阅读:0
听报道
导语:复杂系统要素众多,相互作用复杂,因果关系的推断非常困难,对此有一系列的研究。2012年发表在Science的一篇论文,提出了收敛交叉映射算法,针对复杂生态系统进行因果推断,取得较好效果。本文是对这篇经典论文的解读。
现实中复杂系统中的因果关系,由于其本身的复杂性,往往不能根据领域知识,画出明确的因果图(Directed acyclic graph),从而无法按照 Judea Peral 在《为什么》这本书中提出的基于因果图进行因果推论。
例如判断黄石公园引入狼群是否恢复了生态系统的平衡,要考虑的混杂因素就会有几十项,从天上气候变化,到地上的微生物和真菌的变化,都需要考虑。
生态系统是典型的复杂系统,多种元素,相互作用。针对复杂生态系统,2012年的Science文章提出了收敛交叉映射算法(convergent cross mapping ),本文是对该论文及收敛交叉映射算法的详细介绍。
论文题目:
Detecting Causality in Complex Ecosystems
论文地址:

为什么判断复杂系统中的因果关系很困难
在介绍这篇经典论文之前,先回顾一下之前关于因果推断的相关方法。
计量经济学家格兰杰(Clive Granger,2003 年诺贝尔经济学奖得主)提出了一套因果检测方法(Granger causality test)。格兰杰因果检验是针对时间序列时间,最常用的一种统计方法,从最初在计量经济学中使用,后来进入了生态学、复杂网络等自然科学领域。格兰杰因果检验考察的是两个事件发生的先后顺序,然后假设因一定比果先发生。
但格兰杰因果检验的假设——“原因比结果先发生”——是有问题的,其格兰杰检测只是判断两个事件的发生的先后顺序是否在统计上显著,并不能够判定因果关系。
例如,观测中美两国的股市,如果发现美国股市的暴跌总是比中国股市早零点几秒,于是用格兰杰检验会发现,在任何情况下,使用美国股市的数据都能更精确地预测中国股市的暴跌,因此两者之间有因果关系。但实际上,两国股市的起伏可能是某个突发事件同时引发的,只是由于光纤传递信息的延迟,导致了时间上的先后。
复杂系统的特点之一是存在非线性的相互影响,由此产生相变和混沌现象。具体来说,两个变量在很长一段时间内,看起来是高度相关的,但可能突然就变得毫不相关了。如果没有意识到这一点,就容易根据观察到的局部相关性,判断变量之间存在伪相关关系(spurious correlation)。
下图所示的是存在非线性关系的变量X和Y之间随时间变化的图,图中大部分时间,XY都是高度相关的:
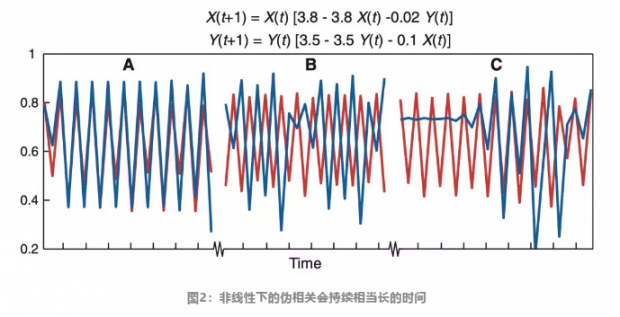
对上图的例子,格兰杰检验就不会判定X和Y之间有因果关系,但根据俩者的微分方程,可以看出俩者之间是存在着因果关系的,因此在该例中,格兰杰检测就没有检出因果关系。
