阅读:0
听报道

导语
来自芝加哥大学和亚马逊的研究者,针对海量文本资料,将所有词向量分解为性别,阶级和种族三个维度,并通过将不同词向量在这三个维度上的投影来给出该词的性别、阶级和种族属性。本文是对这项工作的解读。
论文题目:
The Geometry of Culture: Analyzing Meaning through Word Embeddings
论文作者:
Austin C. Kozlowski, Matt Taddy, James A. Evans
论文地址:
如你所见,我们生活在一个数字化的世界——社交媒体,在线交易,医疗记录,和电子书,科技的进步推动了数字化文本的发展。同时,伴随着自然语言处理技术的日趋成熟,训练网络上的数字化语料库,探索社会科学领域的问题,也越来越受到关注。
本文将分别介绍词嵌入模型对当前文本,跨越一个世纪的文本和不同文化文本的研究过程和结果,展示其中发现的一些有趣的结论。
研究者采用神经网络技术,在现在的数字化文本上训练词嵌入模型,以文化社会学中的性别、阶级和种族三个维度为例,成功地产生出比现有方法更丰富的社会学观点。
本文将分别介绍词嵌入模型对当前文本,跨越一个世纪的文本和不同文化的文本的分析过程和结果,展示其中发现的一些有趣的结论。
一、不同人群的流行音乐
比较词嵌入模型得到的语义关系,和文化协会测量的调查数据,研究者们发现,词嵌入模型在文化社会学的描述上表现极佳。
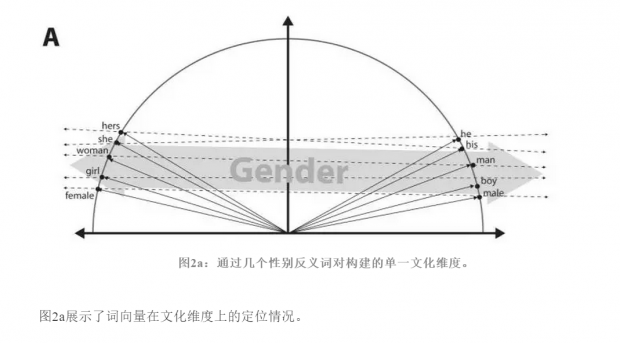
词嵌入表示单词之间的语义关系,是文本的高维矢量空间模型。训练时,语料库中的每一个单词都被表示为空间中的一个向量。共享上下文的单词,位于向量空间中较近的位置;上下文毫不相干的单词,在向量空间中距离也比较远。图1a展示了本文涉及到的部分单词对。

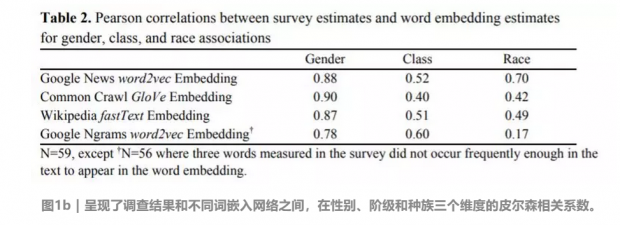
Pearson相关系数(Pearson Correlation Coefficient ):用于衡量两个数据集合是否在一条线上面,是两个变量X和Y之间线性相关的度量,取值范围从-1到+1,其中,1表示正线性相关,0表示无线性相关,-1表示负线性相关 | 维基百科
第一列数据表明,在性别方面,词嵌入模型和真实数据之间表现出高度的相关性;
第二列数据显示,在阶级方面,词嵌入模型也很好地模拟真实的文本资料,但表现效果并不如性别维度上那么好,这种现象可能的原因如下:
(1)在这些调查中,和关于性别的词向量(标准差=20.8)相比,阶级的词向量(SD=23.1)离散程度更大;
(2)数字文本中作者对于阶级联系的意见分歧比性别要大。
(3)文本中存在的阶级联系和被调查者理解的阶级联系之间存在差别;
(4)无论是在词嵌入还是调查中,都存在一定的测量误差。
第三列中,谷歌Ngrams模型里,所有的文本被完全缩减为小写,减少了用于构建种族维度的反义词对的可用数量,可能是导致精度下降的原因。
