阅读:0
听报道
导语
我们知道,不同的生成机制产生不同的对象,不同的对象相互作用产生复杂的交互行为。然而,当我们观察到行为时,能否执果索因,找到它们的根源呢?这个问题目前仍然是科学研究中最基本的挑战之一。在 Nature 新子刊《机器智能》(Nature Machine Intelligence)中,就有一篇论文研究了算法生成模型的因果反卷积,提出了开创性的概念和算法框架,有助于进一步研究如何教机器理解因果关系。
论文原题:
Causal deconvolution by algorithmic generative models
论文地址:
当前的机器学习方法和深度学习方法缺乏处理归纳推理、因果推理和过程解释的能力。贝叶斯网络之父、人工智能领域的先驱 Judea Pearl 批判,现有的机器学习和深度学习基于盲目的统计学模型,所有的成就只不过是曲线拟合。
曲线拟合:是指选择适当的曲线类型来拟合观察数据,并用拟合的曲线分析两变量间的关系,这是一种关联关系。
Pearl 认为,人工智能已经在近十几年的快速发展中陷入了僵局,人工智能如何进一步发展,关键在于用因果推理取代关联推理,教会机器理解问题背后的根源。

执果索因,告别曲线拟合
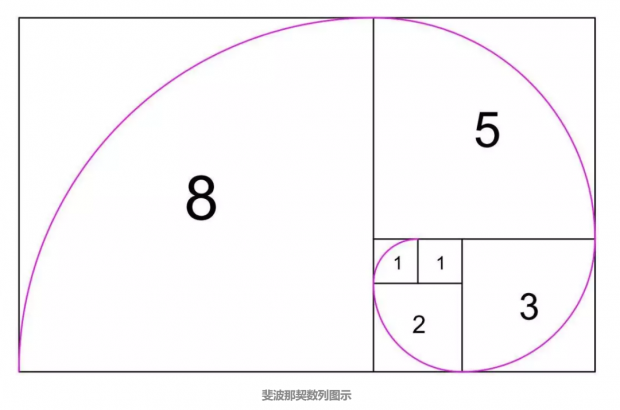
我们先来看一个简单的执果索因的例子。有这样一组数字:1 1 2 3 5 8 13 21...,这些数字是按什么规律产生的呢?是的,很明显这是斐波那契数列,后一个数等于前两个数之和。依次类推下去,你可以知道下一个数字是什么。这个问题对于有一定经验的人来说是轻而易举的。

这样的问题对于机器来说同样是一个艰巨的挑战——怎样才能使机器具有执果索因的能力呢?
这篇论文向我们介绍了一种通用的、无监督且无参数的面向模型的方法。它基于开创性的概念和算法概率原理,将观察分解为最有可能的算法生成模型。这个方法使用基于扰动的因果微积分来获得模型表示,无论结果对象是位串、时空演化图、图像还是网络,它都能够对相互作用机制进行反卷积。
这篇论文的贡献主要体现在概念和算法框架方面,但也提供了一些数值实验来评估该方法从离散动力系统产生的数据中提取模型的能力。(如元胞自动机和复杂网络)这些技术有助于进一步研究因果推理问题,从而补充面向统计的方法。
还记得前面说到的识别二进制位串的生成机制的问题吗?论文对这个问题进行数值实验。结果如下图所示,图a、b是复杂度估计图。算法对每个二进制位进行复杂度估计,统计估计结果,可以看到蓝色片段每一位二进制位的复杂度相似,它们是由同一个程序生成的;红色片段随机性很大,是由另一个程序生成的。
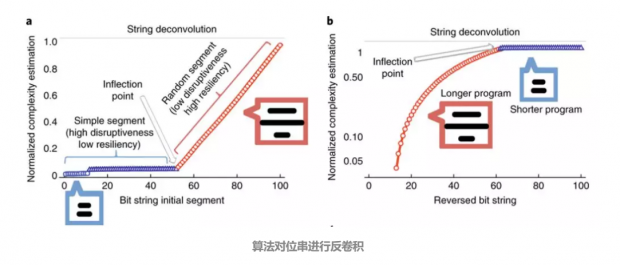
图a和图b的结果顺序相反,这体现了算法可以根据观察获得一个因果顺序,那么反过来,在生成程序上增加一个顺序设置项,就可以按照正确的顺序生成位串。
算法能应用于元胞自动机和复杂网络数据
论文所提出的算法能处理元胞自动机产生的数据,论文中呈现了算法通过反卷积提取模型的能力。
元胞自动机数据处理
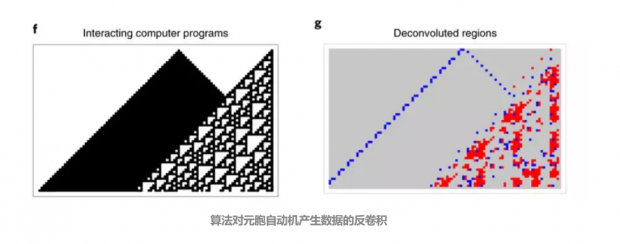
如下图所示,图f是一个非常简单的相互作用的例子,一个程序支配另一个程序,每个程序具有不同的生成机制。图g是对图f进行反卷积的结果,每个像素通过翻转其值并相应地评估其对原始对象的贡献:灰色代表没有贡献,蓝色代表低贡献,红色代表高贡献(它的存在有助于增加算法的随机性)。
图网络数据处理
算法还能处理图网络数据,比如通过反卷积对图网络进行聚类。聚类通常可以被视为根据一些感兴趣的度量来解决具有基础树结构的问题。考虑最佳聚类的一种方法是在某个深度水平上发现树结构,当这些对象具有相似的因果机制时,叶子节点彼此也更相似,可以组成同一个类。下图呈现了算法对图网络数据进行聚类的例子。
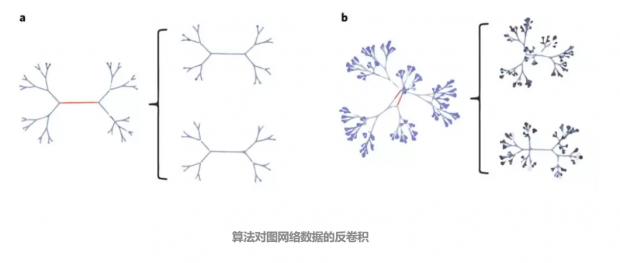
通过最小化图的算法信息损失,对图进行强制反卷积,从而最大化所得组件的因果相似性(因此这里是进行因果聚类)。图a呈现了6元树(每个节点不超过6个子节点的有根树)的组件以及经过一次反卷积算法迭代后得到的图,图b则呈现了10元树的结果,结果符合预期。
图网络的因果反卷积算法
要使机器具有与人类相似的解决问题的能力,那么机器就不应该每次都从头开始解决新问题。这篇论文所提出的方法是,利用大量能够解释小块数据的小型计算机程序,预先计算和存储通用分布的估计。每个计算机程序代表一个相应数据块的离散生成模型,当按顺序组合时,代表一个完整的模型。预计算允许实际应用在线性时间内实现,方法是查找一个磁带上的查询表,也就是说,用内存换时间。
论文所提出的反卷积方法,基于算法信息动力学,是一种自下而上的方法,深深依赖于 Solomonoff 的归纳推理。算法信息动力学的核心是以计算机程序的形式寻找算法候选模型的过程,这种程序能够解释观测数据的片段,并按照相似的生成机制对它们进行分组。通过扰动分析以各种可能的方式分解较大的数据,以产生每一片数据的计算机程序集的长度作为指导。

