
2018年3月25日,腾讯研究院和集智俱乐部联合举办的AI&Society系列沙龙第四期在南京大学新闻与传播学院如期举行。集智科学家、南京大学新闻与传播学院副教授王成军以及他的两位学生(陈志聪:南京大学新闻与传播学院硕士研究生;徐绘敏:南京大学信息管理学院本科生)围绕“社会阶层与数字媒体中的注意力流动”展开了一场颇具启发意义的探讨。这篇文章是徐绘敏的现场报告总结稿。我们将会继续发布该系列总结,敬请关注。
1.发现:不同社会阶层的人群,
注意力流动和物理移动都大不相同
先上结论:
和低社会阶层相比,高社会阶层人群更多使用大众化的 APP 组合,更少出现在公众场所,这是我们隐约发现的规律。
图1(A-C)的横坐标都是一个2*2的分布,第一个2代表两个网络——注意力网络和移动网络,第二个2是根据median将median z-score 分成两个部分——高常见节点组合和低常见节点组合。
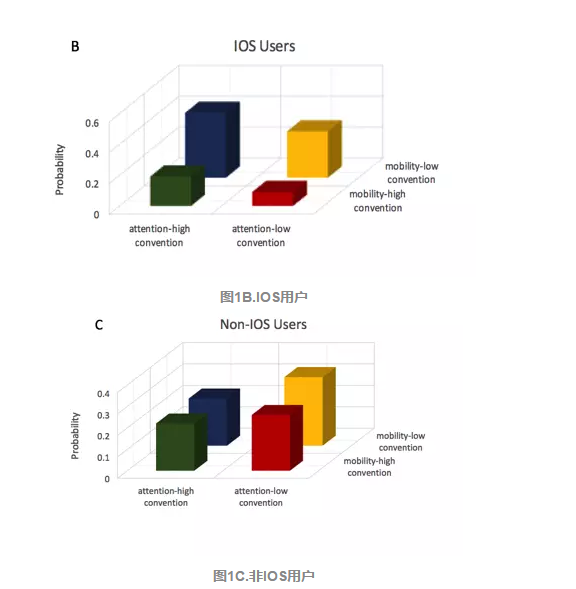
图1(A)中,对用户的手机终端价格和付费进行排序,将前10%的人看作是更高阶层的人,纵坐标代表的是在这四类中出现更高阶层人的可能性,可以看出蓝色柱子是最高的,高达14%,说明这一类人中,100个人有14个人是更高阶层。在图6(B)和图6(C)中,这个结论也得到了验证,把IOS系统的使用者看作是更高阶层的人,非IOS系统的使用者看作是较低阶层的人。
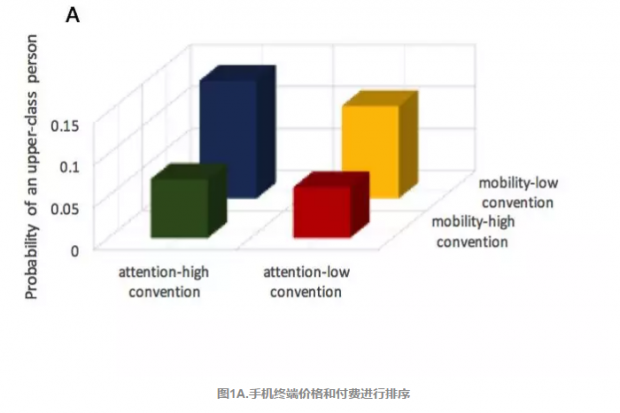
图1(B)中同样是蓝色柱子最高,图1(C)中蓝色柱子最低。说明更高阶层的人在注意力网络上会更多浏览常见组合的APP,选择更加大众、受欢迎的APP;而移动网络中更多停留在不常见组合的地理位置,少去公众场所。对更低阶层的人则相反。
这说明阶层确实会影响用户的移动轨迹,无论是注意力流动还是物理移动上。但这个现象背后的机制是什么呢?有什么更深层次的原因导致阶层影响轨迹,这需要我们进一步探索。
2.探索:富人穷人之所以不同
可能是下面这些原因
进一步探索我们发现:穷人富人在 APP 使用和日常位置上的差异,背后的原因可能是他们在作息时间、文娱方式、生活需求等方面的差异。
