
导语:最近邻问题探寻的是将数据点插入现有数据集的最佳位置。有一些研究人员本打算证明并没有通用的方法来解决它,然而结果正相反,他们找到了这样一种普适性算法。
编译:集智俱乐部翻译组
来源:quantamagzine
原题:
Universal Method to Sort Complex Information Found
如果您正打算开一家咖啡店,那么您肯定想知道一个问题的答案:最近的一家咖啡馆在哪里? 这一信息可以帮助您了解竞争对手。
这是在计算机科学中被广泛研究的一种被称为“最近邻点”搜索问题的一个例子。 它讨论的是,在给定现有数据集和新数据点的情况下,现有数据中哪个点最接近新点? 在基因组学研究、图像搜索和Spotify推荐等许多日常情况中,这是一个经常出现的问题。
与咖啡店的例子不同,最近邻问题通常很难回答。 在过去的几十年中,计算机科学领域的顶尖人才一直致力于寻找能更好解决该问题的方法。
具体来说,他们一直着重于解决由于不同的数据集对于两个点彼此“接近”的定义的不同带来的各种问题。
现在,计算机科学家团队已经提出了解决最近邻问题的全新方法。 在接连两篇论文中,五位计算机科学家详细阐述了解决复杂数据最近邻问题的第一种通用方法。
“这是第一次实现使用单一算法处理多种不同空间,”麻省理工学院计算机科学家Piotr Indyk说,他在最近邻搜索算法研究中颇有影响力。
距离差异
当我们已经完全习惯了一种定义距离的方法,就很容易忽视其他可能的方法。 我们通常使用欧氏距离来测量距离,即在两点之间绘制直线。 但是在某些情况下,距离的其他定义更有意义。
例如,“曼哈顿”距离迫使您进行90度转弯,就像您在街道上行走一样。 使用曼哈顿距离,乌鸦只需飞行到5英里到的地方,可能需要您先走3英里穿过商业区,然后走4英里穿过住宅区。
也可以用非地理学的术语来考虑距离概念。 Facebook上的两个人、两部电影或两个基因组之间的距离是多少? 在这些例子中,“距离”意味着这两件事有多相似。
研究中存在许多距离测度,每个测度适合于特定类型的问题。 以两个基因组为例,生物学家使用“编辑距离(edit distance)”比较它们。使用编辑距离,两个基因序列之间的距离是将一个转换为另一个所需添加、删除、插入和替换操作的次数。
编辑距离和欧几里德距离是两个完全不同的距离概念 —— 没有办法用一个替换另一个。对于许多距离度量对而言,这种不可通约性也存在,这对于尝试开发最近邻居算法的计算机科学家来说是一个挑战。 这意味着适用于一种距离的算法对另一种距离不起作用。
——直到本文所述的新搜索方式出现。
调整圆圈
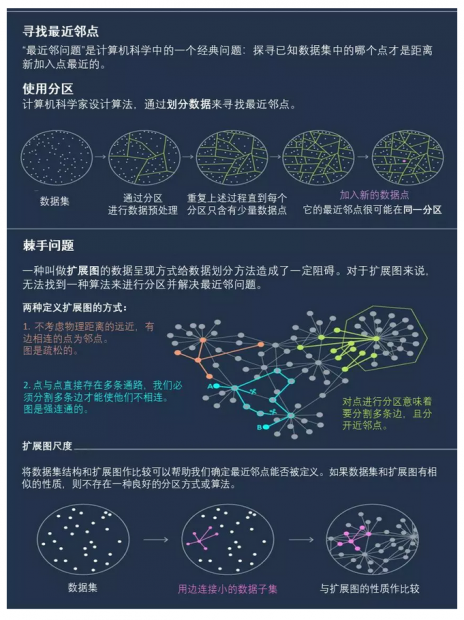
要查找最近邻点,标准方法是将现有数据分组。
