阅读:0
听报道
文 | 张江
前言:
深度学习在新世纪的第二个十年强势崛起,连接学派暂时领先。然而人工智能始终源于多学科交叉,所以常常是外部力量改变了学科本身,那么人工智能的新变革会在哪里发生?让我们拭目以待。
前文概要:从80年代开始,机器学习进入人工智能舞台的中心,开启了符号学派、连接学派、行为学派三足鼎立的时代,直到深度学习在新世纪苏醒过来……
人工智能之梦——梦醒何方(2010至今)
就这样,在争论声中,人工智能走进了21世纪的第二个十年,似乎一切都没有改变。但是,几件事情悄悄地发生了,它们重新燃起了人们对于人工智能之梦的渴望。
深度学习
21世纪的第二个十年,如果要评选出最惹人注目的人工智能研究,那么一定要数深度学习(Deep Learning)了。
2011年,谷歌X实验室的研究人员从YouTube视频中抽取出1000万张静态图片,把它喂给“谷歌大脑”——一个采用了所谓深度学习技术的大型神经网络模型,在这些图片中寻找重复出现的模式。三天后,这台超级“大脑”在没有人类的帮助下,居然自己从这些图片中发现了“猫”。

2012年11月,微软在中国的一次活动中,展示了他们新研制的一个全自动的同声翻译系统——采用了深度学习技术的计算系统。演讲者用英文演讲,这台机器能实时地完成语音识别、机器翻译和中文的语音合成,也就是利用深度学习完成了同声传译。
2013年1月,百度公司成立了百度研究院,其中,深度学习研究所是该研究院旗下的第一个研究所。
……
这些全球顶尖的计算机、互联网公司都不约而同地对深度学习表现出了极大的兴趣。那么究竟什么是深度学习呢?
事实上,深度学习仍然是一种神经网络模型,只不过这种神经网络具备了更多层次的隐含层节点,同时配备了更先进的学习技术,如图1-13所示。
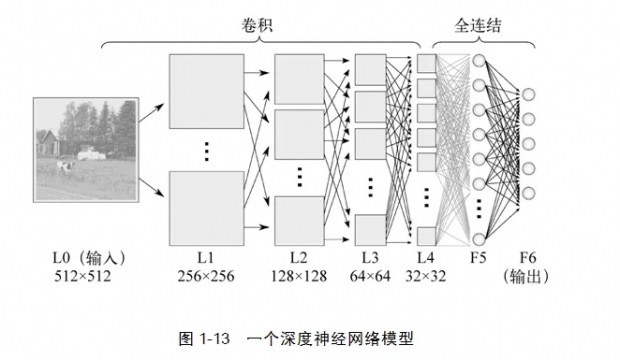
然而,当我们将超大规模的训练数据喂给深度学习模型的时候,这些具备深层次结构的神经网络仿佛摇身一变,成为了拥有感知和学习能力的大脑,表现出了远远好于传统神经网络的学习和泛化的能力。
当我们追溯历史,深度学习神经网络其实早在20世纪80年代就出现了。然而,当时的深度网络并没有表现出任何超凡能力。这是因为,当时的数据资源远没有现在丰富,而深度学习网络恰恰需要大量的数据以提高它的训练实例数量。
到了2000年,当大多数科学家已经对深度学习失去兴趣的时候,又是那个杰夫·辛顿带领他的学生继续在这个冷门的领域里坚持耕耘。起初他们的研究并不顺利,但他们坚信他们的算法必将给世界带来惊奇。
惊奇终于出现了,到了2009年,辛顿小组获得了意外的成功。他们的深度学习神经网络在语音识别应用中取得了重大的突破,转换精度已经突破了世界纪录,错误率比以前减少了25%。可以说,辛顿小组的研究让语音识别领域缩短了至少10年的时间。就这样,他们的突破吸引了各大公司的注意。苹果公司甚至把他们的研究成果应用到了Siri语音识别系统上,使得iPhone5全球热卖。从此,深度学习的流行便一发不可收拾。
那么,为什么把网络的深度提高,配合上大数据的训练就能使得网络性能有如此大的改善呢?答案是,因为人脑恰恰就是这样一种多层次的深度神经网络。例如,已有的证据表明,人脑处理视觉信息就是经过多层加工完成的。所以,深度学习实际上只不过是对大脑的一种模拟。
