
导语:由于现实图片往往具有多个物体和复杂的背景,目标检测一直是计算机视觉领域研究的难点也是热点。其中,对于目标尺度的差异卷积神经网络模型没有应对的内在机制。ICCV 2017 的一篇论文中,设计了更优雅更快速地处理人脸检测中的尺度问题的方案,下面是对这篇论文的解读。
论文标题:
Recurrent Scale Approximation for Object Detection in CNN
论文地址:
论文作者:Yu Liu, Hongyang Li , Junjie Yan , Fangyin Wei , Xiaogang Wang, Xiaoou Tang(刘宇,李弘扬,闫俊杰,尉方音,王晓刚,汤晓鸥)
面对一张图片,人类可以轻易地判断图片上的内容,区分图片上各个不同的物体并进行定位。但是对于计算机来说,一张图片仅仅只是RGB的像素矩阵,如何教会计算机能够自动地像人类一样从这些像素信息中获取整张图片上的内容信息从而完成图像分类、目标检测、语义分割等任务,这就是计算机视觉主要研究的问题。
刚开始接触计算机视觉通常都是从图像识别开始的,图像分类就是根据图像的内容将图像打上类别标签,比如作为新手入门“典范”的MNIST手写体识别数据集就是对包含手写数字0~9的图片判断图片上的数字。

但是一般情况下现实中的图片包含有十分复杂的场景和物体,粗糙地对图片打上某一类标签并不能满足我们的需要,此时就是目标检测大展身手的时候了。
目标检测通俗来说就是想要知道图像上有什么物体分别在图像的什么位置。目标检测的任务有两个:一个是分辨出图片上有什么物体,即分类任务;另一个是找到这些物体在图片上的位置,即定位任务,通常会以边界框(bounding box)来表示物体的位置。目标检测作为计算机视觉的重要方向被广泛应用于人脸识别、自动驾驶以及其他的大量有价值的方向。
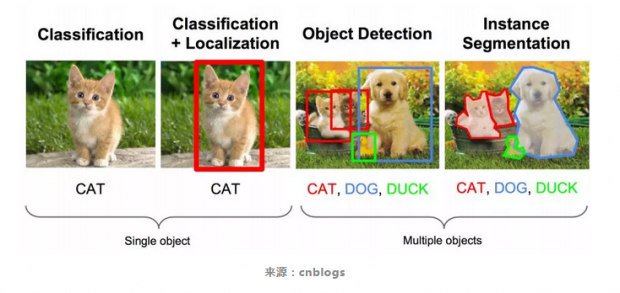
由于现实图片往往具有多个物体和复杂的背景,目标检测一直是计算机视觉领域研究的难点也是热点。在深度学习引入以前,早期的目标检测算法大多都是基于手工特征构建,比如行人检测使用的HOG特征,人脸检测使用的Harr特征。
但是,手工提取的特征表达能力会受到提取特征方法的限制,往往只能针对特定目标提出特定的提取特征的方法,缺乏灵活性。大家想到有没有一种通用的方法能使提取出来特征更加鲁棒,表达能力更强呢?