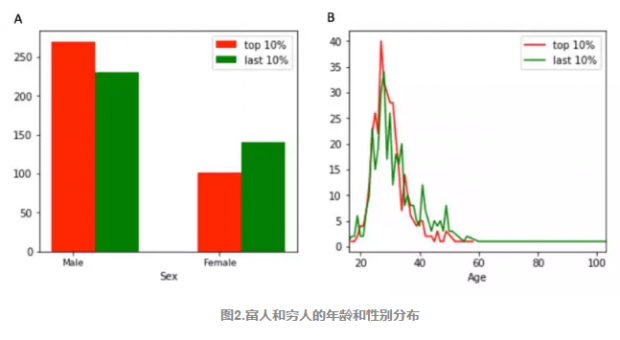
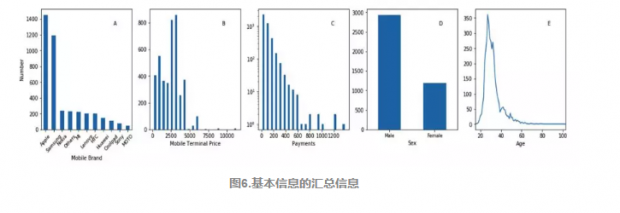
为了进一步探索,我们选取了前10%和后10%这两类人,选取方法同样是根据手机终端价格和付费情况,这两类人也可以更加突出比较。图7是这两类人的性别和年龄分布。性别上,前10%中(富人)男性居多,后10%中(穷人)则相反。在年龄分布上并没有显著差异。
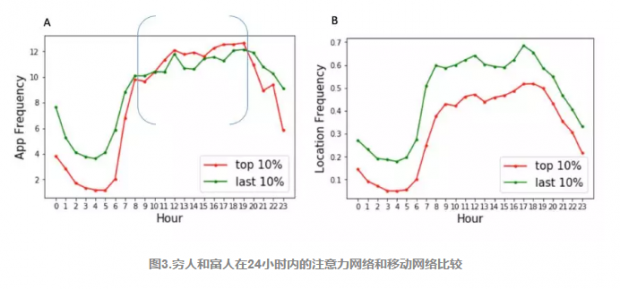
H1:不同阶层的人有不同的作息习惯,所以有不同的轨迹。
图3的横坐标代表一天的24个小时,图3(A)代表在一天的各个时段,APP被触发的平均次数,可以看到,在休息时间晚上7点后到早上8点前,富人使用手机频次明显比穷人少,而工作时间段富人则要比穷人多一些。
图3(B)代表在一天的不同时间段走过不同地理位置的平均个数,可以看到无论在什么时候,穷人走的地方都比富人多。所以说即使在晚上,穷人也没有睡,也在使用手机和行走。相比之下,富人有更加规律的作息习惯。
H2:不同阶层的人有不同的生活方式,所以有不同的轨迹。
我们使用每一类的APP来衡量生活方式的一个部分。图9代表在一天不同时间段使用各类APP的情况。
图4(A-C)代表视频、游戏和音乐一类的娱乐化APP,穷人在视频和游戏类APP的使用上都比富人频次高,而富人更经常听音乐。说明无论是穷人还是富人,都有自己的娱乐方式,但娱乐方式又各有侧重,游戏和视频都需要更多的注意力,而你却可以一边听音乐一边干其他事。
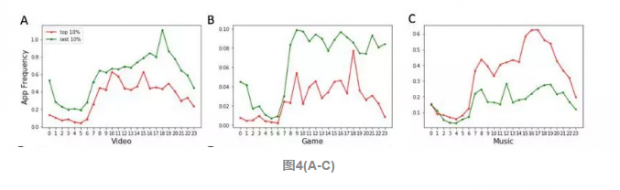
图4(D-E) 表示读这种行为,富人更偏向于读新闻资讯类的APP,而穷人则要偏向普通类的APP阅读,但富人在上班早高峰时间在普通阅读类APP使用更多。
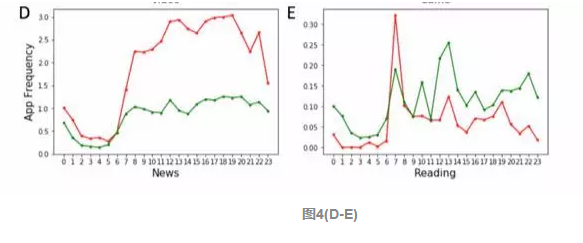
图4(F-G)代表社交沟通,社区论坛,穷人的使用频次都是比富人高的,而且可以看出穷人晚上在社区论坛,社交沟通的APP上特别活跃。