根据图1b的研究结果,选择谷歌新闻作为词嵌入训练的语料库,研究音乐流派在种族和阶级文化维度中的投影与调查结果之间的差异。
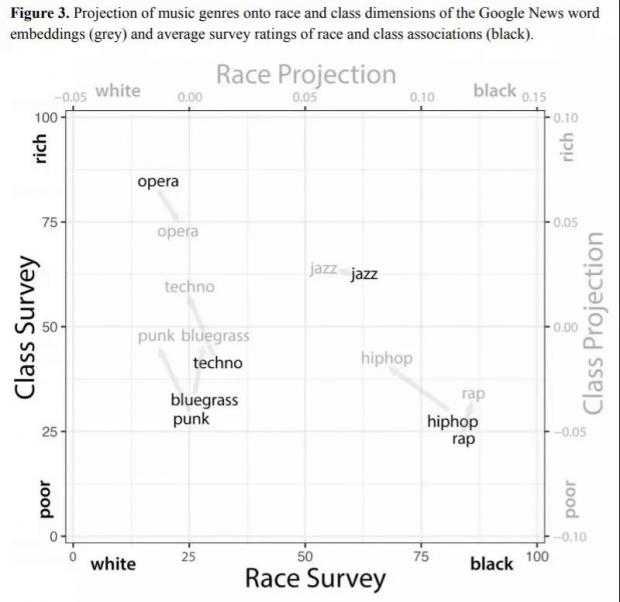
图1c | 爵士、说唱、歌剧、朋克、Techno、嘻哈、蓝草等几种音乐流派,在阶级和种族维度中的位置,黑色表示真实的调查情况,灰色表示词向量的投影。
比较调查结果和词嵌入预测,我们看到词相对位置的惊人相似性。
两种方法中,歌剧都和白人、资产阶级相关联;Techno、朋克和蓝草同样和白人相关联,但明显比歌剧低级。
画面的右端,我们看到,与非洲裔美国人和资产阶级相关的音乐流派是爵士乐,而嘻哈音乐和说唱音乐则倾向于工人阶级。
以上研究表明,词嵌入向量空间的维度能够很好地对应文化意义中的维度。此外,词嵌入模型不仅可以洞察特定文化系统的语义结构,还可以有效地用于分析文化的差异和变化。
二、不断变化的阶级标志
在连续时间段的文本上训练词嵌入模型,可以研究历史上的文化联系是如何发生变化的。
通过分析20世纪美国出版的文本语料库,能够宏观地研究历史上的文化趋势,找到阶级标志缓慢而持久的变化。
在这里,使用余弦相似性来描述词向量和文化维度之间的相关性——计算归一化的词向量在文化维度的正交投影,如果维度在语义上和上下文不相关,则近似正交,余弦相似度值为0;当维度之间的角度从90°偏离6°左右时,表明词向量和维度之间存在有意义的关系。
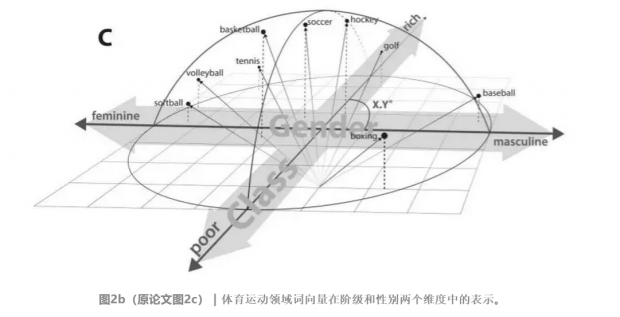
对于多维度的向量空间,词向量可以表示更丰富的文化内涵。图2b中,和体育运动有关的词向量被定位在阶级和性别两个维度上。除了将词向量在不同的文化维度上做正交投影,观察词向量和单个维度之间的相关性,还可以计算这些维度彼此之间的角度,来获取两个维度之间的语义相似性。此外,在多个时间点上进行评估,可以捕获文化维度中相关关系的变化情况。
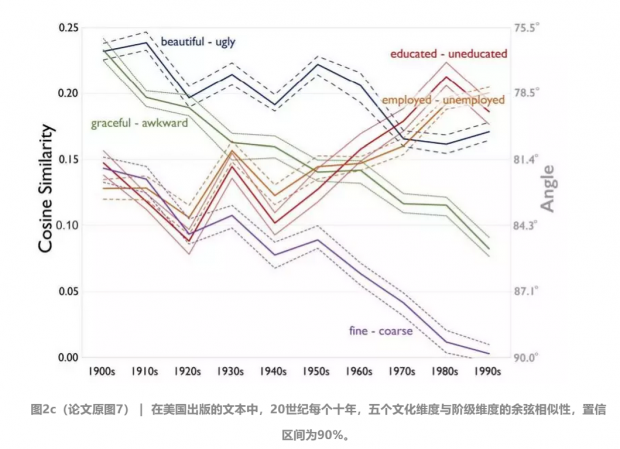
图2c(论文原图7) | 在美国出版的文本中,20世纪每个十年,五个文化维度与阶级维度的余弦相似性,置信区间为90%。
20世纪初,等级和“beautiful-ugly”,“graceful-awkward”等描述外貌,举止的词相关联,美丽和优雅代表着高等级,丑陋、笨拙、粗俗则被标记为低等级。20世纪末,人们开始认为,上层阶级是那些受过教育,拥有工作的人;没有受过教育和失业则成了下层阶级的标志。在100年里,精致和笨拙这些词对,和阶级维度之间逐渐演变成正交关系,外在因素在阶级高低的判断上变得无足轻重,个人素养和能力高低成为更为重要的标准。
通过测试词向量和维度之间的余弦相似性,纵向比较历史上的语料库,词嵌入方法很好地揭示了20世纪美国社会对阶级评价指标的变化情况。
三、新老霸主的阶级群像
利用不同文化背景下产生的文本训练词嵌入模型,可以直接捕获社会群体之间,文化术语的差异。
比较20世纪之交的英美两国的文本,挖掘在这两种社会背景之间阶级标志的细微差别 。

