阅读:0
听报道

导语
也许你在微博上只是浏览从不发言,也许你已经把所有微博都删掉了,但不要以为这样就可以完全隐身。最近的一项研究表明,仅仅通过用户几位好友的历史推文,就可以在相当高的程度上,预测该用户的后续推文(当然研究者用的是 Twitter 数据)。
自己不发言可以,但你管得了朋友们吗?
一些人在社交网络上有很多好友,但从不发言。他们以为只要保持沉默,就可以避免被陌生人窥探、被大数据捕捉分析。这种想法太乐观了。
2019年1月,一篇发表在 Nature Human Behaviour 的论文发现,仅仅通过分析线上好友的推文数据,特别是其中的互动,就有可能预测一个人在社交媒体上未来的行为。
论文题目:Information flow reveals prediction limits in online social activity
论文地址:
论文作者 Bagrow,Liu 和 Mitchell 来自美国佛蒙特大学佛蒙特复杂系统中心。通过分析上万名 Twitter 用户及其好友的数据,研究者发现:对用户行为的预测准确率存在上限(64%),不过仅仅利用好友们的推文数据,就可以达到预测上限的95%。
这意味着即使你从不发推文,但通过分析你的好友,就能预测出你是怎样的人。而且如果朋友在推文中@了你,或者你在朋友推文下面有互动留言,那么预测会更准确!
甚至,只需要使用9个好友的推文数据来做分析,对你下一条推文做预测,就比用你个人历史推文数据来预测还要准确!
删号一了百了?好友们还记着你
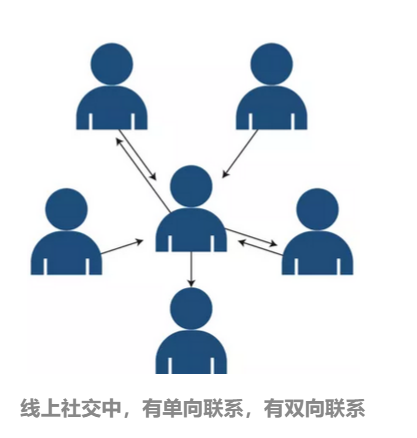
在 Twitter、微博、Facebook等社交媒体中,用户之间通过评论、回复和@等方式互动。如上图所示,有一些是单向的行为,有些是双向的互动。大量的个人信息就隐藏其中。
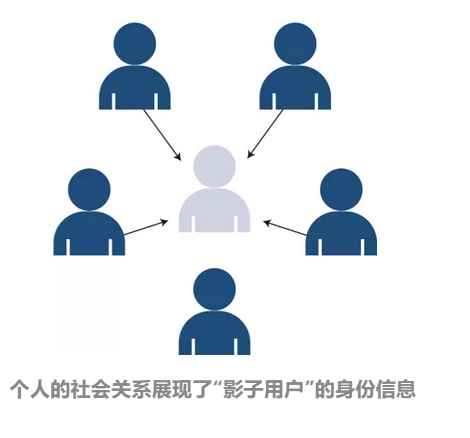
虽然用户随时可以选择离开一个社交网络,并且删除所有的个人信息,成为一个“影子用户”,但是曾经好友们写下的帖子仍然会保留,除非好友们也把推文全部删除。
即使你把个人主页删得空空如也,完全弃用,通过你好友们的推文,以及其中你们的互动,依然可以推测出你的特征属性。
研究者以927个用户为研究对象,找出分别与他们每个人最常联系的14位好友,从而构建起包含13905名 Twitter 用户和30852700条公开推文的数据集。
研究者们构建了927个小社交网络,每个社交网络上有15个节点。他们首先计算了推文内容的不确定性(用信息熵衡量),再换算为用户发帖行为的可预测性(predictability),从而量化分析“用户推文可预测性”及其影响因素。
这里的可预测性,并非计算机的预测准确率,而指的是算法预测能力的上限。如果可预测性是50%,那意味着使用最好的算法来做预测,准确度最高能达到50%。
研究一个人,8位好友数据就够了
研究者使用了三种数据分别做研究:
只使用某个用户的推文数据
只使用某个用户的好友的推文数据
同时使用某个用户的推文数据和该用户的好友的推文数据
整体来看,使用越多的好友数据,用户未来行为的可预测性越高。
如果只选取用户自身的推文数据,则用户推文的平均可预测性是53.8%,即图中的黑色基准线。
如蓝色线表示,当同时使用某用户自身推文数据和好友推文数据进行预测时,该用户推文的可预测性最高,可以达到60%左右。而且随着采样好友数量的增加,可预测性会缓慢增强。
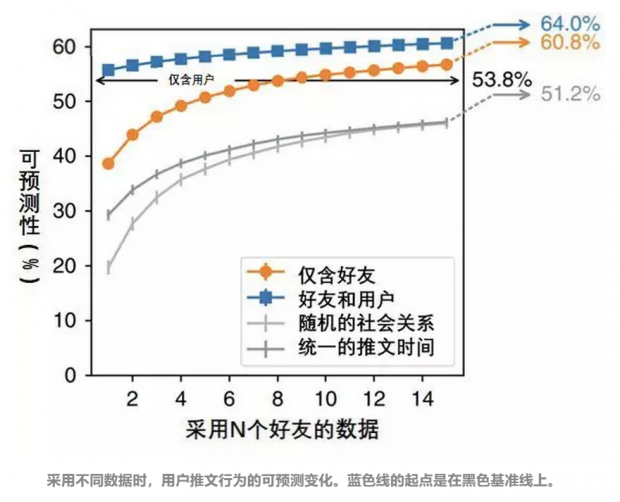
但如橙色线所示,即使仅仅基于好友推文数据,计算出来用户推文的可预测性,也已经高于随机社交网络关系(浅灰)、特定推文时刻(深灰)这两种控制条件。这意味着,用户好友推文数据中,蕴含着大量可供预测用户行为特征的有效信息。
如果选用包含某位用户8位好友的数据,那么该用户推文的可预测性可以达到53.8%的对比基准线。而如果使用某用户9位以上好友的数据,则该用户推文的可预测性会超过基准线。
这意味着,即使你的推文列表空空如也,你的好友们一样会暴露你的特征信息、推文习惯,而且8个好友就够了!好友推文中蕴含的与你有关的信息,可能比你自己推文列表中的个人信息还要多。
用户推文可预测性存在上限
再高明的预测手段,都无法做100%准确的预测。对用户来说,他们未来推文的可预测性存在极限。

