
导语
图神经网络(GNN)架构在2018年取得了很多突破,但对其效果的评价准存在一定争议。而上最近的一项研究,揭露了现有图网络效果评价标准的缺陷,并提出了更为合理、全面的评价方案。
图(graph)中的半监督节点分类(Semi-supervised node classification)是图挖掘的一个基本问题,最近提出的图神经网络(GNN)已经在这个任务上取得了无可比拟的成果。由于其巨大的成功,GNN引起了很多关注,并且已经提出了许多新颖的架构。比如,今年6月DeepMind提出能够因果推理的图网络,并提供了开源的图网络库。
但是,近日发表在的一个研究表明:现有的GNN模型评估策略存在严重缺陷,比如:使用相同数据集的相同训练/验证/测试分割,或者在训练过程中进行重大更改(例如,早期停止策略(early stoping criteria)),这样对不同体系架构的比较是不公平的。
论文题目:
Pitfalls of Graph Neural Network Evaluation
论文地址:
因此研究者对四个出色的GNN模型进行了全面的实证评估,并且发现对数据采用不同的分割方式会导致模型的排名显著不同。更重要的是,研究结果表明,如果超参数(hyperparameters)和训练程序适用于所有模型,那么简单的GNN架构能够胜过更复杂的架构。
为什么性能无法评估?
图上的半监督节点分类是图挖掘中的经典问题,其应用范围从电子商务到计算生物学。最近提出的图神经网络架构在这项任务上取得了前所未有的成果,并显着提升了现有技术水平。尽管取得了巨大的成功,但由于实证评估过程的某些问题,我们无法准确判断正在取得的进展。部分原因是现在的评估实验大多是复制早期的标准实验设置。
首先,许多提出的模型都采用了Yang等人的三个数据集(CORA,CiteSeer和PubMed),并且在相同的训练/验证/测试分割上进行的,这样的实验设置其实最利于过拟合,因为这些模型最能克服数据集的分割,找到具有最佳泛化属性的模型。
其次,在评估新模型的性能时,人们经常使用与基准的过程完全不同的训练过程,这使得难以确定改进的性能是来自(a)新模型的优越架构,还是(b)更好地调整了训练过程和/或超参数配置,这对新模型的评估是不利的。
在该研究中,研究者解决了这些问题,并对四个主要GNN架构(GCN、MoNet、GraphSage、GAT)在直推式半监督节点分类任务(transductive semi-supervised node classification task)中的表现进行了全面的实验评估。
在该研究的评估中,主要关注了两个方面:对所有模型使用标准化训练过程和超参数选择。在这种情况下,性能差异可以归因于模型架构的差异,而不是其他因素。其次,该研究在4个著名的引文网络数据集上进行实验,以及另外引入了4个新的数据集。对于每个数据集,使用100次随机训练/验证/测试分割,并且为每个分割执行了20次随机初始化。这样的设置能更准确地评估不同模型的泛化性能,而不是仅仅在一个固定测试集上表现得很好。
对比各种模型
该研究定义的图上的直推式半监督节点分类的问题,和Yang等人的定义相同。 在该研究中比较了以下四种流行的图神经网络架构。
(1)图卷积神经网络(GCN)是通过对谱图卷积(spectral graph convolutions)进行线性近似的早期模型之一。
(2)混合模型网络(MoNet)概括了GCN架构,并允许学习合适的卷积滤波器。
(3)Graph Attention Network(GAT)的创建者提出了一种注意机制,允许在整合期间对邻域中的节点进行不同的加权。
(4)GraphSAGE专注于归纳节点分类,但也可以应用于直推式学习。 该研究从原始论文中考虑了GraphSAGE模型的3种变体,表示为GS-mean,GS-meanpool和GS-maxpool。
所有上述模型的原始论文和实施都考虑了不同的训练过程,包括不同的早期停止策略、学习率衰减、全批次与小批量训练。这种多样化的实验设置使得:很难凭经验确定改进性能背后的驱动因素。因此,在该研究的实验中,研究者对所有模型使用标准化的训练和超参数调整程序,以更公平地比较。
此外,该研究还考虑了四种基准模型。 Logistic回归(LogReg)和多层感知器(MLP)是基于属性的模型,不考虑图结构。另一方面,标签传播(LabelProp)和归一化拉普拉斯标签传播(LabelProp NL)仅考虑图形结构并忽略节点属性。
如何平衡地比较?