收敛交叉映射算法:复杂生态系统中的因果关系模型
前面说了格兰杰因果检验存在的缺陷,而2012 年这篇 science 文章中提出的新方法“收敛交叉映射算法”,正是针对格兰杰检验进行的改进。
用一句话来概述收敛交叉映射算法就是,如果变量Y的历史数据能够由变量X可靠的推出的程度越高,那么X到Y的因果关系就越强。
举例来说,将包含三个变量典型的洛仑兹系统(canonical Lorenz system)看成是复杂系统的经典案例。其中已知X和Y是互为因果关系的,在三维流形中画出其运动曲线,可以得出下图:
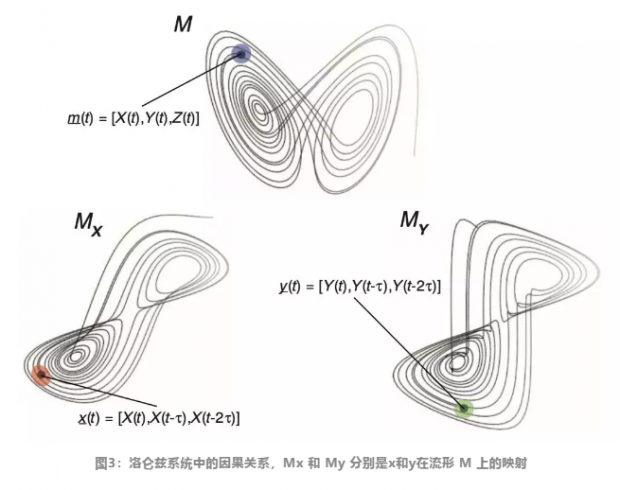
在t时刻,X的数值处在橙色圆圈附近,Y处于绿色圆圈附近,由于X和Y在动力学上是相关的,所以知道X所在的位置能够预测Y所在的位置,反过来也是这样。由于随着时间的流逝,X和Y的轨迹都会变得更加密集,因此,从X或Y能够更加精确的预测Y或X的值,从而可以推出——X和Y之间的因果联系更强了(图中蓝色圆圈部分的曲线密度更大)。
读者可能会问,前文写道可预测不等于因果,这里就需要澄清收敛交叉映射算法的核心词——收敛(convergence)。
首先,收敛交叉映射算法是一个向后看的模型:它考察当前的状态之间的关系,是根据当前的X预测当前的Y,而不是基于当前X的状态能否预测Y未来的值进行判断。
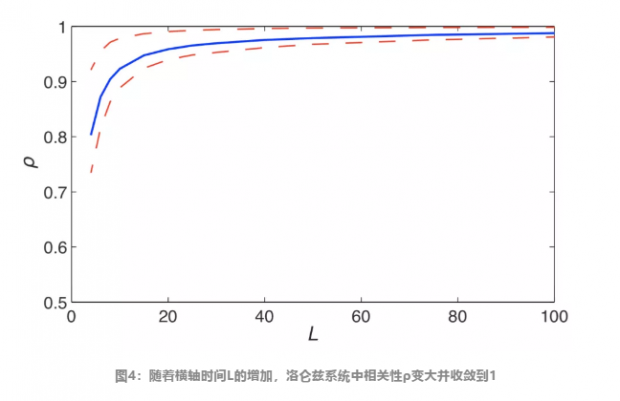
举公鸡打鸣和太阳升起的例子。假设公鸡在小时候,有时半夜鸡叫,有时正午才打鸣,长大后逐渐掌握了太阳升起的时间,打鸣准时了。等公鸡年长,都会根据四季的不同调整打鸣时间了,那时候公鸡就能欺骗收敛交叉映射算法——算法会认为是公鸡打鸣才是太阳升起的原因(因果性存在)。但这显然是荒谬的,由此通过反证法,该例子说明了收敛交叉验证算法能够从相关性之中,找到真正的因果性。
如何区分因果关系的方向和类型?
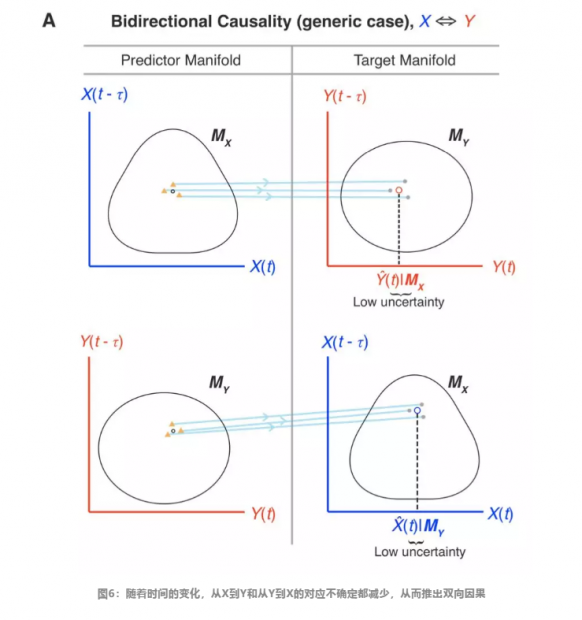
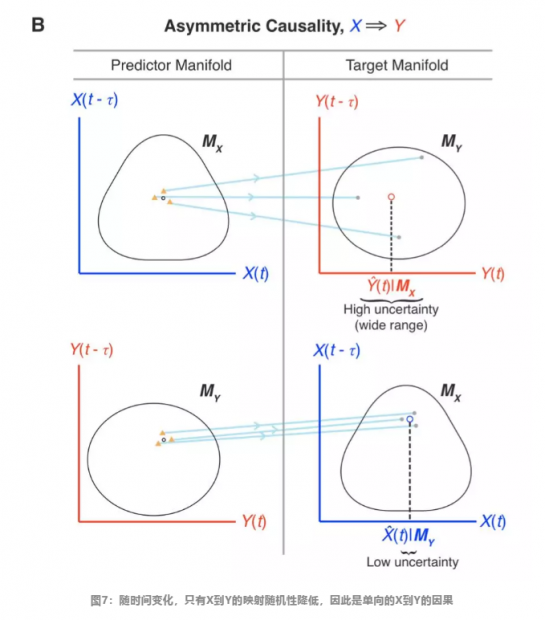
在简单情况下,因果关系可以分为三类:互为因果,单向因果与共同原因。三者在数据上看起来是很难区分的,但使用收敛交叉映射算法,可以将由共同诱因Z导致X和Y发生变化的情况与X导致Y区分开。
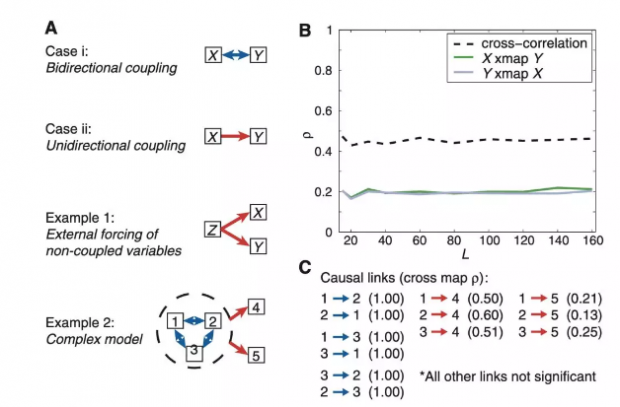
图5:基于渔业数据,用收敛交叉映射算法区分共同因素引起的伪因果
研究者使用真实的渔业数据,做了研究,结果如图所示,左边展示的是三种因果关系的示意图,右边是两种鱼X和Y的数量,由于两个变量的交叉相关性ρ并没有随着时间L变化出现收敛,因此可以排除互为因果,单向因果这两种关系,进而得出是由于共同的第三方因素导致了这两个变量的相关。
收敛交叉映射算法还能区分互为因果与单向因果这两种情况,如下图所示:
更复杂的情况是五个物种组成的生态系统,如下图所示,在该生态系统中,物种1、物种2、物种3相互之间有100%密切的相关性,物种1、物种2、物种3共同作用,分别影响物种4和物种5。
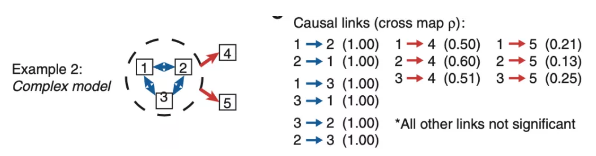
图8:5个物种组成的模拟生态系统中,通过收敛交叉映射算法判断因果关系
如果使用因果图(casual diagram)方法,需要根据预设知识,在模型中给出可能存在因果关系是哪些组。而在缺少预先假设时,例如考察物种2和物种4的相互关系,是无法矫正其他物种带来的影响的。但收敛交叉映射算法就可以在无假设的前提下,判断出因果关系。
因果推断研究助力新一代人工智能
判定因果关系,尤其是在复杂系统和现实环境中,是极其困难的,连诺奖得主提出的格兰杰因果检验,都不能直接检测因果关系,也无法区分单向的与双向的因果关系。因此判断因果关系,要格外地战战兢兢如履薄冰。本文聚焦2012 年 Science 论文,通过和格兰杰因果检验的对比,展示了收敛交叉映射算法在判定因果关系上能力更优。
回顾因果判定方法的发展,如同咬住自己尾巴的蛇:统计模型的最终目的,不是去超越最简单的观察法,而是去模拟人类的因果推断,从而做到小样本下可解释的因果推断,再将其自动化地推广到大数据上。
为了让人工智能更值得被信任,因果推断是充分必要条件。近期,有一系列讨论复杂系统因果推断问题的研究进展,这里举几例:
有了因果推断,就不用担心模型会歧视少数族裔或者女性,因为模型可以自己回答反事实的问题,判断路径相关下的决策是否公平。
论文题目:
PC-Fairness: A Unified Framework for Measuring Causality-based Fairness
论文地址:
不仅可以利用因果推断模型,还可以反过来去判断模型对因果的判断与哪些些因素相关,从而为模型提供可解释性。
论文题目:
Feature relevance quantification in explainable AI: A causality problem
论文地址:
同时,因果模型还可以提升模型在不同领域间的可迁移能力,在无监督下学到领域无关的一致性表征(domain adaptation)。
论文题目:
Deep causal representation learning for unsupervised domain adaptation
论文地址:
因果推断和机器学习,以及更广泛的认知科学,因果涌现的结合,是集智俱乐部会持续关注的话题,如果对该话题下的某个具体子领域或者某个问题感兴趣,或推荐相关经典论文与研究进展,欢迎留言。
作者:郭瑞东
审校:刘培源
编辑:张爽
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}