模式识别问题长久以来是人工智能发展的一个主要瓶颈。然而,深度学习技术似乎已经突破了这个瓶颈。有人甚至认为,深度学习神经网络已经可以达到2岁小孩的识别能力。有理由相信,深度学习会将人工智能引入全新的发展局面。本书第6章将详细介绍深度学习这一全新技术,第14章将介绍集智俱乐部下的一个研究小组对深度学习技术的应用——彩云天气,用人工智能提供精准的短时间天气预报。
模拟大脑
我们已经看到,深度学习模型成功的秘诀之一就在于它模仿了人类大脑的深层体系结构。那么,我们为什么不直接模拟人类的大脑呢?事实上,科学家们已经行动起来了。
例如,德国海德尔堡大学的FACETS(Fast Analog Computing with Emergent Transient States)计划就是一个利用硬件来模拟大脑部分功能的项目。他们采用数以千计的芯片,创造出一个包含10亿神经元和1013突触的回路的人工脑(其复杂程度相当于人类大脑的十分之一)。与此对应,由瑞士洛桑理工学院和IBM公司联合发起的蓝色大脑计划则是通过软件来模拟人脑的实践。他们采用逆向工程方法,计划2015年开发出一个虚拟的大脑。
然而,这类研究计划也有很大的局限性。其中最大的问题就在于:迄今为止,我们对大脑的结构以及动力学的认识还相当初级,尤其是神经元活动与生物体行为之间的关系还远远没有建立。例如,尽管科学家早在30年前就已经弄清楚了秀丽隐杆线虫(Caenorhabditis elegans)302个神经元之间的连接方式,但到现在仍然不清楚这种低等生物的生存行为(例如进食和交配)是如何产生的。尽管科学家已经做过诸多尝试,比如连接组学(Connectomics),也就是全面监测神经元之间的联系(即突触)的学问,但是,正如线虫研究一样,这幅图谱仅仅是个开始,它还不足以解释不断变化的电信号是如何产生特定认知过程的。
于是,为了进一步深入了解大脑的运行机制,一些“大科学”项目先后启动。2013年,美国奥巴马政府宣布了“脑计划”(Brain Research through Advancing Innovative Neurotechnologies,简称BRAIN)的启动。该计划在2014年的启动资金为1亿多美元,致力于开发能记录大群神经元甚至是整片脑区电活动的新技术。
无独有偶,欧盟也发起了“人类大脑计划”(The Human Brain Project),这一计划为期10年,将耗资16亿美元,致力于构建能真正模拟人脑的超级计算机。除此之外,中国、日本、以色列也都有雄心勃勃的脑科学研究计划出炉。这似乎让人们想到了第二次世界大战后的情景,各国争相发展“大科学项目”:核武器、太空探索、计算机等。脑科学的时代已经来临。关于人脑与电脑的比较,请参见本书第7章。
“人工”人工智能

2007年,一位谷歌的实习生路易斯·冯·安(Luis von Ahn)开发了一款有趣的程序“ReCapture” 却无意间开创了一个新的人工智能研究方向:人类计算。
ReCapture的初衷很简单,它希望利用人类高超的模式识别能力,自动帮助谷歌公司完成大量扫描图书的文字识别任务。但是,如果要雇用人力来完成这个任务则需要花费一大笔开销。于是,冯·安想到,每天都有大量的用户在输入验证码来向机器证明自己是人而不是机器,而输入验证码事实上就是在完成文本识别问题。于是,一方面是有大量的扫描的图书中难以识别的文字需要人来识别;另一方面是由计算机生成一些扭曲的图片让大量的用户做识别以表明自己的身份。那么,为什么不把两个方面结合在一起呢?这就是ReCapture的创意(如图1-14所示),冯·安聪明地让用户在输入识别码的时候悄悄帮助谷歌完成了文字识别工作!