以图网络为例,定义G为图,E=E(G)为G的边集合,G\e为从G中删除边e后得到的图,C(G)为G的算法复杂度估计,则e对G的“信息贡献”用I(G,e)=C(G)-C(G\e)得到。这里,我们希望找到F⊆E,使得F中的边的移除将G分解为N个组件,并且最小化所有边子集之间的信息损失,也就是说,对于所有S⊆E,I(G,F)≤I(G,S)。
主要算法如上图所示,该算法使我们得到满足上述条件的子图(V,E\F)。然后由F=E(G)\E(DECONVOLVE(G,N))得到所需的边子集。
该算法需要的唯一参数是N,即将对象分解成的最大组件数。然而,有一种自然的方法可以最小化候选生成机制的长度之和,找到最佳的终止步骤和最大组件数量N,从而使算法不需要任何参数。如下图所示图网络反卷积例子,N为4。论文补充资料中提供了这种确定最佳组件数量的算法的伪代码。
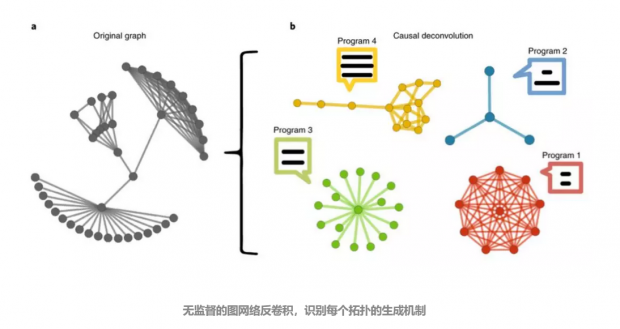
论文中将组件的算法复杂度和它们的相对大小作为判断候生成机制的依据。很容易困惑的一点是,如果组件s1和s2具有相同的算法复杂度,这并不意味着s1和s2是由完全相同的生成机制生成的。
论文中解释说,由于一个对象的算法概率是随着随机性的增加而指数衰减的,因此一个对象的随机性越小,它的潜在机制就越有可能是相同的。短程序的随机性要比长程序小得多。
举个例子,在完全连通图的极端情况下,我们看到由Kn表示的完全图,其节点数为n,作为n的函数,算法复杂度c+log [n]增长最小,其中c是最短的计算机程序的长度。如果|C(s1)-C(s2)|≈log [n],且s1和s2是连通图,那么s1和s2有很大概率是同一个算法生成的。相反,如果|C(s1)-C(s2)|偏离log [n],那么使用相同算法生成的可能性将以指数衰减。
因此,将组件的算法复杂度和它们的相对大小作为判断候生成机制的依据是合理的。
为机器学习插上因果推理的翅膀
这篇论文提出的方法是面向模型的、通用的、无监督且无参数的,不同于那些来自经典信息理论和统计学领域的估计算法复杂度的方法,它促进了因果推理和扰动分析技术的使用,补充了从可计算性理论和算法复杂性理论中得出的通用原则。
而且,这篇论文提出的方法是准确、敏感的,即使在简化形式上进行单像素扰动,结果也能表现出差异性。这意味着还有很大的改进空间,并且能够在这一原理的基础上进一步探索其它应用与其它领域。

这个方法有助于进一步研究如何教机器理解因果关系,不同于机器学习中的传统统计方法。正如 Pearl 最近所呼吁的,在算法的研究上引入符号计算,并结合在因果推理领域取得的成就(如反事实逻辑和 Pearl 等人提出的扰动分析),以及当前机器学习方法、深度学习方法的力量,这是解决机器学习中因果推理挑战的前进方向。
资料包
论文补充资料下载
https://static-
一个简单的在线实例:
R语言的代码实现:
Wolfram语言的代码实现:
作者:王佳纯
编辑:王怡蔺
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}