想象一下,例如,您的数据是牧场中奶牛的位置。 在奶牛群周围画圈。 现在在牧场放一头新牛,问它将落入哪个圆圈?很有可能 —— 甚至可以保证 ——你的新牛的最近邻居也在那个圈子里。
然后重复这个过程。 将您的圆圈划分为子圆圈,对这些分区进行分区,依此类推。 最终,您将得到一个仅包含两个点的分区:一个现有点和新点,而现有的点就是你新点的最近邻点。
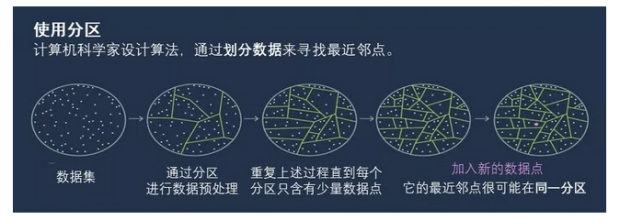
这些分区由算法来绘制,且好的算法会又快又好地完成划分 -——“好”意味着不可能出现最终你的新牛落入一个圆但最近的邻居站在另一个圆圈的情况。
微软研究院的计算机科学家Ilya Razenshteyn说:“对于这些分区,我们希望相互接近的点最终会出现在同一分区中,且距离较远的点几乎不会在同一分区。” ,这项新成果的合作者还有哥伦比亚大学的Alexandr Andoni,普林斯顿大学的Assaf Naor,多伦多大学的Aleksandar Nikolov和哥伦比亚大学的Erik Waingarten。

历年来,计算机科学家已经提出了各种分区算法。
对于低维数据(每个点仅由几个值定义,例如牧场中奶牛的位置),算法通过创建“Voronoi图”来精确地解决近邻问题。
对于更高维数据(每个点可以由数百或数千个值定义),Voronoi图计算复杂度过高。因此,计算机科学家使用一种称为“局部敏感散列(LSH)”的方法绘制分区,这一方法最初由Indyk和Rajeev Motwani于1998年定义。
LSH算法随机绘制分区,它们保证你会找到一个在实际最近邻点某个固定距离范围内的点,而不是找到一个精确的最近邻点,这使得它们运行得更快但准确度也更低 。 (你可以认为这就像Netflix一样,会给你一个足够好的电影推荐,但不是最好的。)
自20世纪90年代末以来,计算机科学家已经提出了LSH算法,该算法为特定距离度量的最近邻问题提供近似解。但其往往不具有普适性,这意味着为一个距离度量开发的算法不能应用于其他度量。
“对于一些非常具体的重要案例,你可以获得欧几里德距离或曼哈顿距离的非常有效的算法。但是我们没有一种能够在大规模不同的距离度量上通用的算法技术,“Indyk说。
由于针对一个距离测度开发的算法无法在其他测度使用,计算机科学家开发了一种变通策略。通过一个称为“嵌入”的过程,他们将一个无法处理的距离测度叠加到一个已有良好处理算法的距离测度上。
但是,测度之间的拟合通常是不精确的(就像圆形孔配上方形钉)。在某些情况下,嵌入是根本不可能的。我们需要的其实是一种解决近邻问题的通用方法。
棘手问题
在这项新工作中,计算机科学家们开始停止寻求特定的最近邻算法。 相反,他们提出了一个更一般化的问题:对于某种距离测度,是什么使得我们无法找到一个良好的最近邻算法?