有!没错,就是深度学习。
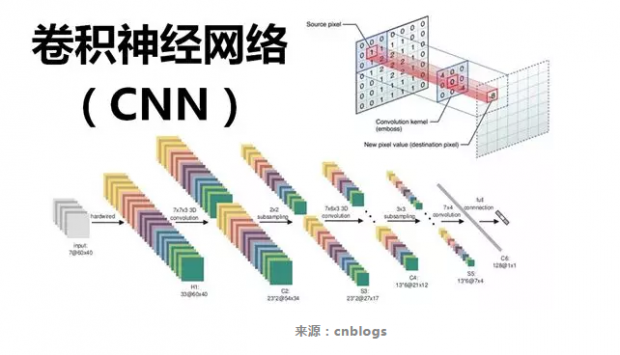
深度学习中的卷积神经网络(CNN)在图像分类领域可以说是大获成功。随着对卷积神经网络研究的加深特别是迁移学习的成功应用,研究者们想到可以将卷积神经网络作为目标检测的特征提取器。Girshick等人[1]在2013年提出了R-CNN模型并且在VOC 2007数据集上一下子将mAP从33.7%(DPM-v5 传统方法)提高到58.5%。
R-CNN论文传送门:
自此,目标检测进入了深度学习的时代。2013年以来,目标检测领域涌现出了一系列应用深度学习的方法,在速度和准确度上也不断提高。

论文核心思路
我们今天要介绍的这一篇文章(),是一篇比较新的目标检测方面的论文,主要想解决的是如何更优雅更快速地处理人脸检测中的尺度问题。
对于目标检测的任务来说,需要应对的主要问题是目标在不同图像中具有外观、位置和尺寸的差异。外观差异可以通过卷积和池化的操作得到缓解,位置差异可以使用滑窗解决,但是对于目标尺度的差异问题,卷积神经网络模型没有应对的内在机制。
对此,通常的解决方式有两种,如图1中的(a),(b)。
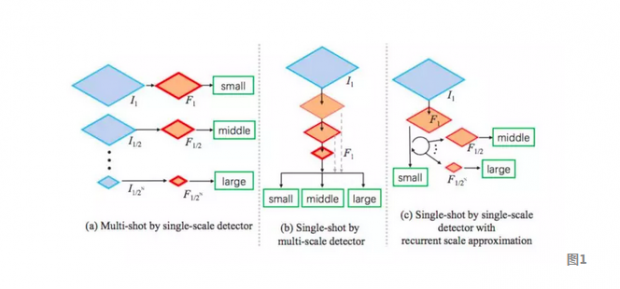
第一种解决方案:单尺度检测器和多尺度输入图像(Multi-shot by single-scale detector).如图1(a)所示,将原图放缩成不同的尺度从而能够得到一个固定尺度的目标。图中的small,middle,large代表的是目标也就是人脸的尺度大小,如果人脸的尺度很大,那么就需要我们将原图缩放到一个更小的尺度从而得到一个固定的尺度。这种方法的召回率取决于原图采样的尺寸是否足够密集,缺点也很明显,就是计算花费太高,而且假正例也会较多。
第二种解决方案:多尺度检测器和单尺度输入图像(Single-shot by multi-scale detector ).如图1(b)所示,将原图前传一次然后同时从不同尺度的特征图上检测目标和定位。而图1(c)则是作者提出的应对目标多尺度的方法。考虑到生成不同尺度的特征图是限制检测速度的瓶颈,作者希望通过改进特征图的生成来减少计算花费。
模型结构
很好,把握到作者主要想解决的问题之后,让我们从框架的整体角度解读一下作者具体是如何设计解决问题的。算法流程如图2所示:
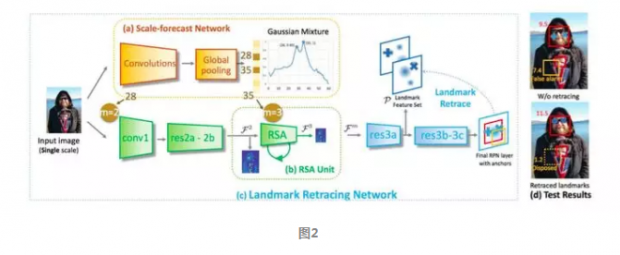
首先图片进入第一部分的尺度预测网络(scale-forecast network,如图2(a)),尺度预测网络负责对人脸的尺度做出一个估计预测。然后将人脸尺度的预测结果传给第二部分的循环尺度估计单元recurrent scale approximation(RSA)unit(如图2(b)),循环尺度估计单元能够产生预测的人脸尺度所对应的特征图。