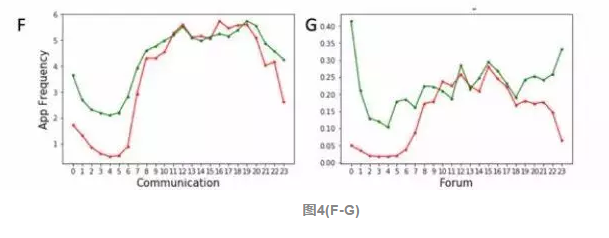
图4(H-I) 是邮箱和导航,穷人很晚还在使用邮箱,很早就开始使用导航,说明他们可能还在工作。所以穷人里面可能有两类人,一类一直活跃在论坛里无所事事,一类人迫于经济压力还在辛苦工作。
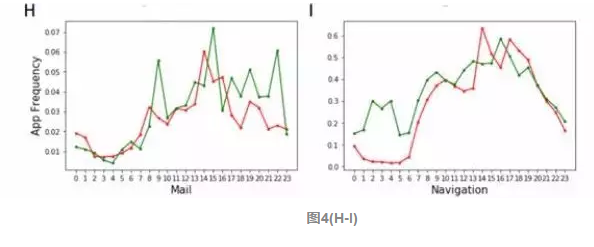
图4(J-L)是网页浏览、搜索和软件工具,穷人在网页浏览,搜索和软件工具的频繁使用也说明他们在注意力网络比富人有更多的探索,符合我们得到的结论,富人在APP使用上更大众,更传统。
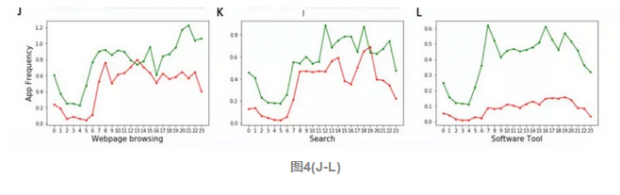
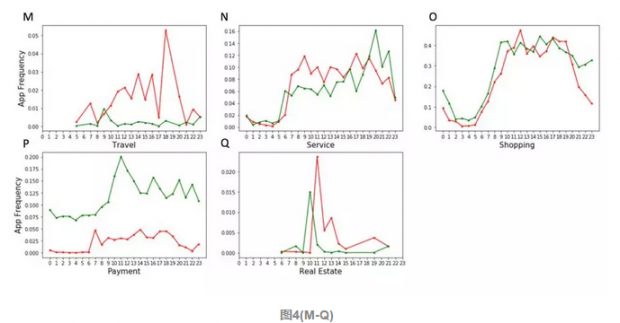
图4(M)表示旅游,富人使用更多。图4(N)表示服务,穷人在晚上使用更多。图4(O)中穷人和富人白天在购物上并没有太大区别,但穷人在晚上会看得多一些。图4(P)中穷人在打开支付、银行类的APP上更多。最后一张图4(Q)中,富人在房产信息的关注和穷人并没有差太多,因为点开频次都很少。
总体来看,穷人使用APP比富人多,可以说,在娱乐、阅读、沟通、工作这些生活方式上,穷人和富人都有显著差别。
H3: 不同阶层的人有不同的需求,所以有不同的轨迹。
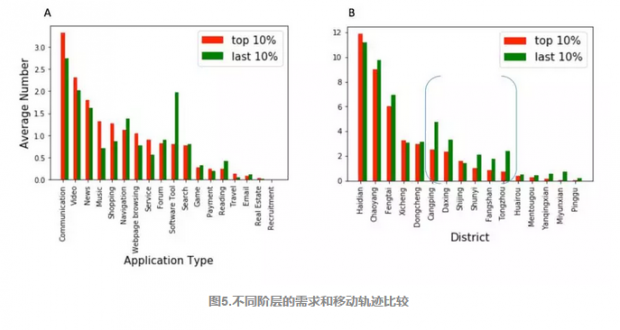
图5(A)是看两类人在各类APP中使用的不同APP个数,可以看出富人在沟通类APP的使用个数更多,说明富人出于社交或工作需求,需要使用更多不同的APP,但富人在沟通类APP上使用并没有穷人频繁。这并不矛盾,是广度和深度两个维度的考量,富人在社交类需求更广泛,但使用不够深入。而穷人在导航和软件工具类需求更多。
图5(B)是将地理位置按所在区来划分,除了北京的海淀区,穷人在其他区的平均停留次数都比富人多,尤其是在括号中的北京近郊,说明穷人出于工作,生活或游玩的需求,需要在这些地方更多的停留。
3.数据:什么支撑了这项研究