他们认为,上述问题的答案与寻找最近邻点的一个困难之处有关——“扩展图(expander graph)”。
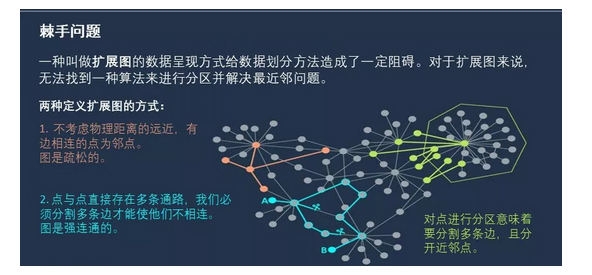
扩展图是一种特定类型的图——由边连接的点集合,有自己的距离度量。 图上两点之间的距离是从一个点到另一个点需要遍历的最小边数。
可以想象一个代表Facebook上人们之间联系的图,例如,人与人之间的距离是他们的亲疏程度。 (如果Julianne Moore有一个朋友,他的朋友是Kevin Bacon的朋友,那么Moore-Bacon的距离就是3。)
扩展图是一种特殊类型的图,它有两个看似矛盾的属性:
-
它是连通的,这意味着你不能在不断开多个边的情况下断开点。
-
但与此同时,大多数点都与很少的其他点相关联。 由于后一特性,大多数点最终都远离彼此(因为低连通性意味着你必须在大多数点之间采取长而迂回的路线)。
这种独特的功能组合 ——良好的连通性,但总的连通边很少 -——导致无法在扩展图上执行快速最近邻搜索算法。 无法执行的原因是,任何在扩展图上划分点的操作都可能将近邻点彼此分开。
“任何将扩展图上的点分成两部分的方法都会断开多边,分裂许多近邻点,”新作品的合作者Waingarten说。
通用算法
在2016年夏天,Andoni,Nikolov,Razenshteyn和Waingarten都知道扩展图不可能有良好的最近邻算法。
但他们真正想要证明的是,对于许多其他距离度量(那些计算机科学家试图找到好的算法而受到阻碍的度量)来说,良好的最近邻算法也是不可能的。
他们证明这些算法不可能的策略是找到一种方法将扩展图度量嵌入到其他距离度量中。 通过这样做,他们可以确定这些度量具有类似扩展图属性,使其不能找到一个好的算法。
四位计算机科学家前去拜访普林斯顿大学的数学家和计算机科学家Assaf Naor,他之前的研究工作使得他似乎非常适合这个关于扩展图的问题。 他们让他帮忙对嵌入了不同类型的距离度量扩展图进行论证。 Naor迅速给出了回答,但并不是他们一直期待的那个。
“我们带着自己的猜想向Assaf 寻求帮助,但是他证明了相反的结论”Andoni说。
Naor证明了扩展图并不会嵌入一大类称为“赋范空间”的距离度量(包括欧几里德距离和曼哈顿距离之类的距离)。
以Naor的证明为基础,计算机科学家遵循这一逻辑链:如果扩展图没有嵌入到距离度量中,那么良好的分区一定是可能的(因为事实证明,扩展性是良好分区的唯一障碍)。 因此,一个好的最近邻算法也必须是存在的 -——即使计算机科学家还没有找到它。
五位研究人员 (之前提到的四位,再加上Naor) 在去年11月完成的一篇论文中写下了他们的成果,并于4月在网上发布。
论文1原题:
Data-Dependent Hashing via Nonlinear Spectral Gaps
论文1全文:
研究人员跟踪了这篇论文,他们在今年早些时候完成了第二篇论文并于本月在网上发布。 在那篇论文中,他们使用在第一篇论文中获得的信息来找到用于赋范空间的快速最近邻算法。
论文2原题:
Hölder Homeomorphisms and Approximate Nearest Neighbors
论文2全文:
“第一篇文章显示,存在一种方法可以采用一种度量将其划分为二,但没有给出快速做到这一点的方法,”Waingarten说。 “在第二篇论文中,我们说存在一种分割点的方法,并且,这种分割是可以用快速算法来实现的分割。”
总而言之,这些新论文首次在一般情况下重新定义最近邻搜索的高维数据。 计算机科学家现在采用一种通用的方法来寻找最近邻算法,而不是为特定的距离度量设计一次性算法。
“在你关心的任何度量空间中,这是一种设计最近邻搜索算法的规范方法,”Waingarten说。
翻译:Fraya
审校:高飞
编辑:王怡蔺
原文:

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}