图3a(原论文图8) | 1890-1910年间,英美两国的文本数据被训练后,在阶级维度上的投射(左边为英国,右边为美国),文本高度代表估计值,置信区间为90%。
19世纪末,美国超越英国,成为世界上第一大经济体。这期间,美国辽阔的国土面积和富有活力的劳动力市场是其得以快速发展的重要因素。
在图3a的顶部面板中,展示了1890-1910期间,美国和英国阶级维度上词语位置的比较,揭示了两者社会阶级划分的重要差异。
图左上角显示的“rank”和“nobility”表明,英国比美国具有更强的上层阶级联系。此外,“colonies”(殖民地)处于英国上层阶级的中等程度,美国面板中则不存在。这说明,虽然殖民地本身经常受到殖民主义的剥削,但殖民地依然是大英帝国财富的源泉。
另一方面,美国在殖民地的经济收益却少得多,其与殖民地的联系,更多的是美国本身曾是殖民地的历史背景,而不是在外国殖民地上取得的经济成果。
右上象限展示了美国较高阶级的词汇。 “cotton” (棉花)在美国代表着富有,在英国面板中则不存在,这与历史情况相符。棉花作为美国农业生产的代表,几十年来一直是美国南方经济的支柱。“wilderness”(荒野)一词在美国代表着上层阶级,在英国则代表中等的下层阶级。这种差异反应了荒野在美国历史上的独特地位——荒野意味着富饶的边疆,可以用于农业或采伐木材。随着19世纪末美国第一座国家公园的建立,荒野开始被视为国家的宝藏。
左下象限包含了英国下层阶级的词。可以看到,“commoner”(平民)是英国无产阶级一个很显著的标志,但在美国,这一身份更加中立。结合英国“nobility”和“rank”极高的评级,可以看出,英国社会等级和阶级之间的对应关系比美国强的多。
在美国,任何社会阶层的人都可以想象,自己像流行的的白手起家的小说那样,获得经济上的成功。这种平等主义框架,在 “worker” 和 “farmer” 的阶级联系上也有体现,在英国,这两种群体都被标记为下层阶级,在美国则不然。
尽管如此,美国也不是完全存在着平等主义倾向的。比如,在种族界限上,“negro”(黑人)在美国处于极低的社会阶层,但在英国的情况要好得多。种族是美国下层阶级尖锐而富有决定性的标志。
通过呈现19世纪末20世纪初,词向量在美英两国阶级维度上的位置,词嵌入模型很好地揭示了两国之间的社会差异,也高度符合该时期真实的历史情况。
四、小结
在本文中,研究者提出的现代词嵌入模型,特别是使用Word2vec产生的模型,是分析文化类别和关联的有效手段。文中提供了实证,论述了如何利用词嵌入模型,探索一个给定的文化系统内词与词之间的关系,以及如何在多个文化之间进行密切的比较。本文只是利用词嵌入模型进行文化分析的小范围应用,该模型的全部应用范围远远超过本文范畴。
这项研究结果也表明,词嵌入模型在捕捉大数据文本中复杂的文化关系上,达到了之前方法无法企及的程度。
作者:尚奇奇
编辑:王怡蔺
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号