数据集由两个部分构成。第一个部分是用户的基本信息,包括手机型号、终端价格(手机类型+型号)、付费记录(话费+流量费+业务订购)、性别和年龄(图1),使用这些信息可以匹配到用户的所属阶层。第二部分是用户的行为信息,用户打开手机APP的在线操作、时间和地理位置会被记录,使用这些行为信息可以对应到用户所在的虚拟空间的注意力网络和现实空间的移动网络。
4.方法:如何描述用户在网络中移动
我们使用的是Uzzi的Z-score方法来构建两个加权的相似性网络。在注意力网络中,我们把用户访问的手机APP看作是节点。同样的,在移动网络中,我们把用户所在的地理位置看作是节点。用Z-score来计算网络中任意两个节点之间连接的权重:Z-score = (obs-exp) /σ,obs是观察值,exp是期望值,σ是标准差。
以注意力网络为例(图7和图8),将每一个用户浏览过的手机APP进行两两组合,再将所有用户的两两组合进行累加,这样我们就得到了观察网络中的权重值。
为了得到期望值,我们需要构建随机网络。所以重新回到个人层面,将整个APP列表打乱,再将每个人浏览的APP两两组合,所有人的组合累加,将这个过程重复10次,就得到了10个随机网络。对10个随机网络中得到的权重值取平均和标准差,就得到了公式中的期望值和标准差。
这个公式的目的就是为了得到一个标准化和去偶然性的权重值。标准化是为了便于比较,去偶然性是为了得到更加真实的值。
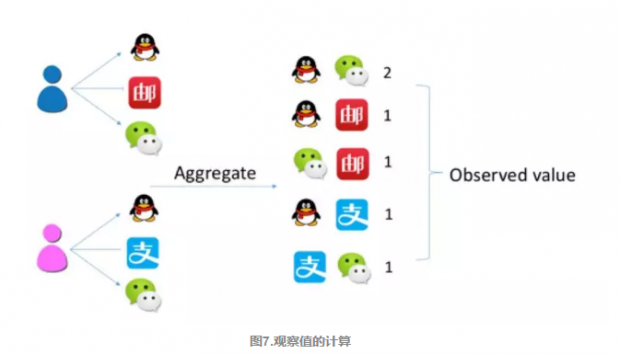
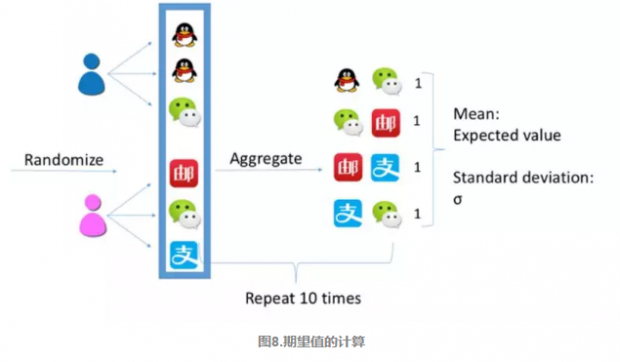
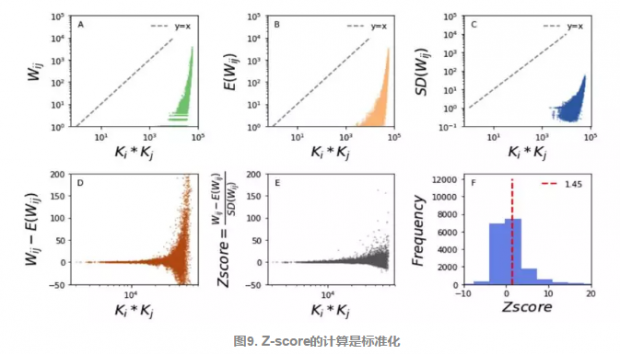
图9证明了Z-score的计算是标准化并去除由于自身因素而带来的偶然性。横坐标ki*kj代表的是注意力网络中任意两个APP被访问次数的乘积,代表的是APP自身的受欢迎程度。在图9 (A-C)中,无论是观察网络中的权重值,还是随机网络中的权重值和标准差,和ki*kj都是呈线性相关。但在图 (D-E)中,当两个权重值相减,再除以标准差,我们会发现线性关系消失了,并且y值不断的趋向于0。
用同样的方法应用于移动网络,也是一样的。
所以我们使用Z-score方法就构建好了两个网络,就可以去描绘每个人的轨迹。