实验中的数据集
该研究使用了四个众所周知的引用网络数据集:PubMed、CiteSeer和CORA以及CORA的扩展版本(CORA-Full)。另外还为节点分类任务引入了四个新数据集:Coauthor CS,Coauthor Physics,Amazon Computers和Amazon Photo。对于所有数据集,都构建成了无向图,仅考虑最大的连通部分。
模型设置
该研究保留了原始论文中的模型体系结构,包括层的类型和顺序、激活函数的选择、dropout的放置以及应用L2正则化的选择。还将GAT的head数量固定为8,将MoNet的高斯内核数量固定为2,如各自的论文所述。 所有模型都有2层(输入特征→隐藏层→输出层)。
训练过程
为了更平衡地比较,该研究对所有模型使用相同的训练过程。也就是说,使用相同的优化器(默认参数的Adam),相同的初始化(根据Glorot和Bengio,初始化权重,偏置初始化为零),没有学习率衰减,相同的最大训练迭代次数、早期停止标准、patience和验证频率(显示步骤)。实验中同时优化所有模型参数(GAT的注意力权重,MoNet的内核参数,所有模型的权重矩阵)。在所有情况下,都使用全批量训练(使用每次迭代中使用训练集中的所有节点)。
超参数
最后,该研究对每个模型的超参数选择采用了完全相同的策略。对学习率,隐藏层的大小,L2正则化的强度和丢失概率等都使用广泛的网格搜索来确定。该研究限制随机搜索空间,确保每个模型具有相同给定数量的可训练参数。 对于每个模型,选择在Cora和CiteSeer数据集上实现了最好平均准确度的超参数配置(平均超过100次训练/验证/测试分割和20次随机初始化)。 所选择的性能最佳的配置用于所有后续实验,并列于表4。在所有情况下,该研究在每一类使用20个标记节点作为训练集,30个节点作为验证集,其余作为测试集。

GNN的优越性
表1显示了所有8种模型的平均精度(及其标准差)。数据集平均超过100个分割,每个分割有20个随机初始化。从表中可以观察到,首先,基于GNN的方法(GCN,MoNet,GAT,GraphSAGE)在所有数据集中明显优于所有基准算法(MLP,LogReg,LabelProp,LabelProp NL)。 这与人们的直觉相符,并证实了基于GNN的方法的优越性,结合了结构和属性信息,而不是仅考虑属性或仅结构的方法。
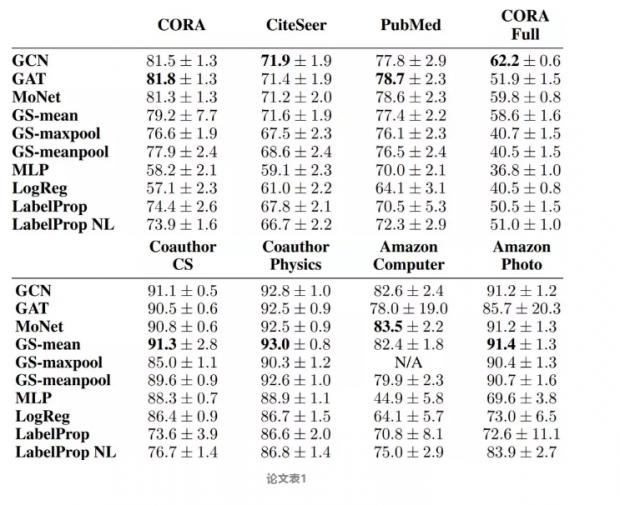