当好友数量非常多,趋于无穷时,仅仅基于好友推文数据的“用户推文可预测性”会有60.8%的上限,而基于用户和好友推文数据的“用户推文可预测性”,上限是64%。
当然人不会有无穷多的朋友,认知上限决定了一个人最多只能拥有150位联系紧密的朋友。基于用户150位好友的推文数据,“用户推文可预测性”可以达到60.3%,如果加上用户本人的历史推文数据,可预测性将会达到63.5%。
根据邓巴数理论(Dunbar's number),一个人的熟人数量上限是150人,本研究中选取了其中最常联系的14个好友,实际研究时把用户自身也作为一个好友处理。
大V好友,反而不会暴露朋友信息?
不过这项研究表明,如果你有一个大 V 朋友,那 Ta 泄露你个人信息的风险,比其他普通朋友泄露你信息的风险要低。
原因可能是,对于用户 A 来说,他最常联系的14位朋友中有一位是大 V,但对这位大 V 而言,用户 A 未必是他的14位最常联系的好友之一。
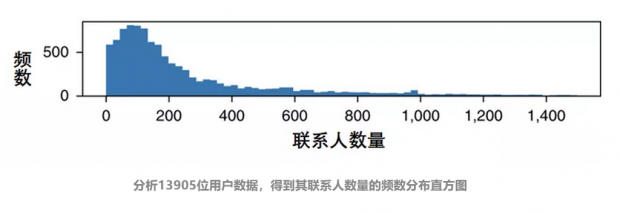
这927个社交网络的13905人,有各种各样的社交地位:他们中大部分是有一两百位联系人的普通用户,而少量的社交达人,可以有上千个联系人。
如果只选取用户一位好友的数据,能否预测该用户的行为呢?
研究者在研究这927个社交网络的中心用户时发现,在仅仅选取用户某一位好友的推文数据作为依据时,该用户行为可预测性有30%左右。但是选取不同的好友数据,对“用户推文可预测性”的影响很大。
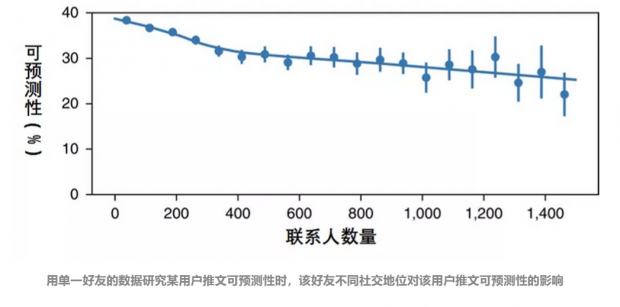
如果选取的这位好友是社交达人,联系人数量很多,那么计算出来的“用户推文可预测性”就很低。如果选取的这位用户好友是普通用户,只有一两百人,甚至几十人时,计算出来的“用户推文可预测性”就很高。
其实这一点很容易理解,如果你的某一位好友本身是社交达人,那 Ta 投放在你身上的注意力一般不会太多,你在 Ta 的推文中不会经常出现。所以,大V 好友反而不会暴露你的个人信息。
如果互联网的数据打通也许将再无隐私可言
每个人都在社交网络上生活,在享受与朋友沟通、获取信息的便利的同时,也在承担着隐私泄露的风险。
虽然在这项研究中,根据历史推文内容预测后续推文,可预测性有60%左右的上限,但研究者对具体推文信息的研究目前还不够深。根据社交网络上好友的属性,科学家们已经可以比较准确地猜测出用户的宗教信仰、朋友关系、常去地点,甚至是性取向。所以这项研究还有更进一步的空间。
目前,几位研究者正在谋求从 Facebook 和 Google 等不同平台上获得用户的公开推文信息,他们未来的计划是,通过好友推文内容,从多个维度上构建起用户的特征,并提供实际预测的案例。
如果能够同时获得某一用户在多个社交媒体平台上的数据,那么建立起一个人完整清晰的网络形象,也不再是难事。
一面微博,一面朋友圈,但如果互联网公司们的数据打通,那么,你将会以怎样的形象出现在朋友面前呢?
细思极恐。

参考资料:
作者:Elena
审校:李周园
编辑:杨清怡
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}