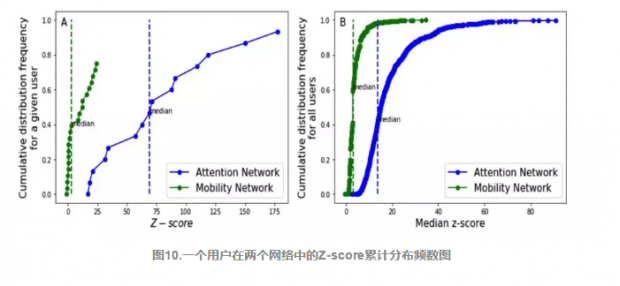
图10(A)是以一个用户为例,在两个网络中的Z-score累计分布频数图。虚线代表中位数,作为统计量,可以衡量用户的轨迹情况。
图10(B)统计了所有用户的中位数,得到了median Z-score的累计分布频数图,同样用虚线标出了median值,将个人的median Z-score和所有用户的median值进行比较。小于median值的,说明用户的轨迹主要停留在不常见的节点组合,相较而言比较创新;大于median值的,说明用户的轨迹主要停留在常见的节点组合,相较而言比较传统。
5.总结:精力有限,
去做有意义的事吧
最后,总结一下,个人的精力和体力都是有限的,如何管理这些自身有限资源是区分阶层的一个重要标准。富人会节约体力少去公众场所,把注意力放在更大众更满足自己需求的APP上,并且规律作息。而穷人随着数字媒体的普及,注意力更加碎片化和分散;固有的阶级又限制了他们在地理空间的探索,一方面需要走更多的地方,一方面又只能停留在常见的场所。
参考文献
[1] Uzzi B, etal. Atypical combinations and scientific impact. Science (New York, N.Y.) 342.6157(2013):468-72.
[2]Wu L, and Wang CJ. Tracing the Attention of Moving Citizens. Scientificreports 6(2016):33103.
[3]Webster, James G., and T. B. Ksiazek. The Dynamics of Audience Fragmentation:[4] Public Attention in an Age of Digital Media. Journal of Communication 62.1(2012):39–56.

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}