在GNN方法中,没有明显的赢家在所有数据集中占主导地位。实际上,对于8个数据集中的5个,第2和第3个方法的最佳表现与平均得分相差不到1%。在该研究中,对每个数据集(已经平均了超过20个初始值)采用最佳准确度分数100%。然后,将每个模型的得分除以该数,并将每个模型的结果在所有数据集和分割上平均。另外,该研究还根据其性能对算法进行排名(1 = 最佳性能,10 = 最差性能),并计算每个算法中所有数据集和分组的平均排名。最终得分记录在表2a中。
可以观察到:GCN能够在所有模型中实现最佳性能。虽然这一结果似乎令人惊讶,但其他领域也有类似的发现。如果对所有方法同样仔细地执行超参数调整,那么简单的模型通常优于复杂的模型。在未来的工作中,研究者计划进一步研究导致GNN模型性能差异的图的特定属性。

多重分割评判性能
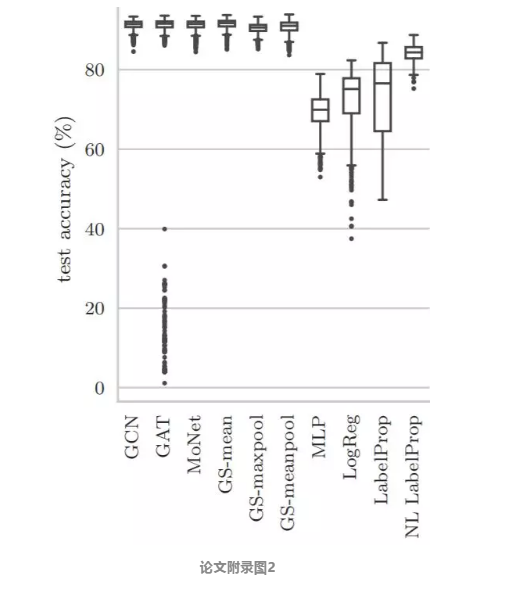
另一个令人惊讶的发现是GAT在Amazon Computers和 Amazon Photo上得分相对较低,结果差异很大。为了研究这种现象,该研究在附录图2中的Amazon Photo数据集上可视化了不同模型所获得的准确度分数。虽然所有GNN模型的中位数彼此非常接近,但GAT将某些权重初始化为极低的分数(低于40%)。虽然这些异常值很少发生(2000次运行中有138次),但是它们显着降低了GAT的平均得分。
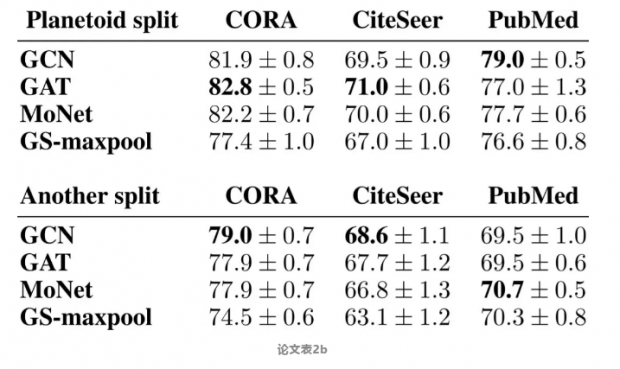
为了演示不同的训练/验证/测试分割对性能的影响,该研究执行以下简单实验。 研究者在Yang的数据集和各自的分割上运行了4个模型。如表2b所示,GAT获得CORA和CiteSeer数据集的最佳分数,GCN获得PubMed的最高分。
但是,如果考虑使用相同训练/验证/测试数据集大小的不同随机分组,则模型的排名完全不同,GCN在CORA和CiteSeer上表现最好,而MoNet在PubMed上获胜。这表明在单个分割中的结果非常脆弱,具有明显的误导性。另外考虑到GNN的预测在小数据扰动下会发生很大的变化,这一点明确证实了基于多重分割的评估策略的必要性。
Take home message
该研究对节点分类任务中的4种最先进的GNN架构进行了实证评估,还引入了4个新的属性图数据集,以及开源的框架,可以对不同的GNN模型进行公平和可重复的比较。 该研究的结果强调了:仅考虑数据的单个训练/验证/测试分割的实验设置的脆弱性。 另外,该研究还惊奇地发现,如果使用相同的超参数选择和训练过程,简单的GCN模型可以胜过更复杂的GNN架构,并且该结果是多个数据分割中的平均值。 希望这些结果可以鼓励未来的工作使用更强大的评估程序。
作者:辛茹月
编辑:杨清怡

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号