由此作者解决了一开始想要解决的问题:人脸检测中的尺度问题。
得到了所需尺度的特征图后,剩下的就是在特征图的基础上进行检测和定位了。这部分的任务使用图2(c)landmark retracing network (LRN) 负责。LRN使用了RPN(region proposal network)用于检测特征点,然后使用一个回溯机制来修正RPN预测为正例的样本得分,解决假正例的问题。以上就是作者提出的算法的流程。作者通过尺度预测网络对人脸的尺度做出估计,然后根据估计尺度直接经过RSA单元产生对应尺度的特征图后进行预测,缩短了一般情况下得到特征图的计算流程,节省了大量的计算,加快了人脸检测的速度。
RSA单元
下面我们来分析一下RSA单元是如何工作的,也是这篇文章中的核心。假设原图为I,图片I经过下采样后尺寸变为原来的1/2m表示为Im 。如果我们定义图片I经过res2b(文中使用ResNet-18)层输出的特征图为:

总的来说RSA(·)是从输入的最大尺度的特征图到所需的1/2m倍的特征图的一个近似。相比先将图片I放缩m倍然后通过卷积网络得到特征图的方式,通过RSA(·)来计算特征图消耗的计算量要小得多。
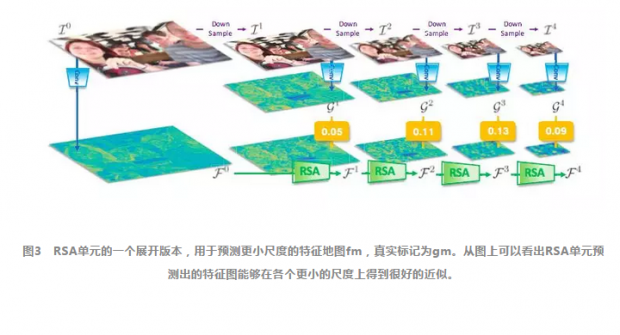
主要结论
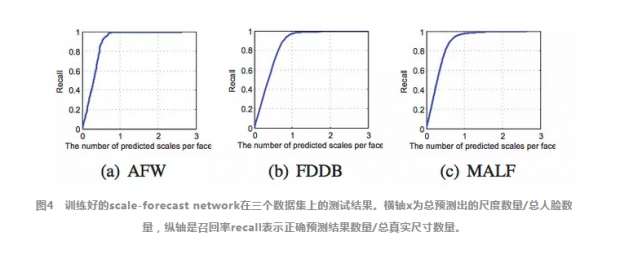
从召回率上来看,在x=1时召回率几乎是99%,意味着平均一张人脸只需要不到两个预测结果即可找到所有的人脸尺度。
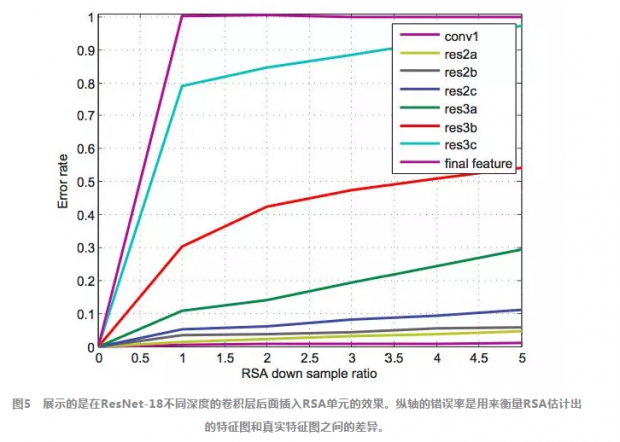
从图上容易得到两个结论:
1.在越深的层插入RSA单元,RSA的性能越差。在最后一层插入的错误率甚至将近100%。这个结果说明深层的抽象特征几乎没有信息让RSA来对更小尺度的特征图进行推断。考虑到RSA插入在浅层的计算开销要远高于深层,所以要在计算开销和错误率之间取一个权衡。
2.蝴蝶效应。随着循环推断次数的增加,错误率也在不断升高。
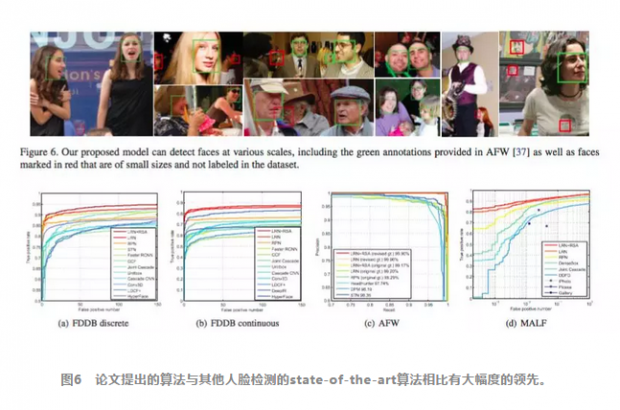
结语
这篇论文继承了近年来目标检测领域的许多杰出算法的思想,提出了尺度预测网络和RSA单元,很好地应对了人脸检测中的尺度变化,同时节省了大量计算,最后同样改进了预测模型,对于人脸检测达到了state-of-the-art。
作者:李时嘉
审校:尉方音
编辑:王怡蔺

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号