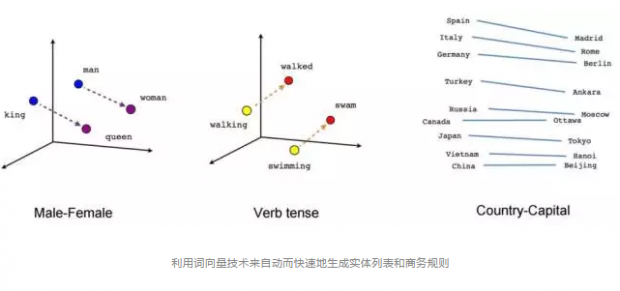
词向量技术是近年来发展出来的一种深度学习技术,它可以通过扫描文本而自动将每个单词嵌入到一个高维空间中,使得每个单词出现的位置都和它的上下文有关,相似的词可以得到相似的空间向量。另外,更有意思的是,词向量不仅能够表达实体单词,还能表达实体之间的关系,例如著名的公式:男人-女人=国王-王后,这里面的差向量就是男女关系这个向量。所以,利用词向量可以进行一定的类比思维。再比如右侧的图中,左侧的实体是国家,右侧的实体是城市,直线对应的是首都关系。
在我们的例子中,我们将词向量技术用于枚举出所有的币种。我们通过扫描大量的文本,可以得到每个单词的词向量,那么我们怎么把所有的货币的名称跳出来呢?答案很简单就是利用如下这个cos距离的公式,我们只要将与美元的距离+英镑的距离和最小的那些词向量所对应的实体列举出来就可以了。

这样,我们便可以枚举出如下的所有币种了:
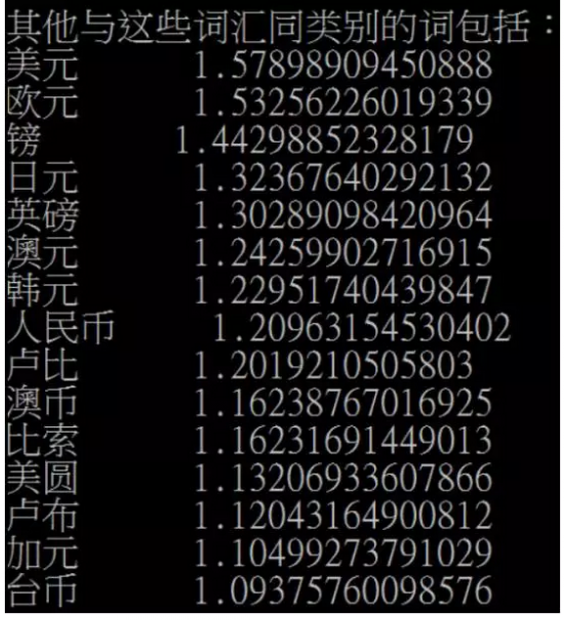
然而,利用这种方法无法排除歧义词的问题。
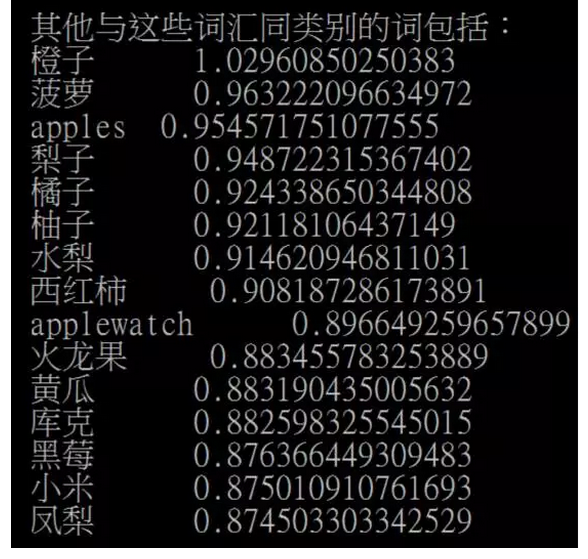
我们的解决方案是引入第三个词。这里有两种方法,一种是语义增强,一种是语义消岐。采用下面的两个公式分别能够做到这两点:

这样就可以得到我们希望要的结果了。但是这里的冰棒和雪糕还是有点怪怪的。

Brain of things公开比赛
下面,我想介绍一下我们华院数据今年的公开比赛:Brain of things,我们会在这里提前两天公开我们的赛题。在去年的比赛中,我们制定了比较变态的赛题,真的很难,但是大家答得都很好。
比如,我们的初赛试题是图像理解,这不是普通的识别,你要能够认出这张剪纸是一只狗,这是一只装扮成长颈鹿的狗,所以机器要对图像进行深层理解。
在复赛实体中,我们要对货架上的货品进行自动计数,进行盘点,这意味着你的程序要能够对20几种产品进行识别。当然,复赛还包括行车记录仪的应用。

而我们去年决赛的题目是看图理解,并用中文回答问题,这在全世界都是首例。这个题目超难,但还是有人给出了非常令人吃惊的成绩。

那么,下面我们来公布我们今年的题目,今年的初赛题目是寻找K线之王,就是让机器直接看K线图,从而判断出是否发生了上涨下跌、k线背离、阻力位、支撑位等。你注意,在这里我们不能简单地用卷积神经网络来做,因为不能够有权值共享。
我们的复赛题目是判断新闻中的蝴蝶效应,即评估出市场消息对股价影响的程度。也就是输入一段文字以及图片,判断出次日、第三日的涨跌幅,这样当出现一条消息之后,我们就可以用机器来做预判,而不必引起不必要的恐慌。

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}