这一成功的应用实际上是借助人力完成了传统的人工智能问题,冯·安把它叫作人类计算(Human Computation),我们则把它形象地称为“人工”人工智能。除了ReCapture以外,冯·安还开发了很多类似的程序或系统,例如ESP游戏是让用户通过竞争的方式为图片贴标签,从而完成“人工”人工分类图片;Duolingo系统则是让用户在学习外语的同时,顺便翻译一下互联网,这是“人工”机器翻译。
也许,这样巧妙的人机结合才是人工智能发展的新方向之一。因为一个完全脱离人类的人工智能程序对于我们没有任何独立存在的意义,所以人工智能必然会面临人机交互的问题。而随着互联网的兴起,人和计算机交互的方式会更加便捷而多样化。因此,这为传统的人工智能问题提供了全新的解决途径。
然而,读者也许会质疑,这种掺合了人类智能的系统还能叫作纯粹的人工智能吗?这种质疑事实上有一个隐含的前提,就是人工智能是一个独立运作的系统,它与人类环境应相互隔离。但当我们考虑人类智能的时候就会发现,任何智能系统都不能与环境绝对隔离,它只有在开放的环境下才能表现出智能。同样的道理,人工智能也必须向人类开放,于是引入人的作用也变成了一种很自然的事情。关于这个主题,我们将在本书第8章和第9章中进一步讨论。
结语
本章介绍了人工智能近60年所走过的曲折道路。也许,读者所期待的内容,诸如奇点临近、超级智能机器人、人与机器的共生演化等激动人心的内容并没有出现,但是,我能保证的,是一段真实的历史,并力图做到准确无误。
尽管人工智能这条道路蜿蜒曲折,荆棘密布,但至少它在发展并不断壮大。最重要的是,人们对于人工智能的梦想永远没有破灭过。也许人工智能之梦将无法在你我的有生之年实现,也许人工智能之梦始终无法逾越哥德尔定理那个硕大无朋的“如来佛手掌”,但是,人工智能之梦将永远驱动着我们不断前行,挑战极限。
推荐阅读
关于希尔伯特、图灵、哥德尔的故事和相关研究可以阅读《哥德尔、艾舍尔、巴赫:集异璧之大成》一书。
关于冯·诺依曼,可以阅读他的传记:《天才的拓荒者:冯·诺依曼传》。关于维纳,可以参考他的著作《控制论》。
若要全面了解人工智能,给大家推荐两本书:Artificial Intelligence: A Modern Approach和Artificial Intelligence: Structures and Strategies for Complex Problem Solving。
了解机器学习以及人工神经网络可以参考Pattern Recognition和Neural Networks and Learning Machines。
关于行为学派和人工生命,可以参考《数字创世纪:人工生命的新科学》以及人工生命的论文集。
若要深入了解贝叶斯网络,可以参考Causality: Models, Reasoning, and Inference。
深入了解胡特的通用人工智能理论可以阅读Universal Artificial Intelligence: Sequential Decisions Based on Algorithmic Probability。
关于深度学习方面的知识可参考网站:,其中有不少综述性的文章。
人类计算方面可以参考冯·安的网站:~biglou/。
参考文献
1 候世达,严勇,刘皓. 哥德尔、艾舍尔、巴赫:集异璧之大成. 莫大伟 译. 北京:商务印书馆,1997.
2 诺曼·麦克雷. 天才的拓荒者:冯·诺伊曼传. 范秀华,朱朝辉 译. 上海:上海科技教育出版社,2008.
3 维纳. 控制论:或关于在动物和机器中控制和通信的科学. 郝季仁 译. 北京:北京大学出版社,2007.
4 Luger G F. Artificial intelligence: structures and strategies for complex problem solving (6th Edition). Addison-Wesley, 2008.
5 Russel S K, Norvig P. Artificial Intelligence: A Modern Approach (2nd Edition). Prentice Hall, 2002.
6 Theodoridis S, Koutroumbas K. Pattern Recognition (2nd edition). Academic Press, 2008.
7 Haykin S O. Neural Networks and Learning Machines (3rd Edition). Prentice Hall, 2000.
8 李建会,张江. 数字创世纪:人工生命的新科学. 北京:科学出版社,2006.
9 Pearl J. Causality: models, reasoning, and inference. Cambridge University Press, 2000.
10 Hutter M. Universal Artificial Intelligence:Sequential Decisions based on Algorithmic Probability. Springer, 2005.
作者简介
张江,集智俱乐部主要发起人和核心成员,2014~2015年度集智轮值主席。现在北京师范大学系统科学学院任教,教授。主要从事有关计算机模拟和人工智能的教学工作以及复杂系统的相关研究工作。研究兴趣包括异速生长律、开放流网络、注意力流与互联网等。代表作品有:论文Allometry and dissipation of ecological flow networks(PLoS ONE 2013, 8(9): e72525.)、论文The Metabolism and Growth of Web Forums (PLoS ONE 20149(8): e102646),著有《数字创世纪:人工生命的新科学》(科学出版社,2006)一书。
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}